Data Analytics in Bioinformatics
Здесь есть возможность читать онлайн «Data Analytics in Bioinformatics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Data Analytics in Bioinformatics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Data Analytics in Bioinformatics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Data Analytics in Bioinformatics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Data Analytics in Bioinformatics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Data Analytics in Bioinformatics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
SOM’s are highly effective in mapping high dimensional data. The representation of data in the form of map provides quick visualization and interpretation [24].
2.3.7 Grid-Based Clustering
In grid based algorithm rather than working with the data points this operates on space around the data points. The grid structure is made up of cells which segregate the data into number of closely connected cells. Density of each cell is calculated and sorted accordingly [25]. The computational complexity of grid based algorithm is less when compared with other algorithms this makes this approach more adaptable in dealing with large datasets.
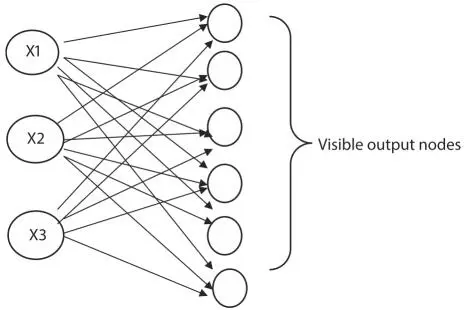
Figure 2.5Self Organizing Map (SOM).
2.3.7.1 STING (Statistical Information Grid-Based Algorithm)
The working principle of this algorithm is based on the users input density value with respect to the cluster areas, space with the low density is referred as non-relevant which is discarded as noisy data. Computationally STING requires fewer resources. The grid structure along with the statistical information associated with the cells gives a graphical representation of cluster formed [26].
2.3.8 Soft Clustering
In this approach of soft clustering the data points in the dataset can belong to any cluster this is also defined as a probabilistic model. In simpler terms a single data point can appear in other clusters sharing the similarities. Among the soft clustering approaches FCM is most popular.
2.3.8.1 FCM (Fuzzy Class Membership)
This algorithm is mostly applied in microarray data analysis as microarrays are collection of tens of thousands of genes and analysing them concurrently. This uses a membership function upon which a membership matrix is built from the dataset. This is updated at every instance of similarity check with the data points. The degree of membership is given by the weights of the matrix [25] which specifies the data point how similar it is to the mean of a cluster. The membership values ranges from 0 to 1.
2.4 Conclusion
This chapter provides an overview of unsupervised learning algorithms and approaches used in the field of bioinformatics for the exploration of gene expression data. The chapter provide insights about various clustering algorithms used in the field of bioinformatics. These algorithms when applied on gene expression data helps in building gene expression profiling in which co expressed genes are clustered together that exhibits similar cell function, identification of gene homology which aids researchers in drug discovery based on the diseased targets using the microarray analyses. These clustering algorithms also comprehend the genetic data in studying about gene functions, identifying sub types of cells which assist in diseased target identification.
References
1. Simeone, O., A Very Brief Introduction to Machine Learning With Applications to Communication Systems. IEEE Trans. Cognit. Commun. Networking , 4, 4, 648–664, 2018.
2. Dixit, P. and Prajapati, G.I., Machine Learning in Bioinformatics: A Novel Approach for DNA Sequencing. 2015 Fifth International Conference on Advanced Computing & Communication Technologies , Haryana, pp. 41–47, 2015.
3. https://en.wikipedia.org/wiki/Unsupervised_learning.
4. Jain, A.K., Data clustering: 50 years beyond k-means. Pattern Recognit. Lett ., 31, 8, 1, 651−666, 2010, https://doi.org/10.1016/j.patrec.2009.09.011.
5. Oyelade, J. et al ., Data Clustering: Algorithms and Its Applications. 2019 19th International Conference on Computational Science and Its Applications (ICCSA) , Saint Petersburg, Russia , pp. 71–81, 2019.
6. Larrañaga, P., Calvo, B., Santana, R., Bielza, C., Galdiano, J., Inza, I., Lozano, J.A., Armañanzas, R., Santafé, G., Pérez, A., Robles, V., Machine learning in bioinformatics. Briefings Bioinf ., 7, 1, 86–112, March 2006, https://doi.org/10.1093/bib/bbk007.
7. National Research Council (US) Committee on Intellectual Property Rights in Genomic and Protein Research and Innovation, Merrill, S.A. and Mazza, A.M. (Eds.), Reaping the Benefits of Genomic and Proteomic Research: Intellectual Property Rights, Innovation, and Public Health , National Academies Press (US), Washington (DC), 2006, 2, Genomics, Proteomics, and the Changing Research Environment, Available from: https://www.ncbi.nlm.nih.gov/books/NBK19861/.
8. Boundless.com. License: CC BY-SA: Attribution-ShareAlike .
9. Oyelade, J., Isewon, I., Oladipupo, F. et al ., Clustering Algorithms: Their Application to Gene Expression Data. Bioinform. Biol. Insights , 10, 237–253, 2016.
10. Kerr, G., Ruskin, H.J., Crane, M., Doolan, P., Techniques for clustering gene expression data. Comput. Biol. Med ., 38, 3, 283–293, 2008.
11. Jain, A.K., Murty, M.N., Flynn, P.J., Data clustering: A review. ACM Comput. Surv ., 31, 3, 264–323, 1999.
12. ©Nature Education, CC-BY-NC-SA.
13. Jiang, D., Tang, C., Zhang, A., Cluster analysis for gene expression data: A survey. IEEE Trans. Knowl. Data Eng ., 16, 11, 1370–1386, 2004.
14. Chandrasekhar, T., Thangavel, K., Elayaraja, E., Effective clustering algorithms for gene expression data. Int. J. Comput. Appl ., 32, 4, 25–9, 2011.
15. Khan, S.S. and Ahmad, A., Cluster Center Initialization Algorithm for K-Means Clustering. 25, 11, 1293–1302, 2004.
16. Handhayani, T. and Hiryanto, L., Intelligent Kernel K-Means for Clustering Gene Expression. Procedia Comput. Sci ., 59, 171–7, 2015.
17. Kaufman, L. and Rousseeuw, P.J., Finding Groups in Data: An Introduction to Cluster Analysis , vol. 344, John Wiley & Sons, New York, 1990.
18. Sokal, R.R. and Michener, C.D., A statistical method for evaluating systematic relationships. Univ. Kansas Sci. Bull ., 28, 1409–38, 1958.
19. Domany, E., Superparamagnetic clustering of data—The definitive solution of an ill-posed problem. Physica A Stat. Mech. Appl ., 263, 1, 158–69, 1999.
20. Guha, S., Rastogi, R., Shim, K., CURE: an efficient clustering algorithm for large databases, in: ACM SIGMOD Record , vol. 27, New York, NY, pp. 73–84, ACM, USA, 1998.
21. Karypis, G., Han, E.H., Kumar, V., Chameleon: Hierarchical clustering using dynamic modeling. Computer (Long Beach Calif.) , 32, 8, 68–75, 1999.
22. Zhang, T., Ramakrishnan, R., Livny, M., BIRCH: an efficient data clustering method for very large databases , vol. 25, New York, NY, pp. 103–14, ACM, ACM Sigmod Record, USA, 1996.
23. Grun, B., Model Based Clustering, arXiv:1807.01987v1 [stat.ME], 5 Jul 2018.
24. Kohonen, T., The self-organizing map. Proc. IEEE , 78, 9, 1464–80, 1990.
25. Grid-Based Clustering Algorithms, Data Clustering: Theory, Algorithms, and Applications, 209–217, https://doi.org/10.1137/1.9780898718348.ch12.
26. Sander, J., Density-Based Clustering, in: Encyclopedia of Machine Learning , C. Sammut and G.I. Webb (Eds.), Springer, Boston, MA, 2011, https://doi.org/10.1007/978-0-387-30164-8.
27. Ester, M., Kriegel, H.-P., Sander, J., Xu, X., A density-based algorithm for discovering clusters in large spatial databases with noise, in: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96) , AAAI Press, pp. 226–231, 1996.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Data Analytics in Bioinformatics»
Представляем Вашему вниманию похожие книги на «Data Analytics in Bioinformatics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Data Analytics in Bioinformatics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.