Tina M. Henkin - Snyder and Champness Molecular Genetics of Bacteria
Здесь есть возможность читать онлайн «Tina M. Henkin - Snyder and Champness Molecular Genetics of Bacteria» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Snyder and Champness Molecular Genetics of Bacteria
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Snyder and Champness Molecular Genetics of Bacteria: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Snyder and Champness Molecular Genetics of Bacteria»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Although the text is centered on the most-studied bacteria,
and
, many examples are drawn from other bacteria of experimental, medical, ecological, and biotechnological importance. The book's many useful features include
Text boxes to help students make connections to relevant topics related to other organisms, including humans A summary of main points at the end of each chapter Questions for discussion and independent thought A list of suggested readings for background and further investigation in each chapter Fully illustrated with detailed diagrams and photos in full color A glossary of terms highlighted in the text While intended as an undergraduate or beginning graduate textbook, Molecular Genetics of Bacteria is an invaluable reference for anyone working in the fields of microbiology, genetics, biochemistry, bioengineering, medicine, molecular biology, and biotechnology.
"This is a marvelous textbook that is completely up-to-date and comprehensive, but not overwhelming. The clear prose and excellent figures make it ideal for use in teaching bacterial molecular genetics."—
, University of Washington
Snyder and Champness Molecular Genetics of Bacteria — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Snyder and Champness Molecular Genetics of Bacteria», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
While the term “wobble” may suggest that the process is random or that there is a lack of stringency inherent in the system, this is not really the whole story. As indicated earlier in the chapter, base pairing in RNA is different than in DNA, and modification of the anticodon itself contributes to alternative base-pairing rules, resulting in a process in which fewer tRNAs can be utilized to accurately recognize more codons ( Figure 2.33). For example, wobble allows a G in the first position of the anticodon to pair with either a C or a U in the third position of the codon but not with an A or a G; this explains why UAU and UAC, but not UAA or UAG, are codons for tyrosine and can be recognized by a single tRNA with a GUA anticodon sequence. Similarly, a U in the first position of the anticodon can pair with either an A or a G in the third position of the codon (corresponding to the fact that both CAA and CAG are glutamine codons and can be recognized by a single tRNA with a UUG anticodon sequence). The rules for wobble are complicated by the fact that the bases in tRNA are sometimes modifed, and a modified base in the first position of an anticodon can have altered pairing properties. Inosine, which is a purine base found only in tRNA, can pair with any residue, so a single tRNA with inosine at the first position of the anticodon can recognize multiple codons (UCU, UCA, and UCC in Figure 2.33C, all of which encode serine). In other cases, an organism may use multiple tRNAs to recognize different codons that specify the same amino acid.
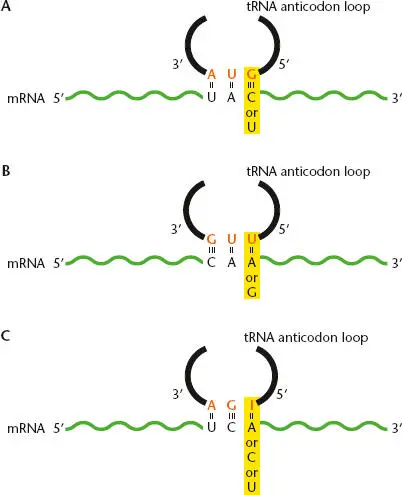
Figure 2.33 Wobble pairing between the anticodon on the tRNA and the codon in the mRNA. Non-Watson-Crick pairing interactions are possible in the third position of the codon. Alternative pairings for the anticodon base are shown: (A)guanine to cytosine or uracil; (B)uracil to adenine or guanine; and (C)inosine (a purine base found only in tRNAs) to adenine, cytosine, or uracil. This allows a single tRNA to recognize multiple codons.
TERMINATION CODONS
As noted above, not all codons stipulate an amino acid; of the 64 possible nucleotide combinations, only 61 actually encode an amino acid. The other three (UAA, UAG, and UGA) are termination (or nonsense) codons in most organisms. The termination codons are usually used to terminate translation at the end of genes (see “Translation Termination” above).
AMBIGUITY
In general, each codon specifies a single amino acid, but some can specify a different amino acid, depending on where they are in the mRNA. For example, the codons AUG and GUG encode formylmethionine if they are at the beginning of the coding region but encode methionine or valine, respectively, if they are internal to the coding region. The codons CUG, UUG, and even AUU also sometimes encode formylmethionine if they are at the beginning of a coding sequence.
The codon UGA is another exception. This codon is usually used for termination but encodes the amino acid selenocysteine in a few positions in genes ( Box 2.5) and encodes tryptophan in some types of bacteria. Similarly, UAG is usually used for termination but can be used to encode the novel amino acid pyrrolysine in certain organisms.
CODON USAGE
Just because more than one codon can encode an amino acid does not mean that all the codons are used equally in all organisms. The same amino acid may be preferentially encoded by different codons in different organisms. This codon preference may reflect higher concentrations of certain tRNAs or may be related to the base composition of the DNA of the organism. While mammals have an average G+C content of about 50% (so that there are about as many AT base pairs in the DNA as there are GC base pairs), some bacteria and their viruses have very high or very low G+C contents. How the G+C content can influence codon preference is illustrated by some members of the genera Pseudomonas and Streptomyces . These organisms have G+C contents of almost 75%. To maintain such high G+C contents, the codon usage of these bacteria favors the codons that have the most G’s and C’s for each amino acid.
Polycistronic mRNA
In eukaryotes, each mRNA normally encodes only a single polypeptide. In contrast, in bacteria and archaea, one mRNA can encode either one polypeptide ( monocistronic mRNAs) or more than one polypeptide ( polycistronic mRNAs). Polycistronic mRNAs must have a separate TIR for each coding sequence to allow them to be translated.
The name “polycistronic” is derived from “cistron,” which is the genetic definition of the coding region for each polypeptide, and “poly,” which means many. Similarly, “monocistronic” is derived from “mono,” which means one. Figure 2.34shows a typical polycistronic mRNA in which the coding sequence for one polypeptide is followed by the coding sequence for another. The space between two coding regions can be very short, and the coding sequences may even overlap. For example, the coding region for one polypeptide may end with the termination codon UAA, but the last A may be the first nucleotide of the initiator codon AUG for the next coding region. Even if the two coding regions overlap, the two polypeptides on an mRNA can be translated independently by different ribosomes.
Polycistronic mRNAs do not exist in eukaryotes, in which, as described above, TIRs are much less well defined and translation usually initiates at the AUG codon closest to the 5′ end of the mRNA. In eukaryotes, the synthesis of more than one polypeptide from the same mRNA usually results from differential splicing of the mRNA or from high-level frameshifting during the translation of one of the coding sequences (see “Reading Frames” above); there are also specialized events in which an RNA element called an internal ribosome entry sequence directs binding of a ribosome to a site within the RNA. Polycistronic RNA leads to phenomena unique to bacteria, i.e., translational couplingand polarity, which are described below.
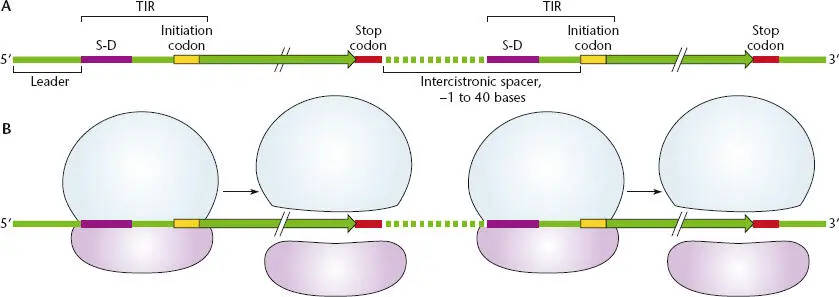
Figure 2.34 Structure of a polycistronic mRNA. (A)The coding sequence for each polypeptide is between the initiation codon and the stop codon. The region 5′ of the first initiation codon is called the leader sequence, and the untranslated region between a stop codon for one gene and the next initiation codon is known as the intercistronic spacer. (B)The association of the 30S and 50S ribosomes at a translational initiation region (TIR) and their dissociation at a stop codon. New 30S and 50S subunits associate at a downstream TIR.
TRANSLATIONAL COUPLING
Two or more polypeptides encoded by the same polycistronic mRNA can be translationally coupled. Two genes are translationally coupledif translation of the upstream gene affects the efficiency of the translation of the gene immediately downstream.
Figure 2.35shows an example of how two genes could be translationally coupled. The TIR including the AUG initiation codon of the second gene is sequestered in a hairpin on the mRNA, so it cannot be recognized by an initiating ribosome. However, a ribosome arriving at the UAA stop codon for the first gene can open up this secondary structure, allowing another ribosome to bind to the downstream TIR and initiate translation of the second gene. Thus, translation of the second gene in the mRNA depends on the translation of the first gene. Mutations that disrupt translation of the upstream coding sequence (e.g., nonsense mutations or frameshift mutations that result in premature termination because the ribosome encounters nonsense codons in the new reading frame) therefore affect not only the gene in which they are located, but also the translationally coupled downstream gene.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Snyder and Champness Molecular Genetics of Bacteria»
Представляем Вашему вниманию похожие книги на «Snyder and Champness Molecular Genetics of Bacteria» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Snyder and Champness Molecular Genetics of Bacteria» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.