Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
Здесь есть возможность читать онлайн «Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: СПб., Год выпуска: 2018, ISBN: 2018, Издательство: Питер, Жанр: Программирование, Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Владстон Феррейра Фило Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] обложка книги](/books/389524/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp)
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Издательство:Питер
- Жанр:
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Если вы хотите настроить базу данных, чтобы повысить ее производительность, чрезвычайно важно знать, какие индексы стоит сохранять, а какие — отбрасывать. Если доступ к БД главным образом осуществляется в режиме чтения, а обновляется она редко, может иметь смысл создать больше индексов. Плохая индексация — главная причина замедлений в коммерческих системах. Небрежные системные администраторы зачастую не задаются вопросом, как выполняются типичные запросы, — они просто индексируют произвольные поля, которые, по их мнению, будут способствовать производительности. Этого не стоит делать! Воспользуйтесь «объясняющими» инструментами, чтобы проверить свои запросы и создать индексы только там, где они нужны.
Транзакции
Представим, что скрытный швейцарский банк  не ведет учета денежных переводов: его база данных просто хранит баланс счетов. Предположим, что кто-то хочет перечислить деньги со своего счета на счет друга в том же банке. Две операции должны быть выполнены в базе данных банка — денежную сумму нужно вычесть из одного баланса и прибавить к другому.
не ведет учета денежных переводов: его база данных просто хранит баланс счетов. Предположим, что кто-то хочет перечислить деньги со своего счета на счет друга в том же банке. Две операции должны быть выполнены в базе данных банка — денежную сумму нужно вычесть из одного баланса и прибавить к другому.
Сервер БД обычно позволяет многочисленным клиентам читать и записывать данные одновременно — исполнение операций в последовательном режиме сделало бы любую СУБД слишком медленной. Но вот подвох: если кто-то запросит общий баланс всех счетов после регистрации вычитания, но до соответствующего добавления, то какая-то сумма будет отсутствовать. Или вот вариант похуже: а что, если система окажется обесточена между этими двумя операциями? Когда сервер снова заработает, будет трудно выяснить причину расхождения в данных.
Нам нужны способы, которыми СУБД выполняла бы либо все изменения, входящие в многосоставную операцию, либо сохраняла данные неизменными. С этой целью системы баз данных поддерживают транзакции . Транзакция — список операций, которые должны быть выполнены атомарно [60] Атомарные операции выполняются одноэтапно: они не могут быть выполнены наполовину.
. Транзакции упрощают жизнь программиста: вместо него за обеспечение непротиворечивости данных отвечает СУБД. От программиста только требуется обертывать зависимые операции в соответствующие команды:
START TRANSACTION;
UPDATE vault SET balance = balance + 50 WHERE id=2;
UPDATE vault SET balance = balance — 50 WHERE id=1;
COMMIT;
Запомните: выполнение многосоставных обновлений без транзакций рано или поздно создаст беспорядочные, непредсказуемые и трудные в обнаружении противоречия в ваших данных.
6.2. Нереляционная модель
Реляционные базы данных замечательны, однако у них есть некоторые недостатки. По мере усложнения приложения в его реляционную базу данных приходится добавлять все больше таблиц. Запросы становятся все менее понятными. И, главное, все чаще приходится прибегать к соединениям (JOIN), требующим большого объема вычислений и создающим в системе узкие места.

Рис. 6.5 [61] Любезно предоставлено http://geek-and-poke.com .
Нереляционная модель не использует табличные связи. Она почти никогда не требует объединять информацию из нескольких записей. Поскольку нереляционные СУБД используют языки запросов, отличные от SQL, они также называются базами данных NoSQL.
Документные хранилища
Наиболее известным типом баз данных NoSQL являются документные хранилища . В них записи хранятся в том виде, в котором они необходимы приложению. Рис. 6.6, приведенный ниже, сравнивает табличный и документный способы хранения постов в блоге.
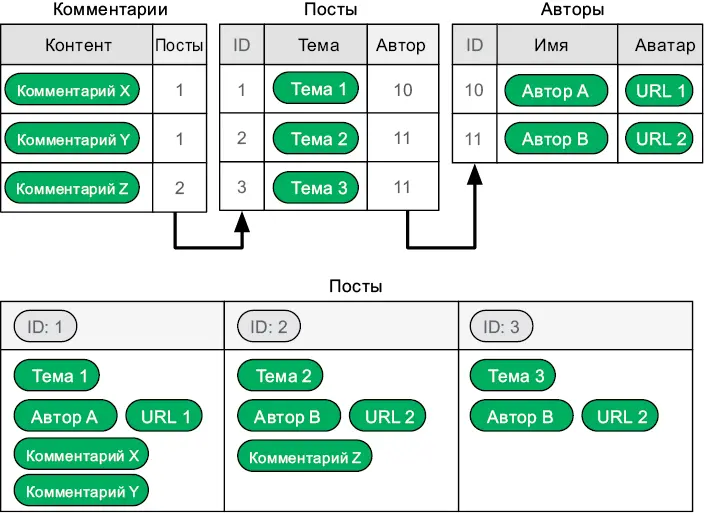
Рис. 6.6.Данные в реляционной модели (вверху) и данные в NoSQL (внизу)
Заметили, что все данные о сообщении копируются в соответствующую ему запись? Нереляционная модель предполагает возможность дублирования информации при необходимости. Однако дублированные данные сложно своевременно обновлять и поддерживать их непротиворечивость. С другой стороны, группируя соответствующие данные, документное хранилище может предложить бо́льшую гибкость:
• вам не нужно соединять строки;
• можно обойтись без фиксированных схем;
• каждая запись может иметь собственное сочетание полей.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]»
Представляем Вашему вниманию похожие книги на «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.