Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Именно таким образом работают калькуляторы мощности, которые вычисляют необходимый объем данных для тестов. В калькулятор вводится минимальная детектируемая разность в значениях параметров, уровень и ошибок. На выходе будет объем необходимых данных, которые нужно собрать. Закономерность здесь проста – чем меньшую разницу вы хотите детектировать, тем больше данных для этого нужно.
Альтернативой p -значению является доверительный интервал. Это интервал, внутри которого находится наш измеряемый параметр с определенной степенью точности. Обычно используют 95 %-ную вероятность (= 0.05). Если у нас есть два таких доверительных интервала для тестовой и контрольной группы, то по их пересечению можно понять, есть ли между ними отличие. P-значение и доверительные интервалы – это две стороны одной и той же медали. Интервал удобен для представления данных на графиках. Он часто используется в альтернативных методах оценок А/Б-тестов: байесовской статистике и бутстрэпе.
Статистические критерии для p-значений
Как мы уже узнали, p -значение – универсальная метрика тестирования гипотез. Для ее расчета нужно следующее: нулевая гипотеза, статистический критерий, односторонний или двусторонний тест, данные.
Чтобы определить p -значение, вам необходимо знать распределение выбранной статистики (статистического критерия), считая, что нулевая гипотеза верна. Далее с помощью кумулятивной функции распределения cdf (Cumulative Distribution Function) этой статистики мы можем вычислить p-значение, как проиллюстрировано на рисунке (рис. 10.3):
• Левостронний тест: p -значение = cdf( x ).
• Правосторонний тест: p -значение = 1 – cdf( x ).
• Двусторонний тест: p -значение = 2 × min(cdf( x ), 1 – cdf( x )).
Сейчас проще не изобретать велосипед, а пользоваться готовыми калькуляторами в статистических пакетах или программных библиотеках. Важно только выбрать правильный статистический критерий.
Выбор такого критерия зависит от задачи:
• Z-тест для проверки среднего в нормально распределенной величине.
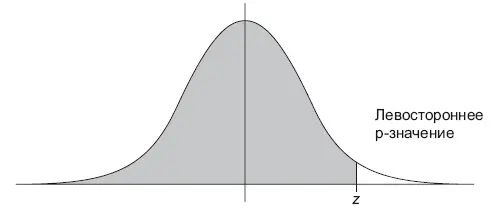
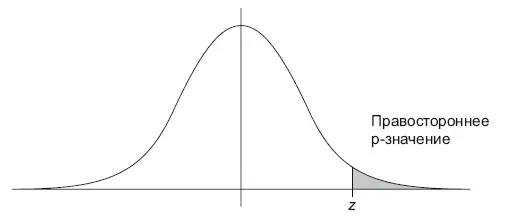
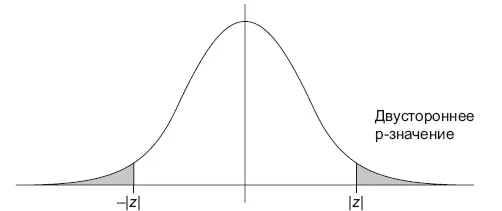
Рис. 10.3.Левосторонний, правосторонний, двусторонний тесты
• T-тест Стьюдента – то же самое, что и z-тест, но для выборок малого объема (t < 100).
• Хи-квадрат Пирсона для категориальных переменных и всяческих биномиальных тестов. Очень удобен для расчета конверсий, например посетителей в покупателей, где нужен биномиальный тест – купил или нет.
• Тест Стьюдента для двух независимо распределенных выборок очень хорошо подходит для нашей задачи с двумя резервуарами или для сравнения средней суммы покупки.
У таких тестов есть одна проблема – они привязаны к распределению. Например, для тестов Стьюдента и z -теста нужны нормально распределенные данные. Форма таких данных формирует «колокол» на гистограмме. Например, распределение средних чеков покупок не образует такого распределения. Конечно, можно их преобразовать логарифмированием и собрать в форму колокола, но часто это неудобно. Первой альтернативой для ненормально распределенных данных являются непараметрические тесты.
Хотя согласно статистическому словарю STATISTICA [78] – непараметрические методы наиболее приемлемы, когда объем выборок мал. Если данных много (например, > 100), то не имеет смысла использовать непараметрические статистики. Дело в том, что когда выборки становятся очень большими, то выборочные средние подчиняются нормальному закону, даже если исходная переменная не является нормальной или измерена с погрешностью. Непараметрические тесты имеют меньшую статистическую мощность (менее чувствительны), чем их параметрические конкуренты, и если важно обнаружить даже слабые отклонения, следует особенно внимательно выбирать статистику критерия.
В нашей задаче с резервуарами можно применить тест Стьюдента для двух независимых выборок. Второй альтернативой является универсальный инструмент – бутстрэп.
Бутстрэп
Это один из самых интересных способов оценки метрик в А/Б-тестах, мы с удовольствием используем его в Retail Rocket для непрерывных параметров, таких как стоимость средней покупки, средняя стоимость товара, средний доход на посетителя сайта (Revenue per Visitor, RPV).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.