Administrative Records for Survey Methodology
Здесь есть возможность читать онлайн «Administrative Records for Survey Methodology» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Administrative Records for Survey Methodology
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Administrative Records for Survey Methodology: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Administrative Records for Survey Methodology»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Discusses important administrative data issues and suggests how administrative data can be integrated with more traditional surveys Describes practical uses of administrative records for evidence-driven decisions in both public and private sectors Emphasizes using interdisciplinary methodology and linking administrative records with other data sources Explores techniques to leverage administrative data to improve the survey frame, reduce nonresponse follow-up, assess coverage error, mesaure linkage non-consent bias, and perform small area estimation.
Administrative Records for Survey Methodology
Administrative Records for Survey Methodology — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Administrative Records for Survey Methodology», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The structural equation can be used to specify a generalized linear model of the observed sample cell counts, or their weighted totals, which allows one to estimate βand Y . It is further possible to develop the mixed-effects modeling approach that is popular in small area estimation, by introducing the mixed structural equation
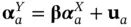
with the same quantities and the additional random effects u a= ( u a1, …, u aJ) T, where 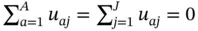 . The associated uncertainty will now be evaluated under the postulated model. The prediction modeling approach can thus improve on the survey weighting approach in the presence of empty and very small sample cells.
. The associated uncertainty will now be evaluated under the postulated model. The prediction modeling approach can thus improve on the survey weighting approach in the presence of empty and very small sample cells.
For an example under the asymmetric-unlinked setting, consider the Norwegian register-based household statistics. At the time the household register was first introduced for the year 2005, there were still about 6% persons with missing dwelling identification in the Central Population Register. As the missing rate differed by local areas as well as household types, direct tabulation did not yield acceptable results compared to the Census 2001 outputs. The IPF was applied to the sub-population of households that have the dwelling identification to yield a weight for every such household. The method falls under the benchmarked adjustment approach. However, direct evaluation of the associated uncertainty is not straightforward. Zhang (2009b) extends the prediction modeling approach above to accommodate the informative missing data. By comparison with the model-based predictions, one is able to assess indirectly the benchmarked adjustment results.
Using the IPF for small area estimation is known as structure preserving estimation (SPREE, Purcell and Kish 1980). The model underpinning the SPREE is a special case of the prediction models mentioned above, i.e. by setting β= 1. It does not require linkage between the proxy data X and the data that yield the benchmarks Y a+and Y +i. While this is convenient for deriving the estimates, a difficulty arises when it comes to uncertainty evaluation directly under the SPREE model. See also Dostál et al. (2016) for a benchmarked adjustment method based on the chi-squared measure in this respect.
Finally, let Y by ethnicity and party votes be the table of interest. Suppose one can obtain 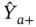 and Y +jin an election, but there are no joint observations of the cells ( a , j ). This can be framed as a problem of statistical matching. Provided a proxy table X , say, ethnicity by party membership, the IPF can be applied to obtain an estimated table
and Y +jin an election, but there are no joint observations of the cells ( a , j ). This can be framed as a problem of statistical matching. Provided a proxy table X , say, ethnicity by party membership, the IPF can be applied to obtain an estimated table 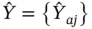 . Zhang (2015a) develop an uncertainty measure that combines the identification uncertainty and the sampling uncertainty in this context, which enables one to quantify the relative efficiency of the proxy data X , compared to statistical matching without X . The application of the IPF here is an example of the benchmarked adjustment approach.
. Zhang (2015a) develop an uncertainty measure that combines the identification uncertainty and the sampling uncertainty in this context, which enables one to quantify the relative efficiency of the proxy data X , compared to statistical matching without X . The application of the IPF here is an example of the benchmarked adjustment approach.
1.3.3 Symmetric Setting
In the symmetric setting none of the proxy variables is ideal due to errors of relevance, measurement, or coverage. The two most common approaches under the symmetric-linked setting are capture–recapture methodology for population size estimation and Structural Equation Modeling (SEM) that covers the latent class models mentioned earlier.
Capture–recapture methods that originate from wide-life, social, and medical applications are traditionally used for under-count adjustment. Imagine catching fish in a pond on two separate occasions, where one marks and identifies the fish that happen to be caught on both occasions (i.e. the recaptures). Then, under a number of simplifying assumptions, including independent and constant-probability captures, it becomes possible to estimate the total number of fish in the pond (i.e. the target population), for which the captures on each occasion generally entail undercounts. The method can be generalized to multiple captures to allow for relaxation of the independent assumption. The capture probability can be modeled using covariates to allow for heterogeneity across different subpopulations. See, e.g. Böhning, Van der Heijden, and Bunge (2017), for some recent developments.
Combining survey and register-based enumerations for population size estimation has attracted growing interest in the recent years, under the assumption that none of the sources can yield the true target population enumeration directly. We refer to the Journal of Official Statistics (2015, vol. 31, issue 3) for several useful references in this regard. There is plenty of scope for developing a range of models in order to address the different problems, including erroneous enumerations that are not dealt with in the traditional capture–recapture methodology. The potential impact can be huge if it enables one to produce census-like population statistics without the traditional census.
SEM is often considered to have evolved from the genetic path modeling of Sewall Wright. See, e.g. Kline (2016) for a general introduction. The approach is popular in many social science disciplines that share a common interest in “latent constructs” such as intelligence, attitude, well-being, living standard, and so on. The postulated latent constructs cannot be measured directly and are only manifested through observable indicators. The SEM consists of two main components: the structural model showing potentially causal dependencies among the latent variables, and the measurement model relating the latent variables and their indicators. The approach can be referred to in different ways depending on the continuous-categorical nature of the variables involved, the presence of causality or stochastic process on the latent level, etc.
The SEM approach is applicable under the symmetric-linked setting, where the proxy variables are treated as the indicators of the unobserved target measure. In the context of combining register and survey data, this can serve a number of purposes, including assessing potential relevance bias of proxy measures, detecting and possible treatment of measurement errors in editing and estimation, and statistical analysis of latent relationships using proxy indicators. For examples of data types that have been studied recently, see e.g. Pavlopoulos and Vermunt (2015) for temporary employment, Guarnera and Varriale (2015) for labor cost, and Burger et al. (2015) for turnover.
Di Cecco et al. (2018) apply latent class models for population size estimation based on multiple register enumerations that entail both over and under-counts. It is intriguing to notice the connection with some recent developments in record linkage. Imagine K lists of records, where each record may or may not refer to a target population unit (i.e. latent entity). Provided the union of the lists entail only over-counts of the target population, a potential alternative approach is record linkage, also referred to as entity resolution or co-reference – see e.g. Stoerts, Hall, and Fienberg (2015). The records in the same list that refer to the same entity represent duplicated enumerations; the records in the different lists that refer to the same entity can be conceived as the target for record linkage. The errors in compiling the population total are then the potential de-duplication and record linkage errors, which are traditionally the topics of computerized record linkage.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Administrative Records for Survey Methodology»
Представляем Вашему вниманию похожие книги на «Administrative Records for Survey Methodology» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Administrative Records for Survey Methodology» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.