Machine Vision Inspection Systems, Machine Learning-Based Approaches
Здесь есть возможность читать онлайн «Machine Vision Inspection Systems, Machine Learning-Based Approaches» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Machine Vision Inspection Systems, Machine Learning-Based Approaches
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Machine Vision Inspection Systems, Machine Learning-Based Approaches: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Machine Vision Inspection Systems, Machine Learning-Based Approaches»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This volume 2 covers machine learning-based approaches in MVIS applications and it can be employed to a wide diversity of problems particularly in Non-Destructive testing (NDT), presence/absence detection, defect/fault detection (weld, textile, tiles, wood, etc.,), automated vision test & measurement, pattern matching, optical character recognition & verification (OCR/OCV), natural language processing, medical diagnosis, etc. This edited book is designed to address various aspects of recent methodologies, concepts, and research plan out to the readers for giving more depth insights for perusing research on machine vision using machine learning-based approaches.
Machine Vision Inspection Systems, Machine Learning-Based Approaches — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Machine Vision Inspection Systems, Machine Learning-Based Approaches», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
For the n-way classification task, the statistical approach random guessing techniques are defined, such that if there are n options and if only one is correct, the chance of prediction being correct is 1/n. Thus, for the repeated experiment the accuracy is considered as a percentage of that probability. Here, the classification accuracy has dropped with the growth of the reference set, because then the solution space is large for the classification task. Nearest neighbor shows exponential degrades while Siamese networks have less reduction with a similar level of performance.
Figure 2.3shows the classification results obtained by different models, namely the 20-way classification task (top), Capsule Siamese network (middle) and Convolutional Siamese network (bottom). The figure shows the samples of the test images and the corresponding classification results. Capsule based architecture was able to identify small changes in image structure, as shown in the middle row.
Figure 2.3illustrates a few 20-way classification problems in which the proposed capsule layers-based Siamese network model outperforms the convolutional Siamese network. In most of the cases, the convolutional network fails to identify minor changes in the image, such as small line segments, curves. However, with the detailed features extracted through capsules, such decisions were made easy in the proposed capsule network model.
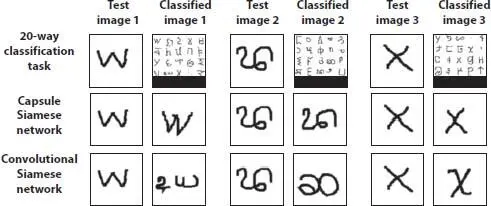
Figure 2.3 Sample 1 classification results.
Figure 2.4depicts a few samples, where the proposed capsule network model fails to classify characters correctly. For certain characters, there is a vast difference in the writing styles between two people. In such cases, the proposed capsule layers-based Siamese network underperforms compared to the CNN. Capsule network model fails in certain cases while convolutional units successfully identify the character.
As a solution to the decrease of n-way classification accuracy, we propose n-shot learning instead of one-shot learning. In one-shot learning, we use only one image from each class in the reference set, however, n-shot learning, we use n images for each category and select the category with highest similarity as in Equation (2.4), where argmax is the argument maximizing the summation, X denotes the image and the function F(x, x i,n) states the similarity score.

Figure 2.4 Sample 2 classification results.
(2.4) 
Accuracies obtained with n-shot learning for 2-, 6-, 20- and 28-way classification are illustrated in Figure 2.5. There is no significant improvement for test cases with small classification set, however, when the classification set is large n-shot learning can significantly improve the performance. For instance, 28-way classification accuracy is improved from 78 to 90% by using 20 images for each class in the reference set. Here, the classification accuracy improves with the increase of the number of samples that are used to compare against. For n-way classification with smaller n with few samples 100% accuracy achieved while more complex task needs a greater number of samples.
2.4.2 Within Language Classification
In n-way testing, we use characters from different languages, but the accuracy obtained for individual language is the main determinant for research. Language-wise classification accuracy was evaluated by preparing one-shot tasks with characters taken from a single alphabet, and the results were illustrated in Table 2.3. These results are based on the nearest neighbour, 1-shot capsule network classifications within individual alphabets. We have selected the Nearest neighbor method because it is a simpler classification method that uses raw pixel values. Thus, it is evident that language level classification accuracy is proportional to the number of characters in the language. Another critical factor that influences accuracy is the structural similarity between characters.
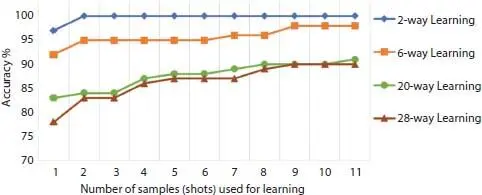
Figure 2.5 Omniglot n-shot n-way learning performance.
Table 2.3 Classification accuracies within individual alphabets.
| Model | Characters | Nearest neighbor | 1-shot capsule network |
|---|---|---|---|
| Aurek-Besk | 25 | 6.40% | 84.40% |
| Angelic | 19 | 6.32% | 76.84% |
| Keble | 25 | 2.00% | 71.20% |
| Atemayar Qelisayer | 25 | 4.00% | 62.80% |
| Tengwar | 24 | 3.33% | 62.08% |
| ULOG | 25 | 3.60% | 61.60% |
| Syriac (Serrto) | 22 | 6.36% | 58.64% |
| Atlantean | 25 | 2.80% | 58.00% |
| Avesta | 25 | 5.20% | 57.60% |
| Cyrillic | 44 | 2.05% | 57.05% |
| Sinhala | 60 | 1.00% | 56.22% |
| Ge`ez | 25 | 1.60% | 52.40% |
| Mongolian | 29 | 4.83% | 52.07% |
| Glagolitic | 44 | 1.82% | 50.68% |
| Manipuri | 39 | 3.08% | 50.51% |
| Malayalam | 46 | 3.26% | 45.87% |
| Tibetan | 41 | 2.93% | 45.61% |
| Sylheti | 27 | 4.07% | 40.37% |
| Gurmukhi | 44 | 2.27% | 38.41% |
| Oriya | 45 | 1.56% | 33.33% |
| Kannada | 40 | 1.00% | 29.25% |
For further analysis, we consider the alphabet models with the same number of characters and those have shown the highest and lowest classification accuracies. Consider the characters of Gurmukhi (38.41% accuracy) and Cyrillic (57.05% accuracy), which has the same number of characters (44), but accuracy differs by 18.64%. The accuracy difference could be due to the structural similarity between characters in those alphabets. Figure 2.6shows the two alphabets. Due to the same reason, we get lower accuracies for within language classification compared to mixed language n-way classification as described in Section 2.4.1.
Further, in an attempt to boost the accuracies in classification, we have used n-shot learning, while keeping 10 images for each character in the alphabet as the reference set and 10 images for averaging the results. By this experiment, we obtained 7 to 15% accuracy improvement resulting in 94% highest accuracy for Aurek-Besh language and 40% lowest accuracy for Oriya language, respectively.
2.4.3 MNIST Classification
The Omniglot dataset has more than 1,600-character classes, but has only 20 samples for each category. In contrast, MNIST dataset has 10 classes and 60,000 total training samples [30]. Since the proposed model of this study aims to learn an abstract knowledge about characters and extend it to identify new characters, by treating MNIST as a whole new alphabet with 10 characters, we could use the proposed capsule layers-based Siamese network model to apply classifications for MNIST dataset. Table 2.4shows the accuracy values obtained by different MNIST models. Here, large neural networks have achieved more than 90% accuracy while the proposed capsule layers-based Siamese network model has given 76% accuracy with only 20 images.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Machine Vision Inspection Systems, Machine Learning-Based Approaches»
Представляем Вашему вниманию похожие книги на «Machine Vision Inspection Systems, Machine Learning-Based Approaches» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Machine Vision Inspection Systems, Machine Learning-Based Approaches» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.