Brenda A. Wilson - Bacterial Pathogenesis
Здесь есть возможность читать онлайн «Brenda A. Wilson - Bacterial Pathogenesis» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Bacterial Pathogenesis
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Bacterial Pathogenesis: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Bacterial Pathogenesis»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Completely revised and updated, and for the first time in stunning full-color, Bacterial Pathogenesis: A Molecular Approach, Fourth Edition, builds on the core principles and foundations of its predecessors while expanding into new concepts, key findings, and cutting-edge research, including new developments in the areas of the microbiome and CRISPR as well as the growing challenges of antimicrobial resistance. All-new detailed illustrations help students clearly understand important concepts and mechanisms of the complex interplay between bacterial pathogens and their hosts. Study questions at the end of each chapter challenge students to delve more deeply into the topics covered, and hone their skills in reading, interpreting, and analyzing data, as well as devising their own experiments. A detailed glossary defines and expands on key terms highlighted throughout the book. Written for advanced undergraduate, graduate, and professional students in microbiology, bacteriology, and pathogenesis, this text is a must-have for anyone looking for a greater understanding of virulence mechanisms across the breadth of bacterial pathogens.
Bacterial Pathogenesis — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Bacterial Pathogenesis», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Characterization of the Body’s Microbiota
The advent of culture-independent, nucleic acid-based methods for characterizing bacterial populations revolutionized how researchers acquired information about the composition and diversity of bacterial communities and revitalized research interest in the mammalian microbiota. A critical advance over the past decade that changed this picture even more was the development of mega-scale, high-throughput, rapid, and cost-effective DNA sequencing technologies and the accompanying analytical and bioinformatics tools needed to manipulate, interpret, integrate, and store these large data sets. Importantly, the dramatic reduction in sequencing and computational costs in the last few years has moved the field forward at an astounding pace. Not only is it possible to quickly sequence genomes from isolated, individual microbes (genomics), but now the entire assemblage of genomes within complex microbial communities (microbiomes) can also be determined with relative ease.
Parallel to these remarkable advances in DNA sequencing and analysis, other momentous advances have occurred: in RNA sequencing and gene expression technologies (transcriptomics) for the assessment of which genes are expressed under particular conditions; large-scale separation, identification, and analytical tools for assessment of protein expression and function (proteomics); multiplex antibody, cytokine, and chemokine immunologic profiling for assessment of the host immune response; and lipid, sugar, and other metabolite profiling (metabolomics) for the assessment of cellular processes of individual microbial cells as well as those of the entire microbial community and the host. Indeed, many researchers are now combining these various technologies into multivariate holistic approaches (multi-omics) that enable overall functional assessment of the microbiota in the context of the host environment.
Before delving into the microbial populations of different parts of the body, it is worth reviewing some of the powerful new culture-independent approaches and analytical tools that are available for exploring the scope, depth, and variety of microbes that comprise mammalian microbiotas.
Taking a Microbial Census by Using Microbial rRNA Gene Sequence Analysis
Some of the first questions that arise when scientists are seeking to characterize a complex microbial population are: what microbial species and how many of each are present, how much variation in composition is there from person to person and site to site, and how does the composition change with conditions and over time? To answer these questions, it is first necessary to identify the species to which the microbes belong and to determine their phylogenetic relationship (or evolutionary similarity) to each other. Although most studies surveying the microbiota to date have focused on the bacterial content of the community, there are some researchers who are beginning to explore other microbes, such as archaea, fungi, protozoa, and viruses (including bacteriophage). For now, we will likewise focus on characterization of the bacterial content of microbiotas, but will return to the other microbes later in the chapter.
16S rRNA Gene-Based Taxonomical Identification of Bacteria. To complete a census of the species present in a bacterial community, researchers must first perform sequence analysis of all, or at least the more abundant, species present in a sample. For this, they need to choose a gene that is common to all bacteria of interest. The most widely used approach to determining the bacterial content of a community is to isolate the total genomic DNA from the microbial population and then employ polymerase chain reaction (PCR) to specifically amplify the bacterial 16S rRNA genes ( Figure 5-1), which are then sequenced. The use of 16S rRNA genes is advantageous because these genes are large enough (1,542 nucleotides for the Escherichia coli gene) to contain adequate sequence information for identification and discrimination among close relatives but small enough to be sequenced easily. The 16S rRNA gene, which is present in all bacteria, is a mosaic of regions ( Figure 5-1A), some that are highly conserved among all bacterial species and some that are less conserved and consequently contain sequence signatures for different bacterial species, acquired through slow accumulation of mutations over time.
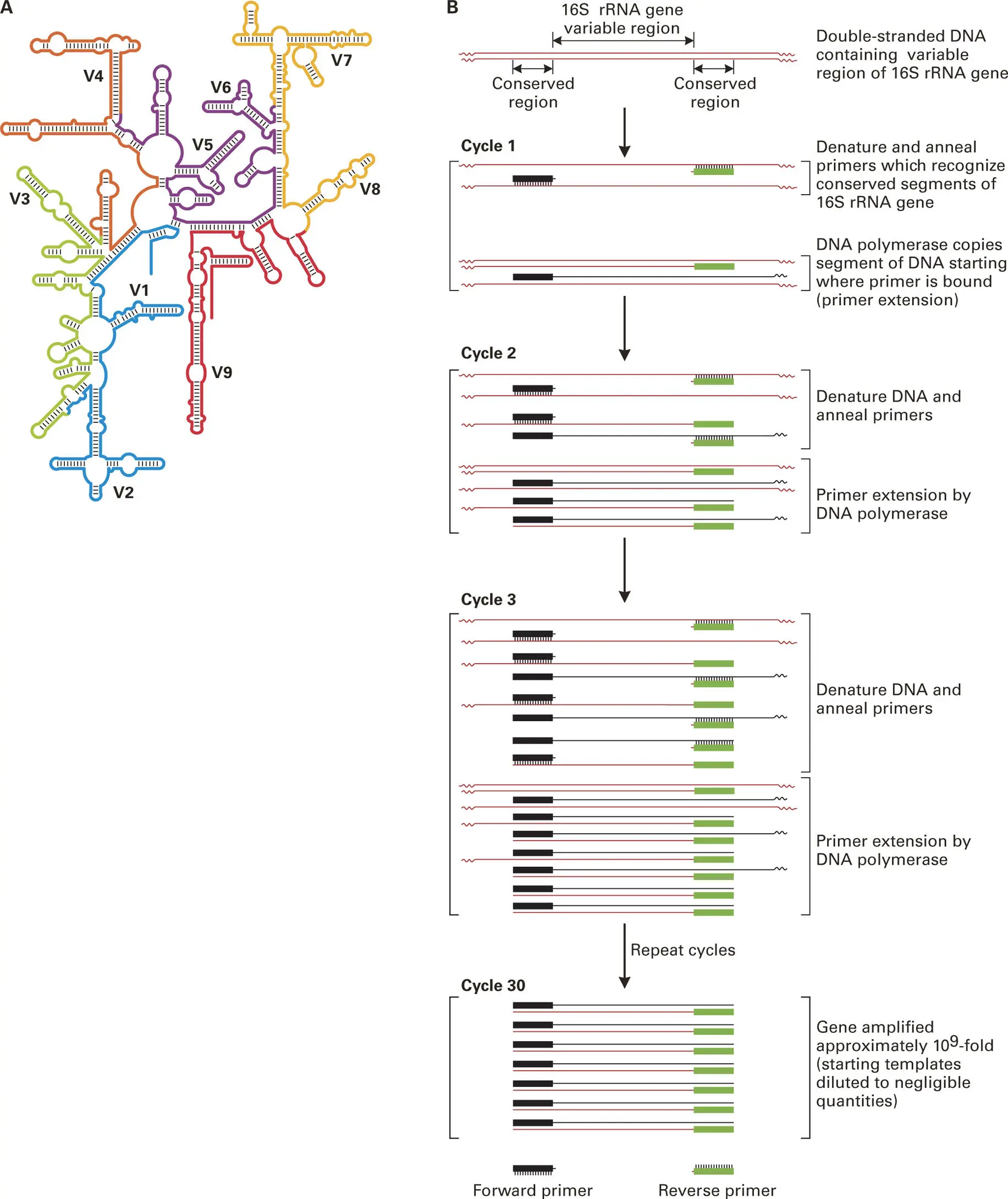
Figure 5-1. Detection of bacteria in a clinical specimen based on 16S rRNA gene amplification by PCR. The 16S rRNA gene is used as the standard for bacterial taxonomic identification and phylogenetic relationship studies because it is highly conserved among different taxa of bacteria. (A) The 16S rRNA gene (∼1,542 nucleotides in the Escherichia coli gene shown here) has highly conserved regions of sequence that can serve as primer binding sites for PCR amplification, but also has hypervariable regions (labeled V1 through V9) that can be used as signatures for distinguishing among different bacterial taxa and establishing phylogenetic relationships. (B) For detection of bacteria in a clinical sample, PCR primers (solid dark bars) recognize conserved segments of DNA on either side of the variable region to be amplified. For the PCR reaction, a thermostable DNA polymerase that exhibits maximal catalytic activity at 75–80°C and possesses 3′ to 5′ exonuclease activity that reduces incorporation of the wrong nucleotide is used, such as the Pfu or Vent polymerase. The amplified segment (amplicon) can then be sequenced and compared to rRNA databases of known bacteria for taxonomic identification.
The basic procedure is relatively simple. DNA primers that recognize highly conserved regions at the beginnings and ends of the bacterial 16S rRNA genes are used to amplify most of the gene, including the variable regions containing the identification signatures, by PCR using a thermostable, high-fidelity DNA polymerase, such as Vent or Pfu ( Figure 5-1B). The resulting PCR products, called amplicons, are sequenced directly using new DNA sequencing technologies, described in detail later in the chapter. Using bioinformatics (computer software programs capable of handling and analyzing massive amounts of data), the sequences of the rRNA genes present in the original sample (called output sequence reads) are compared to those available in the ever-growing, publicly available DNA sequence databases ( Box 5-1) to identify the nearest bacterial relatives and provide an immediate identification of the taxon (plural taxa; group of one or more populations of related organisms) from which the sequence originated. It is now possible to identify an unknown bacterial isolate within 24 hours by this approach, and with automation, high-capacity supercomputers, and current bioinformatics tools, it can happen even sooner.
Box 5-1.
Data, Data, Data—What To Do with All That Data?
How does one go about storing and sorting through the massive amounts of sequencing data and information that has been generated over the years? Because of the critical need for researchers to have access to the data and be able to readily use it, a number of centralized, publicly available databases have been formed around the world. These databases, most of which are Web-based and freely available online to the public, consist of libraries of life sciences information, DNA sequencing data, protein structure data, gene expression data, and other computational or scientific data from genomics, transcriptomics, proteomics, metabolomics, and phylogenetics. Because of the need for compiling and analyzing these massive amounts of data and information from various sources, an entirely new field of bioinformatics emerged that involves design, development, management, utilization, and maintenance of these life sciences databases. Databases have become an important tool and resource for scientists studying complex biological systems. Whenever a researcher obtains or publishes a nucleotide sequence or other data in a scientific journal, the researcher is required to deposit that sequence and/or information in one of the databases, and that sequence receives an accession number, which is a tracking number that helps the databases maintain and cross-reference the information.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Bacterial Pathogenesis»
Представляем Вашему вниманию похожие книги на «Bacterial Pathogenesis» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Bacterial Pathogenesis» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.