Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
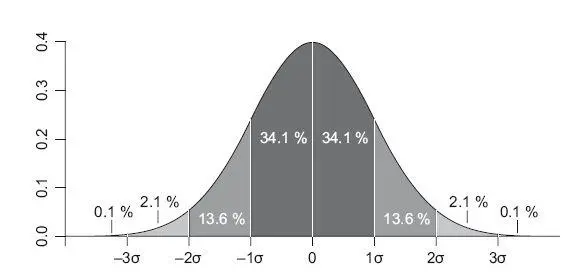
Рис. 4.1.Нормальное распределение и Шесть Сигм
Среднее и медиана для него отличаются в разы. Поэтому правильная цифра – медиана, значение, которое делит выборку пополам. В примере с Ozon.ru это время, в течение которого 50 % пользователей делают следующий заказ после первого. Медиана также более устойчива к выбросам в данных. Если же вы хотите работать со средними, например, из-за ограничений статистического пакета, да и технически среднее считается быстрее, чем медиана, то в случае экспоненциального распределения можно его обработать натуральным логарифмом. Чтобы вернуться в исходную шкалу данных, нужно полученное среднее обработать обычной экспонентой.
Перцентиль – значение, которое заданная случайная величина не превышает с фиксированной вероятностью. Например, фраза «25-й перцентиль цены товаров равен 150 рублям» означает, что 25 % товаров имеют цену меньше или равную 150 рублям, остальные 75 % товаров дороже 150 рублей.
Для нормального распределения, если известно среднее и стандартное отклонение, есть полезные теоретически выведенные закономерности – 95 % всех значений попадает в интервал на расстоянии двух стандартных отклонений от среднего в обе стороны, то есть ширина интервала составляет четыре сигмы. Возможно, вы слышали такой термин, как Шесть сигм (six sigma, рис. 4.1), – эта цифра характеризует производство без брака. Так вот, этот эмпирический закон следует из нормального распределения: в интервал шести стандартных отклонений вокруг среднего (по три в каждую сторону) укладывается 99.99966 % значений – идеальное качество. Перцентили очень полезны для поиска и удаления выбросов из данных. Например, при анализе экспериментальных данных вы можете принять то, что все данные вне 99-го перцентиля – выбросы, и удалять их.
Графики
Хороший график стоит тысячи слов. Основные виды графиков, которыми пользуюсь я:
• гистограммы;
• диаграмма рассеяния (scatter chart);
• график временного ряда (time series) с линией тренда;
• график «ящики с усами» (box plot, box and whiskers plot).
Гистограмма (рис. 4.2) – наиболее полезный инструмент анализа. Она позволяет визуализировать распределение по частотам появления какого-то значения (для категориальной переменной) или разбить непрерывную переменную на диапазоны (bins). Второе используется чаще, и если к такому графику дополнительно предоставить описательные статистики, то у вас будет полная картина, описывающая интересующую вас переменную. Гистограмма – это простой и интуитивно понятный инструмент.
График диаграммы рассеяния (scatterplot, рис. 4.3) позволяет увидеть зависимость двух переменных друг от друга. Строится он просто: на горизонтальной оси – шкала независимой переменной, на вертикальной оси – шкала зависимой. Значения (записи) отмечаются в виде точек. Также может добавляться линия тренда. В продвинутых статистических пакетах можно интерактивно пометить выбросы.
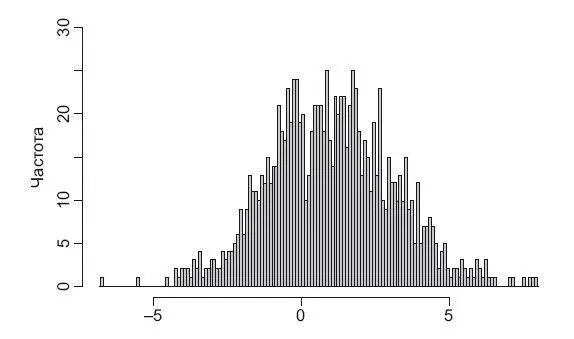
Рис. 4.2.Гистограмма
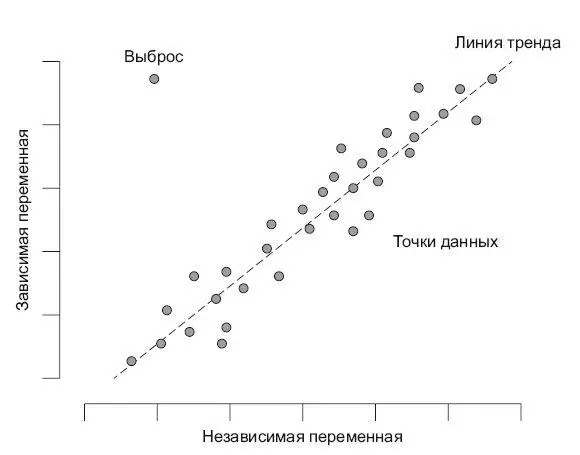
Рис. 4.3.Диаграмма рассеяния
Графики временных рядов (time series, рис. 4.4) – это почти то же самое, что и диаграмма рассеяния, в которой независимая переменная (на горизонтальной оси) – это время. Обычно из временного ряда можно выделить две компоненты – циклическую и трендовую. Тренд можно построить, зная длину цикла, например, семидневный – это стандартный цикл продаж в продуктовых магазинах, на графике можно увидеть повторяющуюся картинку каждые 7 дней. Далее на график накладывается скользящее среднее с длиной окна, равной циклу, – и вы получаете линию тренда. Практически все статистические пакеты, Excel, Google Sheets умеют это делать. Если нужно получить циклическую компоненту, это делается вычитанием из временного ряда линии тренда. На основе таких простых вычислений строятся простейшие алгоритмы прогнозирования временных рядов.
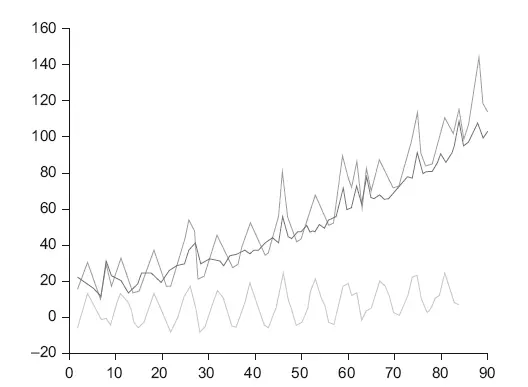
Рис. 4.4.Временные ряды
График «Ящик с усами» (box plot, рис. 4.5) очень интересен; в некоторой степени он дублирует гистограммы, так как тоже показывает оценку распределения.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.