Data Analytics in Bioinformatics
Здесь есть возможность читать онлайн «Data Analytics in Bioinformatics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Data Analytics in Bioinformatics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Data Analytics in Bioinformatics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Data Analytics in Bioinformatics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Data Analytics in Bioinformatics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Data Analytics in Bioinformatics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
We will address some of the problems which need to be solved to achieve better classification result. It involves cleaning of noisy data, missing data, duplicate data, etc. from the database to smoothly conduct the classification process. Noisy data refers to the unnecessary information available in the dataset which is meaningless and cannot be interpreted by machines. It can also be called corrupt data. Presence of these data can affect the data preparation process. To smooth the noisy data binning, clustering, regression methods can be used or can simply be deleted from large datasets based on the amount of noise present [11, 12]. Another biggest problem in biological data is the absence of values. In complex biological datasets this issue greatly impacts the performance of accuracy of the model. So to handle missing values various imputation techniques have to be used [12]. Data duplication are ongoing data quality problem testified in diverse domains, including health care, business and molecular biology, etc. [13] Presences of duplicate data leads to data inconsistency and redundancy which produces several consequences in classification problem. This issue can be handled by detecting and eliminating duplicate values.
Biological data may contain thousands of features because they are highly dependent on comparing the behavior of various biological units. These data often contains large amount of irrelevant data which affect the classification accuracy and machine learning efficiency [14]. Dimensionality reduction technique focuses on reducing the number of input features which aids to reduce computation time and redundant data. Dimensionality can be reduced using different method such as Linear Discriminant Analysis (LDA), Principal Component Analysis (PCA), feature selection ,etc.
3.3.2 Biological Data Classification
Databases are the rich source of hidden information which can be extracted for intelligent decision making. Classification is a process by which data is organized into different categories by determining a class for an element in database. Data is grouped into different classes based on the training dataset. The classification process helps analyze data and to build models that define data classes and predict future trends.
The availability of large amount of microarray data has created new scopes in classification methods. Like classification of DNA microarrays contributes significantly for diagnosis and prognosis in many clinical practices [15].
Also the classification of gene expression data addresses the fundamental problem of many diseases. Classification of tumor types has been achieving a great success in cancer diagnosis and precision drug development. However, earlier cancer classification studies were clinical based and they have inadequate analytical expertise. Today thousands of gene expressions data is simultaneously monitored because of the advancement in classification algorithms.
3.3.3 ML in Bioinformatics
Machine learning (ML) is a technique to develop computer program to access data and to learn knowledge automatically from experience without human interventions and assistance. Machine learning techniques and deep learning algorithms enable the classifier to make use of automatic feature learning technique, to make reasonably complex predictions when the model is being trained on large datasets. It means the algorithm is able to learn based on the dataset alone and can discover ways to integrate numerous features of the input information into one intellectual set of features from which further learning can be done [9]. Machine learning technique uses two different methods to train the model: supervised learning and unsupervised learning method [16]. In subsequent sections we will discuss machine learning models used for supervised learning problems.
In recent years, availability of biological datasets have risen abruptly, this has enabled bioinformatics researchers to make use of these machine learning algorithms. ML techniques has been applied to many biological domains such as Microarrays, Systems biology, Genomics, Proteomics, Stroke diagnosis and Text mining, etc. [8].
Machine learning in bioinformatics helps to explore, analyze, manage and store data to extract relevant information from biological data.
Gene identification and nucleotide identification help to understand gene and gene association with disease.
Machine learning tools are also used to determine genomic sequence and examine gene pattern.
Gene sequence classification allows us to grasp the concept of nucleic acid and protein sequence.
Advancement of this field can ultimately leads to the development of automated diagnostic tools, personalized and precision medicine, gene therapy, food analysis, biodiversity management and many more which will target Individual’s lifestyle, environment and custom medical treatments considering person’s vulnerability to disease.
There are many machine learning techniques among which Artificial Neural Network is an effective technique for the identification, selection, classification and prediction of the gene in the DNA Sequences.
3.3.4 Introduction to ANN
ANN is a computing system that resembles human brain, consisting of highly interconnected network of processing units called neurons. It has the ability to handle complex features within data in order to process the information.
Figure 3.2 represents the simple work flow of artificial neural network with a perceptron architecture, which consists of one input layer with few input units representing multiple features present in the database, depending on the objective being defined. Each inputs collected from the dataset are multiplied with weights and fed to a function called activation function to produce the actual output.
Depending on the difference between desired output and actual output weights are modified in each layer of connection and finally output is predicted. Weights are machine learnt values from neural networks. Neural network learns by a feedback process called backpropagation. In backpropagation, weights are modified from the output layer to the input layer, going backward through hidden layer to lessen the difference between actual output and desired output to a certain point [18]. Therefore, backpropagation algorithm helps to reduce the overall computational loss of the network while learning the network. The number of hidden layers used for computation and the type of computation being done in each layer together determine the processing speed of the network.
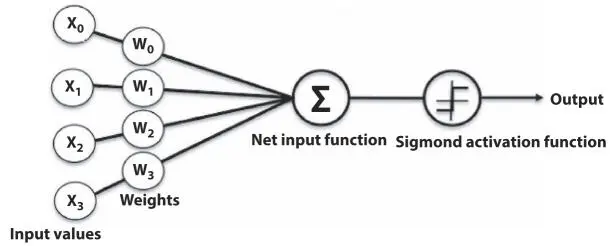
Figure 3.2Simple network architecture of ANN with four input unit [17].
Neural networks are classified into different types based on the structure, neuron density, number of layers, etc. Most commonly used ANNs generally follow the three-layer architecture having an input layer, one or more hidden layers and an output layer as we have seen in Figure 3.2. The number of neurons to be used in each layer of the network depends on the number of features available in a dataset and the complexity of the problem [19].
We will discuss some of ANN model that are widely used as supervised learning models.
Perceptron Network: Perceptron model is a binary classifier that means it separates input data in to two categories. It is the simplest and oldest model of neural network which can implement linearly separable problems such as AND, OR, NOT gate but does not work for non-linear problems like XOR gate. So to deal with non-linear problems or more complex problems we utilize multilayer perceptron. Left side of Figure 3.3 shows a simple architecture of perceptron model consisting of an input layer and an output layer.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Data Analytics in Bioinformatics»
Представляем Вашему вниманию похожие книги на «Data Analytics in Bioinformatics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Data Analytics in Bioinformatics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.