Константин Стефанов - Cуперкомпьютеры - администрирование
Здесь есть возможность читать онлайн «Константин Стефанов - Cуперкомпьютеры - администрирование» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2020, Жанр: Справочники, Прочая околокомпьтерная литература, ОС и Сети, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Cуперкомпьютеры: администрирование
- Автор:
- Жанр:
- Год:2020
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Cуперкомпьютеры: администрирование: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Cуперкомпьютеры: администрирование»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Cуперкомпьютеры: администрирование — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Cуперкомпьютеры: администрирование», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Для увеличения мощности сервера или рабочей станции производители устанавливали несколько «одноядерных» процессоров (обычно от двух до восьми). Такие системы существуют и сейчас и называются симметричными многопроцессорными системами, или SMP-системами (от англ. Symmetric Multiprocessor System) (см. рис. 4).
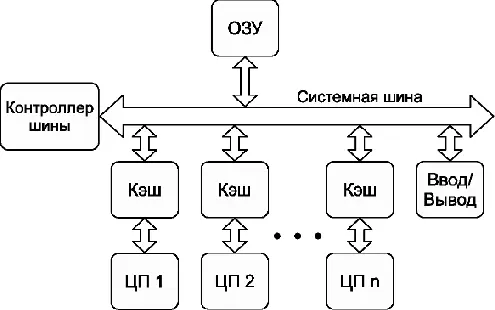
Рис. 4: симметричная многопроцессорная система (SMP)
Как видно из схемы, каждый процессор, представляющий собой одно вычислительное ядро, соединён с общей системной шиной. В такой конфигурации доступ к памяти для всех процессоров одинаков, поэтому система называется симметричной. В последнее время в каждом процессоре присутствует несколько ядер (обычно от 2 до 16). Каждое из таких ядер может рассматриваться как процессор в специфической SMP-системе. Конечно, многоядерная система отличается от SMP-системы, но эти отличия почти незаметны для пользователя (до тех пор, пока он не задумается о тонкой оптимизации программы).
Для ускорения работы с памятью нередко применяется технология NUMA – Non-Uniform Memory Access. В этом случае каждый процессор имеет свой канал в память, при этом к части памяти он подсоединён напрямую, а к остальным – через общую шину. Теперь доступ к «своей» памяти будет быстрым, а к «чужой» – более медленным. При грамотном использовании такой архитектуры в приложении можно получить существенное ускорение.
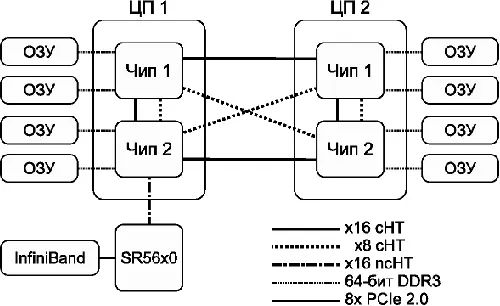
Рис. 5: схема узла NUMA на примере AMD Magny-Cours
Например, в архитектуре AMD Magny-Cours (см. рис. 5) каждый процессор состоит из двух кристаллов (логических процессоров), соединённых между собой каналами HyperTransport. Каждый кристалл (чип) содержит в себе шесть вычислительных ядер и свой собственный двухканальный контроллер памяти. Доступ в «свою» память идёт через контроллер памяти, а в «соседнюю» – через канал HyperTransport. Как видим, построить SMP- или NUMA-систему из двух или четырёх процессоров вполне возможно, а вот с большим числом процессоров – уже непросто.
Ещё одним «камнем преткновения» в современных многоядерных системах является миграция процессов между ядрами. В общем случае для организации работы множества процессов операционная система предоставляет каждому процессу определённый период времени (обычно порядка миллисекунд), после чего процесс переводится в пассивный режим.
Планировщик выполнения заданий, переводя процесс из пассивного режима, выбирает ядро, которое не обязательно совпадает с тем, на котором процесс выполнялся до этого. Нередко получается так, что процесс «гуляет» по всем ядрам, имеющимся в системе. Даже в случае с SMP-системами влияние на скорость работы программы при такой миграции заметно, а в NUMA-системах это приводит ещё и к большим задержкам при доступе в память.
Для того, чтобы избавиться от паразитного влияния миграции процессов между ядрами, используется привязка процессов к ядрам (processor affinity, или pinning). Привязка может осуществляться как к отдельному ядру, так и к нескольким ядрам или даже к одному и более NUMA-узлам. С применением привязки миграция процессов или будет происходить контролируемым образом, или будет исключена вовсе.
Аналогичная проблема присутствует и в механизме выделения памяти пользовательским процессам. Допустим, процессу, работающему на одном NUMA-узле, требуется для работы выделить дополнительную память. В какой области памяти будет выделен новый блок? А вдруг он попадёт на достаточно удалённый NUMA-узел, что резко уменьшит скорость обмена? Для того, чтобы избежать выделения памяти на сторонних узлах, есть механизм привязки процессов к памяти определённого NUMA-узла (memory affinity).
В нормальном случае каждый процесс параллельной программы привязывается к определённым NUMA-узлам как по ядрам, так и по памяти. В этом случае скорость работы параллельной программы не будет зависеть от запуска и будет достаточно стабильной. При запуске параллельных программ такая привязка не просто желательна, а обязательна. Более подробно данный вопрос рассмотрен в главе « Библиотеки поддержки параллельных вычислений Конец ознакомительного фрагмента. Текст предоставлен ООО «ЛитРес». Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес. Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
», где описываются различные среды параллельного программирования.
Интервал:
Закладка:
Похожие книги на «Cуперкомпьютеры: администрирование»
Представляем Вашему вниманию похожие книги на «Cуперкомпьютеры: администрирование» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Cуперкомпьютеры: администрирование» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.