М. Сидоров - Вступ до інженерії програмного забезпечення
Здесь есть возможность читать онлайн «М. Сидоров - Вступ до інженерії програмного забезпечення» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Жанр: Программирование, на украинском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Вступ до інженерії програмного забезпечення
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:978-966-598-626-3
- Рейтинг книги:2.5 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Вступ до інженерії програмного забезпечення: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Вступ до інженерії програмного забезпечення»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
М. О. Сидоров
ВСТУП ДО ІНЖЕНЕРІЇ ПРОГРАМНОГО ЗАБЕЗПЕЧЕННЯ
Курс лекцій Київ
Видавництво Національного авіаційного університету «НАУ-друк» 2010
УДК 004.4(042.4) ББК з 973.20-018.2я7 С 347
Рецензент: S.
канд.фіз.-мат.наук (Інститут програмних систем HAH України); В,
канд.фіз.-мат.наук (Інститут програмних систем HAH України);
канд.техн. наук, доц. (Національний авіаційний університет)
Затверджено методично-редакційною радою Національного авіаційного університету (протокол № 14 від 03.07.2008p.). Сидоров М. О.
С 347 Вступ до інженерії програмного забезпечення : курс лекцій / М.О.Сидоров. - К.: Вид-во Нац. авіац. ун-ту «НАУ-друк», 2010. -112 с.
ISBN 978-966-598-626-3
У курсі лекцій викладено основні положення інженерії програмного забезпечення.
Для студентів напряму 6.050103 "Програмна інженерія".
УДК 004.4(042.4) ББК з 973.20-018.2я7
ISBN 978-966-598-266-3 © Сидоров М.О.. 2010
Вступ до інженерії програмного забезпечення — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Вступ до інженерії програмного забезпечення», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
де n - кількість рядків коду, написаних програмістом (LOC); m -час роботи програміста (у людино-годинах). Видно, що чим більше рядків коду, тим вище продуктивність розробника. Проте можна реалізувати одну і ту ж функцію, написавши меншу кількість рядків коду. Одиниця розміру LOC не відображає функціональні властивості коду. Тому, якщо розробник прагне оптимізувати процес розробки задля зменшення трудовитрат На реалізацію проекту, то при використанні LOC як основної одиниці розміру проекту під зменшенням трудовитрат мається на увазі Зменшення кількості рядків коду в програмі, при цьому не оцінюється його функціональність.
Існують також проблеми із застосуванням LOC і в проектах, що використовують декілька мов програмування. Наприклад, 10.000 LOC мови С++, очевидно, не можна порівнювати з 10.000 LOC мови COBOL, а в разі застосування автоматизованих або заснованих на шаблонах візуальних засобів розробки розрахунок LOC тим менш ефективний, ніж більше коду створюється автоматично.
Function Point була введена як альтернатива LOC. Методика аналізу функціональних точок була розроблена А. Дж. Альбректом (A. J. Albrecht) для компанії IBM у середині 70-х років XX ст., коли виникла потреба и підході до оцінювання витрат праці на розробку ПО, який би не залежав від мови і середовища розробки. З 1986 р. просування методики і розробку відповідного стандарту продовжує International Function Point User Group (IFPUG). Ця організація розробила керування програмним забезпеченням на практиці застосування розрахунку функціональних точок (Function Point Counting Practices Manual - FPCPM) і остання версія цього документа (4.1) офіційно визнана ISO як стандарт оцінювання розміру ПЗ.
Методика аналізу FP грунтується на концепції розмежування взаємодії. Суть її полягає в тому, що програма розділяється на класи компонентів ПЗ формату і типу логічних операцій. В основі цього поділу лежить припущення, що область взаємодії програми розділяється на внутрішню - взаємодія компонентів додатка, і зовнішню - взаємодія з іншими застосуваннями.
Відповідно до прийнятого стандарту використовуються п'ять класів компонентів, на яких грунтується аналіз:
- внутрішній логічний файл (Internal Logical File - ILF) — група логічно пов'язаних даних, меж додатка, що знаходяться всередині, і підтримуваних введенням ззовні;
- зовнішній інтерфейсний файл (External Interface File - EIF) -група логічно пов'язаних даних, меж додатка, що знаходяться ззовні, і що є внутрішнім логічним файлом для іншого застосування;
- зовнішнє введення (External Input - EI) - транзакція, в разі виконання якої дані перетинають межу додатка ззовні. Це можуть бути як дані, що отримуються від іншого застосування, так і дані, що вводяться в програму користувачем. Отримувані дані можуть бути командами управління або статичними даними. В останньому випадку може виникнути необхідність відновити внутрішній логічний файл;
- зовнішній вивід (External Output - ЕО) - транзакція, при виконанні якої дані перетинають межу додатка зсередини. З ILF і EIF створюються файли виведення або повідомлення і відправляються іншому застосуванню. Виведення також містить похідні дані, що отримуються з ILF;
- зовнішній запит (External Inquiry -EQ) - транзакція, в разі виконання якої відбувається одночасне введення і виведення. У результаті інформація вертається з одного або більше ILF і EIF, Виведення не містить похідних даних, a ILF не оновлюється.
Класи компонентів оцінюються ПО за складністю і належать до категорії високого, середнього або низького рівня складності. Для транзакцій (ЕІ, ЕО, EQ) рівень визначається ПО за кількістю файлів, на які посилається транзакція (File Types Referenced — FTR) і кількості типів елементів даних (Data Element Types - DET). Для ILF і EIF мають значення типи елементів записів (Record Element Types - RET) і DET. Типи елементів записів - цс підгрупа елементів даних у ILF або EIF. Типи елементів даних - це унікальне, не рекурсивне поле підмножини ILF або EIF. Рівні складності і відповідні ним значення FTR і DET описані в FPCPM.
Наприклад, для ЕI з кількістю FTR від трьох і більше, і DЕТ(від 5 до 15) рівень складності визначається як високий. Далі компоненти розподіляються ПЗ за «ваговими категоріями» залежно від рівня їх складності. Наприклад, ILF середньої складності має значення 10, a EQ високої складності - значення 6. Після цього, робиться розрахунок нескоригованих функціональних точок (Unadjusted Function Point - UFP) ПЗ у відповідній формулі [1]:
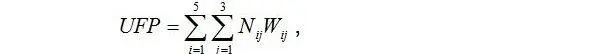 ,
,
Интервал:
Закладка:
Похожие книги на «Вступ до інженерії програмного забезпечення»
Представляем Вашему вниманию похожие книги на «Вступ до інженерії програмного забезпечення» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Вступ до інженерії програмного забезпечення» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.