Владимир Брюков - Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews
Здесь есть возможность читать онлайн «Владимир Брюков - Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2011, ISBN: 2011, Издательство: КНОРУС; ЦИПСиР, Жанр: personal_finance, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews
- Автор:
- Издательство:КНОРУС; ЦИПСиР
- Жанр:
- Год:2011
- Город:Москва
- ISBN:978-5-406-01441-7
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для всех, кто интересуется валютным рынком, собирается зарабатывать или уже зарабатывает на этом рынке, хочет научиться делать прогнозы по курсам валют. Для валютных инвесторов, трейдеров и студентов, будущая профессия которых связана с работой в банке, финансовой компании или с операциями на финансовых и товарных рынках.
Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:

где расчетное стандартное отклонение а находится таким же образом, как и в формуле (4.10).
В нашем случае коэффициент эксцесса имеет следующее значение:
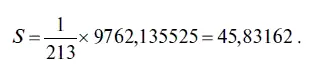
Поскольку коэффициент эксцесса равен 45,83162 (см. табл. 4.5), можно сделать вывод, что распределение остатков является «островершинным». По сути это означает, что в этом распределении имеется ярко выраженное ядро плотности распределения, внутри которого диапазон колебаний величины остатков незначителен, и рассеянное «гало», где разброс колебаний величины остатков весьма значителен. С точки зрения предсказания курса доллара такой характер распределения позволяет задавать, например, при 80 %-ном уровне надежности, не слишком широкие прогностические интервалы. Правда, если инвестор хочет иметь прогноз с более высоким 99 %-ным уровнем надежности, то из-за рассеянного «гало» ширина этих интервалов начинает резко увеличиваться.
В EViews есть возможность посмотреть в графическом виде оценку ядра плотности распределения с помощью опций DISTRIBUTION/ KERNEL DENSITY GRAPHS… (распределение/графики ядра плотности распределения). В появившемся мини-окне KERNEL DENSITY (ядро плотности распределения) по умолчанию устанавливается опция EPANECHNICOV, а всего их здесь семь и отличаются они друг от друга по используемому алгоритму сглаживания (рис. 4.2).
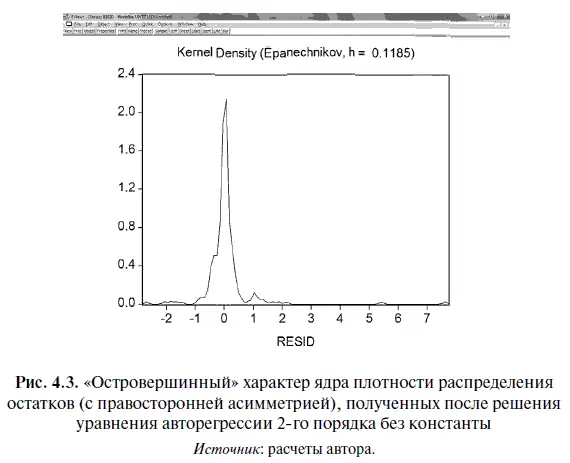
Дело в том, что в отличие от обычной гистограммы (столбчатая диаграмма, высота каждого прямоугольника которой пропорциональна частоте распределения в заданном интервале значений) график ядра плотности распределения создается с помощью сглаживания, в ходе которого различным наблюдениям присваиваются определенные веса. При этом соблюдается следующий принцип: чем дальше отдельное наблюдение от оцениваемой «точки», тем более легкий вес ему присваивается. В результате получается диаграмма, приведенная на рис. 4.3, на которой хорошо виден «островершинный» характер ядра плотности распределения остатков.
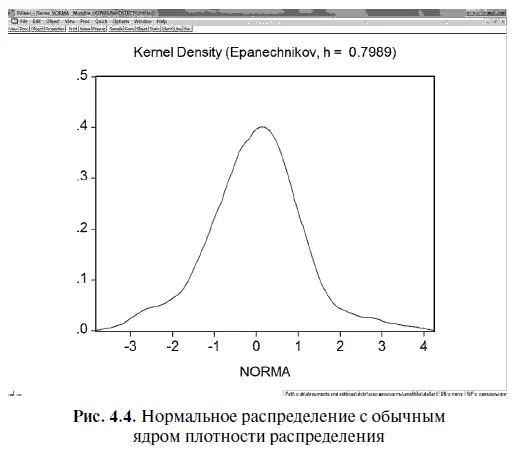
Для большей наглядности ядро плотности распределения остатков можно сравнить с нормальным распределением, имеющим стандартное ядро плотности распределения (рис. 4.4). С этой целью мы получили в Excel нормальное распределение, используя опции АНАЛИЗ ДАННЫХ/ГЕНЕРАЦИЯ СЛУЧАЙНЫХ ЧИСЕЛ. Сравнив рис. 4.3 и 4.4, легко заметить, что у нормального распределения, во-первых, вершина гораздо более плоская; во-вторых, ядро плотности распределения значительно шире; в-третьих, рассеянное «гало» не столь широко разбросано по краям.
Продолжим анализ характера распределения остатков и с этой целью посмотрим оценку значимости критерия Жарка — Бера, представленную в табл. 4.5. При этом следует иметь в виду, что величина критерия Жарка — Бера служит для проверки нулевой гипотезы о нормальном распределении изучаемого статистического ряда. Тестовая статистика в этом случае измеряет разницу между нормальным распределением и коэффициентами асимметрии и эксцесса, вычисленными для данного статистического ряда. Критерий Жарка — Бера находится по следующей формуле:
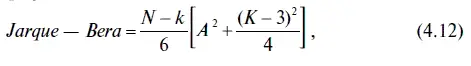
где N— количество наблюдений;
А — коэффициент асимметрии;
К— коэффициент эксцесса;
k — количество параметров, использованных для создания данного временн o го ряда.

После этого значение теста Жарка — Бера сравнивают с распределением χ 2(хи-квадрат) с двумя степенями свободы. В том случае, если критерий Жарка — Бера > χ 2 крипт, то делается вывод о неслучайном характере распределения, а следовательно, нулевая гипотеза о нормальном распределении опровергается. В нашем случае значение теста Жарка — Бера равно 17147,64, а следовательно, если сравнить с соответствующим табличным значением χ 2 крипт 001, 2= 9,21, то рассчитанный нами критерий Жарка — Бера существенно выше последнего.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews»
Представляем Вашему вниманию похожие книги на «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.