Machine Vision Inspection Systems, Machine Learning-Based Approaches
Здесь есть возможность читать онлайн «Machine Vision Inspection Systems, Machine Learning-Based Approaches» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Machine Vision Inspection Systems, Machine Learning-Based Approaches
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Machine Vision Inspection Systems, Machine Learning-Based Approaches: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Machine Vision Inspection Systems, Machine Learning-Based Approaches»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This volume 2 covers machine learning-based approaches in MVIS applications and it can be employed to a wide diversity of problems particularly in Non-Destructive testing (NDT), presence/absence detection, defect/fault detection (weld, textile, tiles, wood, etc.,), automated vision test & measurement, pattern matching, optical character recognition & verification (OCR/OCV), natural language processing, medical diagnosis, etc. This edited book is designed to address various aspects of recent methodologies, concepts, and research plan out to the readers for giving more depth insights for perusing research on machine vision using machine learning-based approaches.
Machine Vision Inspection Systems, Machine Learning-Based Approaches — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Machine Vision Inspection Systems, Machine Learning-Based Approaches», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:

Figure 2.6 Gurmukhi (left) and Cyrillic (right) alphabets.
Table 2.4 Accuracies of different MNIST models.
| MNIST Model | Accuracy |
| 1-Layer NN [18] | 88% |
| 2-layer NN [18] | 95.3% |
| Large convolutional NN [25] | 99.5% |
| Proposed capsule layer-based Siamese network (1-shot) | 51% |
| Proposed capsule layer-based Siamese network (20-shot) | 74.5% |
The MNIST dataset is a benchmark model for image classification algorithms and has been solved to get more than 90% accuracy as summarized in Table 2.4. These methods are based on deep neural networks and use all the 60K characters in the dataset.
Although the proposed capsule layers-based Siamese network model has shown only 51% accuracy with MNIST dataset, that has used only one sample for each digit class while other models have access to more than 60,000 samples. The proposed solution has improved this accuracy by using the same n-shot learning technique. By using 20 samples the accuracy is improved by 23.5% as depicted in Figure 2.7. Thus, the classification accuracy of MNIST dataset is improved from 51 to 74.5% by using a greater number of samples.
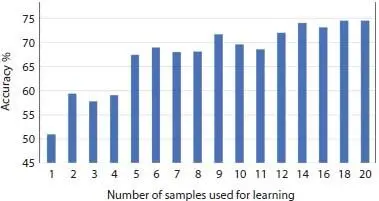
Figure 2.7 MNIST n-shot learning performance.
2.4.4 Sinhala Language Classification
One of the main goals in this research is evaluating the performance of one-shot learning for Sinhala language. Using deep learning approaches is not an option for Sinhala character recognition due to a lack of datasets. Sinhala language has 60 characters, making it a complex alphabet. For each character in Sinhala alphabet, we have added 20 new images to Omniglot dataset. First, we have classified Sinhala characters with a model which was not trained with Sinhala characters and was able to achieve 49% accuracy. After training the model with 5% of the Sinhala dataset, the accuracy is improved to 56%. Considering the languages used in the experiment, Sinhala language has the largest alphabet. Compared to some other languages with a smaller number of characters, the model has given a better accuracy for Sinhala. This could be due to significant visual structural differences between characters.
2.5 Discussion
2.5.1 Study Contributions
This chapter has presented a novel architecture for image verification using Siamese networks structure and capsule networks. We have improved the energy function used in Siamese network to extract complex details output by capsules and obtained on par performance as Siamese networks based on convolutional units [7], but using significantly a smaller number of parameters.
Another major objective of this study is duplicating the human ability to understand completely new visual concepts using previously learnt knowledge. Capsule based Siamese networks can learn a well-generalized function that can be effectively extended to previously unseen data. We have evaluated this capability using n-way classification using one-shot learning. The results have shown more than 80.5% classification accuracy with 20 different characters, which the model has no previous experience.
Moreover, the model is evaluated with MNIST dataset, which is considered as a de facto dataset to evaluate image classification model [30]. The proposed methodology of the capsule layers-based Siamese network has shown 51% accuracy in the classification, using only one image for each digit. Latest deep learning models achieve more than 90% accuracy [39], but that is using all the 60K images available in MNIST dataset. The solution proposed by this study has improved the one-shot learning accuracies by using n-shot learning method, that is using n samples from each image class to do the classification. This way accuracies were improved by 23.5% using 20 samples. As depicted in Figure 2.5, even 28-way learning has showed a classification accuracy of 90%, with Omniglot dataset, while MNIST dataset achieved 74.5% accuracy as shown in Table 2.4.
Further, we have extended the Omniglot dataset by adding a new set of characters for Sinhala language. This contains 600 new handwritten characters for 60 characters in the alphabet. The proposed model has given 49% accuracy for Sinhala without any training stage and it has shown a classification accuracy of 56.22% with a training model accuracy using only one reference image, as shown in Table 2.3.
By comparing with the related studies, in Koch et al. [7], the authors of Omniglot dataset, have used a convolutional layer based Siamese network to solve the one-shot problem [6]. They have shown an accuracy of 94% for class independent classification. This is a similar performance as of the proposed capsule layers-based Siamese network model. In contrast, capsule layers achieve this accuracy with 40% fewer parameters. In an experiment with MNIST dataset using one-shot learning, Koch et al. have achieved 70% accuracy [7], Vinyals et al. [27] have shown 72% accuracy, while the proposed capsule layers-based Siamese network model has given 76% accuracy. The approach in Vinylas et al. [27], is based on Memory augmented neural networks (MANN) and has a similar structure to recurrent neural networks with external memory.
2.5.2 Challenges and Future Research Directions
Although the proposed solution has shown more than 50% accuracy, which is the general threshold for the tested languages, for most of the alphabet types in Omniglot dataset, it has used a small set of images to achieve that accuracy. This limitation can be surpassed by using handcrafted features, which is time-consuming.
In the proposed capsule layers-based Siamese network model, the accuracy of the within language classifications depends on two factors: the number of characters in the alphabet and visual difference between characters. Some alphabets have visually similar characters. In such cases, although the number of characters in the alphabet is small, the classification accuracy becomes low. Thus, the system architecture can be improved with the representation of the image features using transfer learning. Here, features can be extracted from each character image, using a pre-trained deep neural network, and those images can pass to the Siamese network.
This study can be extended by integrating model in a complete OCR pipeline incorporating a character segmentation and reconstruction algorithm. Also, it is possible to analyse the applicability of the proposed model with complex datasets such as ImageNet [40] and COCO [41] by deepening the Siamese network. Additionally, the knowledge learnt from printed character classification can be used to classify handwritten characters. Further, the model classification accuracy can be improved by using printed characters to train the network at initial stages and then using handwritten characters. This will allow the network to understand the defining attributes of each character and such dataset can be generated easily.
2.5.3 Conclusion
Character recognition is a critical module in applications such as document scanning and optical character recognition. With the emergence of deep learning techniques, languages like English have achieved high classification accuracies. However, the applicability of those deep learning methods is constrained in low resource languages, because of the lack of well-developed datasets. This study has focused on implementing a viable method for classification of handwritten characters in low resource languages. Due to the restrictions on the size of available dataset, this problem is modelled as a one-shot learning problem and solved using Siamese networks based on Capsule networks. Siamese network is a de facto type of network use in one-shot learning, but when it comes to image-related tasks, they still need a large number of training dataset. However, the use of Capsule layers-based Siamese network, which can mitigate information losses in Convolutional neural networks allowed to train a Siamese network with a small number of parameters, datasets and get on par performance as a convolutional network. This model is tested with Omniglot dataset and achieved 30–85% accuracy for different alphabets. Further, the model has shown a classification accuracy of 74.5% for MNIST dataset.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Machine Vision Inspection Systems, Machine Learning-Based Approaches»
Представляем Вашему вниманию похожие книги на «Machine Vision Inspection Systems, Machine Learning-Based Approaches» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Machine Vision Inspection Systems, Machine Learning-Based Approaches» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.