Владимир Брюков - Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews
Здесь есть возможность читать онлайн «Владимир Брюков - Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2011, ISBN: 2011, Издательство: КНОРУС; ЦИПСиР, Жанр: personal_finance, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews
- Автор:
- Издательство:КНОРУС; ЦИПСиР
- Жанр:
- Год:2011
- Город:Москва
- ISBN:978-5-406-01441-7
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для всех, кто интересуется валютным рынком, собирается зарабатывать или уже зарабатывает на этом рынке, хочет научиться делать прогнозы по курсам валют. Для валютных инвесторов, трейдеров и студентов, будущая профессия которых связана с работой в банке, финансовой компании или с операциями на финансовых и товарных рынках.
Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
В EViews приводится в качестве дополнительного F -критерий ( F -statistic), который представляет собой тест на определение совокупной значимости всех лаговых остатков. В нашем случае F -критерий также подтверждает отсутствие автокорреляции в остатках.
Как мы уже убедились ранее, при построении уравнения авторегрессии у нас происходит уменьшение временного ряда данных, что ведет к пропуску в том числе и части лаговых остатков. Согласно предложению, выдвинутому в 1993 г. Давидсоном и Маккинном, в этом случае отсутствующие остатки следует приравнивать к нулю. По их мнению, это дает лучшую статистику, чем в случае пропуска этих остатков. Однако, по мнению большинства исследователей, в этом случае распределение F -статистики становится не совсем точным. Тем не менее EViews дает F -критерий для справочных целей.
3.7. Оценка точности решения уравнения авторегрессии в EViews
Важным критерием оценки эффективности статистической модели является уровень точности, получаемый с помощью определенной статистической модели при прогнозе курса доллара. Его в EViews можно оценить с помощью алгоритма действий № 8.
Чтобы оценить точность статистической модели, нужно в строке 3 EQUATION (уравнение) выбрать опцию FORECAST.
В результате откроется мини-окно FORECAST, которое следует заполнить таким образом (рис. 3.6).
По умолчанию в опции FORECAST NAME (название файла с прогнозом) задается название файла с точечным прогнозом путем прибавления к исходному файлу латинской буквы f. Например, если у нас исходный файл — USDollar, то название файла с прогнозом будет задано программой как USDollarf. В опции FORECAST SAMPLE (выборка для прогноза) по умолчанию задается исходная выборка данных для прогноза, которую при необходимости можно изменить. В опции METHOD (метод прогноза) нам следует выбрать STATIC FORECAST (статичный прогноз), т. е. мы оцениваем точность прогноза только на один следующий месяц. Если в опции METHOD выбрать вариант DYNAMIC FORECAST (динамичный прогноз), то это увеличило бы временной горизонт для прогноза, но его точность существенно снизилась бы. Дело в том, что при динамическом прогнозировании предсказание на следующий месяц составляется так же, как и при статичном, но прогнозы на более длительные сроки составляются на основе расчетных, т. е. предсказанных, а не фактических значений независимой переменной.
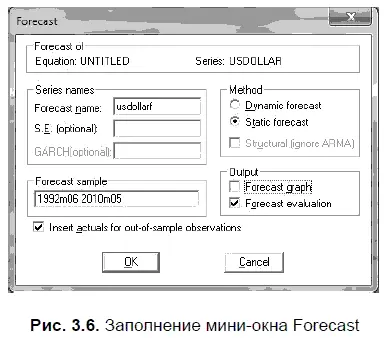
В опции OUTPUT (вывод итогов) мы задали вариант FORECAST EVALUATION (оценка прогноза) и получили таблицу с оценкой точности прогноза этой статистической модели (см. табл. 3.6). При необходимости в последней опции можно задать еще и вариант FORECAST GRAPH (график прогнозов), после чего можно получить и график с прогнозами.
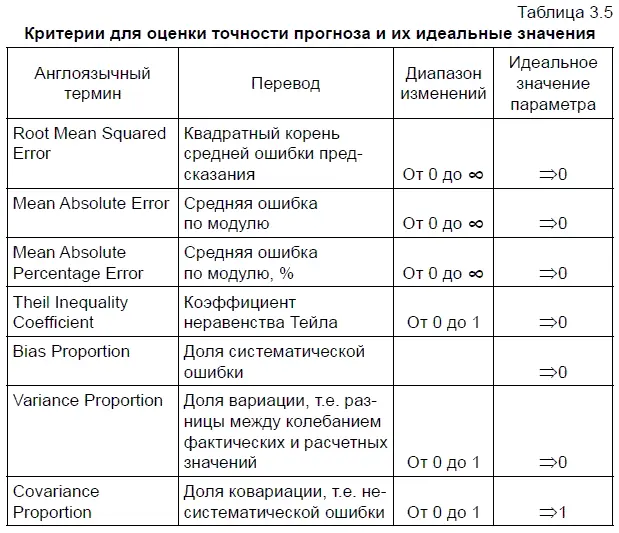
Чтобы по табл. 3.6 вынести суждение о качестве статистической модели, сначала нужно ознакомиться с табл. 3.5. Причем в первую очередь следует обратить внимание на раздел этой таблицы «Идеальное значение параметра». Из него можно сделать вывод: чем ближе стремятся к нулю параметры, представленные в табл. 3.6, тем выше прогностическая ценность статистической модели. Единственным исключением из этого правила является параметр Covariance Proportion (доля ковариации, т. е. доля несистематической ошибки), для которого идеальным значением является единица.
В алгоритме действий № 8 «Как оценить точность статистической модели в EViews» в самом общем виде уже говорилось об интерпретации параметров, характеризующих уровень точности статистической модели. Однако далее все желающие могут более подробно ознакомиться со спецификой параметров, содержащихся в табл. 3.6. «Оценка точности уравнения регрессии (статистической модели) с параметрами USDollar = 0,2260 + 1,2980 USDollar(-l) — 0,3047 USDollar(-2)».

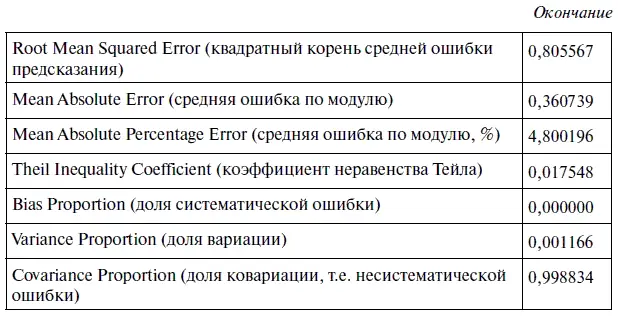
В частности, Root Mean Squared Error (квадратный корень средней ошибки предсказания) представляет собой квадратный корень из суммы квадратов остатков (разницы между фактическим и предсказанным значением), деленной на общее количество наблюдений. Квадратный корень средней ошибки предсказания находят по следующей формуле:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews»
Представляем Вашему вниманию похожие книги на «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Как предсказать курс доллара. Эффективные методы прогнозирования с использованием Excel и EViews» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.