Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
Здесь есть возможность читать онлайн «Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: СПб., Год выпуска: 2018, ISBN: 2018, Издательство: Питер, Жанр: Программирование, Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Владстон Феррейра Фило Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] обложка книги](/books/389524/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp)
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Издательство:Питер
- Жанр:
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
 понимать реляционную модель большинства баз данных;
понимать реляционную модель большинства баз данных;
 использовать гибкость нереляционных баз данных;
использовать гибкость нереляционных баз данных;
 координировать работу компьютеров и распределять между ними ваши данные;
координировать работу компьютеров и распределять между ними ваши данные;
 лучше соотносить информацию с картами при помощи географических баз данных;
лучше соотносить информацию с картами при помощи географических баз данных;
 обмениваться данными с различными системами, используя прием сериализации данных.
обмениваться данными с различными системами, используя прием сериализации данных.
Реляционные базы данных распространены шире, но нереляционные нередко оказываются проще и эффективнее. Базы данных очень разнообразны, и сделать выбор между ними бывает непросто. В этой главе сделан общий обзор различных типов современных СУБД.
Упростив доступ к данным с помощью СУБД, им можно найти хорошее применение. Из невзрачного каменистого клочка земли шахтер способен добыть ценные минералы и металлы. Аналогично мы нередко можем извлечь ценную информацию из имеющихся у нас массивов информации. Этот процесс называется глубинным анализом данных .
Например, большая сеть бакалейных магазинов проанализировала свои данные о продажах и обнаружила, что ее самые склонные к расходам покупатели часто берут сорт сыра с уровнем продаж ниже 200 пунктов. Обычно продукты, продающиеся настолько плохо, снимают с продаж. Анализ данных побудил менеджеров не только оставить сыр, но и выставить его на виду. Это понравилось лучшим покупателям, и они стали возвращаться чаще. Чтобы суметь сделать такой умный ход, сети бакалейных магазинов потребовалось хорошо организовать свои данные в СУБД.
6.1. Реляционная модель
Появление реляционной модели в конце 1960-х стало огромным рывком в управлении информацией. Реляционные базы данных помогают избегать дублирования информации и противоречий. Большинство СУБД, которые используются сегодня, являются реляционными.
В реляционной модели данные разделены на таблицы . Таблица — это нечто вроде матрицы или листа Excel. Каждая запись в ней является строкой. Столбцы — различные свойства записей. Обычно столбцы определяют типы хранимых в них данных. Столбцы могут также определять другие ограничения: обязательно ли строка должна иметь в этом столбце значение, должно ли оно быть уникальным по всем строкам в таблице и т. д.
Столбцы обычно называются полями . Если столбец допускает только целые числа, то мы говорим, что это целочисленное поле . Разные таблицы используют разные типы полей. Организация таблицы базы данных задается ее полями и ограничениями, которые те налагают. Такая комбинация полей и ограничений называется схемой таблицы.
Все записи — строки, и СУБД не примет новую строку, если та нарушает схему таблицы. В этом состоит большой недостаток реляционной модели. Когда характеристики данных значительно варьируются, подгонка их к фиксированной схеме может создать много хлопот. Но если вы работаете с данными однородной структуры, то фиксированная схема гарантирует, что все они будут допустимыми.
Отношения
Представим базу данных счетов-фактур, которая содержится в единственной таблице. По каждому счету мы должны хранить информацию о заказе и клиенте. Когда в базе данных хранится несколько счетов, относящихся к одному клиенту, информация повторяется (рис. 6.1).
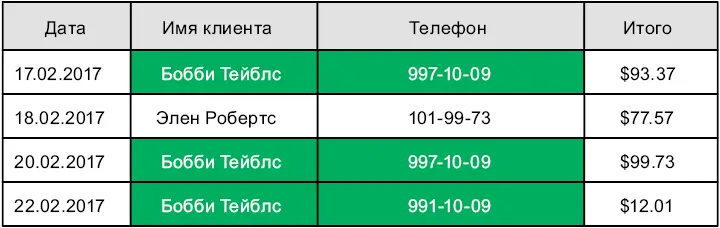
Рис. 6.1.Данные о счетах-фактурах, хранящиеся в единственной таблице
Повторяющейся информацией трудно управлять, и ее сложно обновлять. Чтобы избежать таких сложностей, реляционная модель разбивает связанную информацию на разные таблицы. Например, разделим наши данные о счетах-фактурах на две таблицы — «Заказы» и «Клиенты» — и сделаем так, чтобы каждая строка в первой таблице ссылалась на строку во второй (рис. 6.2).
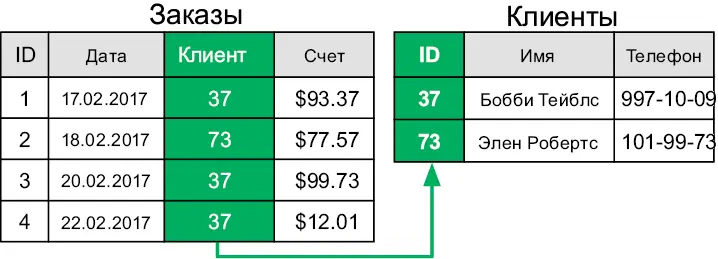
Рис. 6.2.Связи между строками позволяют избежать дублирования данных
За счет связывания между собой данных из различных таблиц один клиент может быть частью многих заказов, а дублирования данных при этом не случится. Для поддержки связей каждая таблица имеет специальное идентификационное поле, или ID. Мы используем значения ID для ссылки на конкретную строку в таблице. Эти значения должны быть уникальными. Поле ID таблицы также называется ее первичным ключом . Поле со ссылками на ID других строк называется внешним ключом .
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]»
Представляем Вашему вниманию похожие книги на «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.