Administrative Records for Survey Methodology
Здесь есть возможность читать онлайн «Administrative Records for Survey Methodology» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Administrative Records for Survey Methodology
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Administrative Records for Survey Methodology: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Administrative Records for Survey Methodology»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Discusses important administrative data issues and suggests how administrative data can be integrated with more traditional surveys Describes practical uses of administrative records for evidence-driven decisions in both public and private sectors Emphasizes using interdisciplinary methodology and linking administrative records with other data sources Explores techniques to leverage administrative data to improve the survey frame, reduce nonresponse follow-up, assess coverage error, mesaure linkage non-consent bias, and perform small area estimation.
Administrative Records for Survey Methodology
Administrative Records for Survey Methodology — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Administrative Records for Survey Methodology», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1.1.2 Concept of Proxy Variable
According to Upton and Cook (2008), a proxy variable is “a measured variable that is used in place of a variable that cannot be measured.” We make two observations. Firstly, one may distinguish between the cases where the ideal measure is unobservable in principle and where it is unavailable by chance. For example, per-capita gross domestic product (GDP) is sometimes used as a proxy measure of living standard, where it seems reasonable to acknowledge that the latter is unobservable in principle. For a contrasting example, country of birth can generate a proxy to mother tongue, by referring to the official language in that country. One should think that in this case the ideal measure is unavailable only due to circumstances. Secondly, in order for a proxy to be used in place of the ideal measure, the two should have the same support. Taking the previous example, it is not the birth country that is a proxy to the true mother tongue, but the official language in that country, and the common support of the proxy and ideal measures being all the existing languages in this case.
Zhang (2015a) defines a proxy variable as one that is similar in definition and has the same support as the target variable. It follows that one can regard two variables as proxy to each other, without having to specify one of them to be the target (or ideal) measure. Variables such as age, sex, education, income can be useful auxiliary but not proxy variables for the binary International Labour Organization (ILO) unemployment status. In particular, sex is not a proxy despite it being binary and thus have the same support as the unemployment status, because they do not have similar definitions. The binary register-based job-seeker status is a proxy, and the ILO unemployment status does not have to be the ideal measure for every conceivable purpose. But the job-seeker status is not a proxy variable for the activity status defined as (employed, unemployed, and inactive) because the two have different support.
Proxy variables can arise from survey data. For example, indirect interview yields proxy measures (Thomsen and Villund 2011), where household members respond on behalf of the absentees. Data collected in different modes can be proxy to each other. A variable collected in a census can be proxy to the same variable or a similarly defined one in the postcensal years. Synthetic datasets released for research can contain proxy variables for the target measures, based on which the synthetic ones are modeled and generated. Register data are perhaps the richest source of proxy variables. It is often possible to have both complete coverage and concurrency, or nearly so. As some common examples of register proxy variable one can mention economic activity status, education level, income, family and housing condition, etc. in social statistics; value-added tax (VAT) based turnover, export and import, house price, animal holding, fishing and hunting figures, arable soils, vegetation, etc. in economic and environmental statistics.
Finally, it is useful to reflect on the relationship between a proxy variable and one that can be affected by measurement errors, since one can always envisage a proxy variable as an attempt to measure the target variable, whether the effort is real or imaginary. Measurement errors are commonly decomposed into two components: random errors and systematic errors. By definition random errors occur by chance and has zero expectation. Insofar as one considers random measurement errors to be unavoidable and omnipresent, any measured variable can only be a proxy of the ideal measure. In contrast, many proxy variables will remain the case even when it is acceptable to disregard the potential random errors for practical purposes. Systematic errors due to discrepancy in definition, instrument, time point, etc. are then the cause of imperfect measure, including when the ideal measure is unobservable in principle. Notice that this interpretation of systematic errors differs from the usage of the term in statistical data editing (de Waal, Pannekoek, and Scholtus 2011), where a systematic error is regarded as an error for which a plausible cause can be detected and knowledge of the underlying error mechanism enables then a satisfactory treatment in an unambiguous deterministic manner. Some examples of such systematic errors are typographical, measurement unit or sign errors. In summary, regardless of whether proxy variables may arise due to measurement errors, we are concerned here with the proxy variables that cannot be corrected by data editing methods.
1.2 Instances of Proxy Variable
Zhang (2012) presents a two-phase life cycle model of integrated statistical micro data, which provides a total-error framework for combining data from multiple sources. The first phase concerns the respective input data before integration takes place. Here, we consider the instances of proxy variables in relation to the various processing steps and associated error sources at the second, integration phase ( Figure 1.1).
1.2.1 Representation
We start with the Representation side in Figure 1.1, which concerns the target population and units. Let us consider coverage error first. For instance, one may have a Population Register that is not sufficiently accurate to allow for direct tabulation of census-like population counts at detailed aggregation levels, so that Population Coverage Surveys are carried out in order to obtain the desired population estimates. The Population Register and Coverage Survey enumerations are proxies of the true population enumeration. This is the situation in Switzerland 2000 (Renaud 2007) and Israel 2008 (Nirel and Glickman 2009). Other instances may involve one or several register enumerations, Census enumeration and Census Coverage Survey enumeration. Capture–recapture methodology is a commonly used estimation approach that combines two or more proxy enumerations subjected to under-counts (Fienberg 1972; Wolter 1986; Hogan 1993). Adjustment of erroneous over-counts has attracted increasing attention recently, in situations where one does not have a Population Register and over-coverage errors are found to be large in the available register enumerations (ONS 2013). See, e.g. Zhang (2015b), for an extension of the capture–recapture modeling approach, Zhang and Dunne (2017) for trimmed dual-system estimation, and Di Cecco et al. (2018) for a latent class modeling approach.
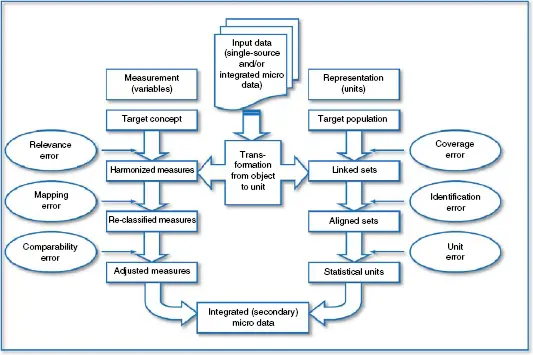
Figure 1.1Second phase of integrated statistical micro data.
Source: Zhang (2012).
All the methods mentioned above require the matching of records in separate sources. In reality, linkage errors may be unavoidable, unless a unique identifier exists in the different files and facilitates exact matching. A linkage error is the case if either a pair of linked records actually do not belong to the same entity or if the records that belong to the same entity fail to be linked. Both multi pass deterministic and probabilistic record linkage procedures are common in practice and often used in tandem. See, e.g. Fellegi and Sunter (1969) and Herzog, Scheuren, and Winkler (2007). The records in different files are compared to each other in terms of key variables such as name, birth date, address, etc. One can regard a concatenated string of key variables as a proxy of the true identifier, insofar as the key variables involved in principle could lead to unique combinations. Distortion of the key variables would then result in erroneous proxy identifiers and potentially cause linkage errors. For population size estimation, see, e.g. Di Consiglio and Tuoto (2015) for a study of linkage errors and dual system estimation, and Zhang and Dunne (2017) for a discussion regarding the trimmed dual-system estimation. More generally, since record linkage is a prerequisite for combining multisource data at the individual level, the matter of linkage errors due to imperfect proxy identifiers can be relevant in many other situations.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Administrative Records for Survey Methodology»
Представляем Вашему вниманию похожие книги на «Administrative Records for Survey Methodology» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Administrative Records for Survey Methodology» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.