Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2. «Колоночные» базы данных – Vertica, Greenplum, ClickHouse; облачные – Google BigQuery, Amazon Redshift.
3. Файловые – Hadoop.
Я не стал включать в список большие энтерпрайзные системы от IBM, Teradata и других вендоров, у них своя ниша, в которой я не работал.
Лично я работал с Microsoft SQL Server в Ozon.ru и Wikimart.ru, Postgres в Ostrovok.ru, Hadoop в Wikimart.ru и Retail Rocket, Clickhouse в Retail Rocket. У меня остались только положительные впечатления об этих технологиях. В последнее время я предпочитаю экономить и пользоваться открытыми технологиями (open-source).
Итак, реляционные базы данных (рис. 6.2) – рабочая лошадка многих бизнесов. Они все еще популярны, несмотря на атаку NoSQL-технологий. Данные в них хранятся в таблицах с колонками и строками, между таблицами есть «отношения», также можно выставлять логику при операциях с полями и т. д. Оптимизация производительности делается с помощью настройки индексов
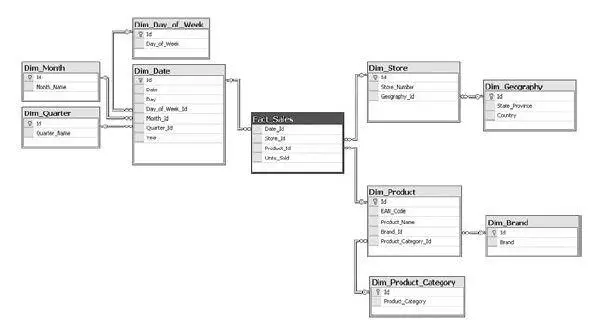
Рис. 6.2.Таблицы реляционной базы данных
и различных хаков, которые у каждого вендора свои. Они популярны, с ними умеют работать множество специалистов. Самое главное, что базы этого типа привнесли в мир, – это язык программирования SQL (Structured Query Language). Этот язык может использоваться как для внесения изменений, так и для получения данных. Минус реляционных баз – низкая производительность, когда идет работа с большими данными. И в Ozon.ru, и в Wikimart.ru я держал данные по статистике посещения сайтов в обычной таблице, а это миллиарды строк. Можно было сходить на обед, пока считался нужный запрос.
На помощь реляционным базам данных, в которых данные хранятся построчно [35], пришли колоночные базы. И совершили революцию. Вот пример таблицы реляционной базы (табл. 6.1).
Таблица 6.1. Пример данных реляционной таблицы
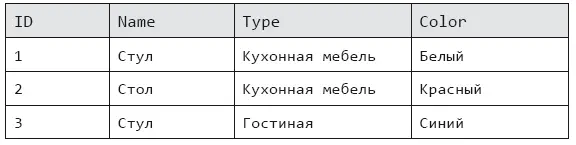
Чтобы найти все товары с типом (колонка Type) «Гостиная», придется прочитать все строки данных (если нет индекса по этому столбцу), что удручает, если их миллиарды и даже триллионы. В колоночной базе данные хранятся по столбцам отдельно, отсюда и название – колоночные:
ID: 1 (1), 2 (2), 3 (3)
Name: Стул (1), Стол (2), Стул (3)
Type: Кухонная мебель (1), Кухонная мебель (2), Гостиная (3)
Color: Белый (1), Красный (2), Синий (3)
Теперь, если делать выборку товаров по типу «Гостиная», придется прочитать только нужный столбец. Но как найти нужные записи? Это не проблема: каждое значение столбца содержит номер записи, к которому оно относится. Дополнительно значения столбцов можно отсортировать и даже сжать, что делает такие базы еще быстрее. В них тоже есть минус – требовательность к «железу» сервера, на котором она работает. Колоночные базы идеально подходят для аналитических задач, которые изобилуют запросами по фильтрации и агрегации данных.
Если нужна «молотилка» для совсем больших данных – то это Hadoop. Она была разработана в компании Yahoo, которая сделала эту технологию общедоступной. Эта система работает на распределенной файловой системе HDFS и не требовательна к оборудованию. Для Hadoop компания Facebook разработала SQL-движок под названием Hive, позволяющий писать запросы к данным на языке SQL. Главное преимущество Hadoop – большая надежность. Минус – медленная скорость, зато там, где обычная БД не справится с каким-то запросом, Hadoop доведет дело до конца, медленно, как черепаха, но верно. Я использовал Hive и был доволен результатом, мне удавалось даже писать на нем простейшие алгоритмы рекомендаций.
Теперь главный вопрос – когда и какие технологии использовать?
Мой рецепт следующий:
• Если данных относительно немного и нет таблиц с миллиардами строк, то проще использовать обычную реляционную базу.
• Если данных больше миллиарда строк или требуется хорошая скорость для аналитических запросов (агрегация и выборки) – то лучше всего использовать колоночную базу данных.
• Если требуется хранить очень большой объем с сотнями миллиардов строк, вы готовы мириться с медленной скоростью или хотите иметь архив исходных данных – то Hadoop.
В Retail Rocket использовался Hive поверх Hadoop для службы технической поддержки, но запросы могли выполняться больше получаса. Поэтому требуемые ими данные были переведены в Clickhouse (колоночная база данных), и обработка запросов ускорилась в сотни раз. А скорость очень важна для интерактивных аналитических задач. Сотрудники Retail Rocket мгновенно полюбили новое решение за его скорость. Hadoop при этом остался в качестве рабочей лошадки для расчета рекомендаций.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.