Erik Cuevas Jiménez - Introducción al Machine Learning con MATLAB
Здесь есть возможность читать онлайн «Erik Cuevas Jiménez - Introducción al Machine Learning con MATLAB» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Introducción al Machine Learning con MATLAB
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Introducción al Machine Learning con MATLAB: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Introducción al Machine Learning con MATLAB»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
En la última década, el número de usuarios de Machine Learning ha crecido de forma espectacular, pero muchos han presentado grandes dificultades a la hora de generar un plan adecuado que les permita pasar de los conceptos fundamentales a la solución de problemas en sus áreas de interés. El objetivo de este libro es brindar una visión particular de los principales métodos de Machine Learning y de su implementación, es decir, proveer de los principales conceptos en los que se basan estos métodos y aplicarlos a problemas típicos del procesamiento de datos.
El libro se fundamenta en MATLAB, el cual es considerado hoy en día como un estándar en la programación científica e industrial. MATLAB contiene, dentro de sus funciones, poderosos métodos numéricos que pueden ser adaptados a aplicaciones particulares. Bajo estas condiciones, el usuario puede estar más concentrado en la estructura de su aplicación que en la programación misma.
Asimismo, el libro es el resultado de un desmantelamiento completo del plan de estudios estándar del Machine Learning en sus componentes más fundamentales, así como de un reensamblaje de esas piezas, cuidadosamente pulidas y organizadas. Contiene descripciones intuitivas y, a su vez, rigurosas de los conceptos imprescindibles para analizar información a partir de datos. Todo esto deviene en una lectura que le permitirá:
–Entender los principales conceptos en los que se basa el Machine Learning.
–Implementar los métodos de Machine Learning.
–Usar los diferentes recursos online que incluyen código fuente y bases de datos.
–Comprender las principales técnicas de programación con MATLAB orientadas a la implementación de aplicaciones de Machine Learning.
Sin importar si tiene poca o mucha experiencia en programación, con este libro obtendrá las habilidades teóricas y prácticas para emplear el Machine Learning en su totalidad. Hágase con su ejemplar y descubra los detalles estructurales de la información de sus propios proyectos para predecir y manipular con precisión su comportamiento futuro.
Introducción al Machine Learning con MATLAB — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Introducción al Machine Learning con MATLAB», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
R = rmmissing(D1)
La ejecución de la función rmmissing con el argumento D1 entregará el resultado que se muestra en la figura 1.5.

Figura 1.5. Resultado de eliminar las instancias con valores faltantes en la tabla D1.
Tratamiento de datos atípicos
Los datos atípicos son los valores extremos que se presentan en ciertas observaciones; generalmente, es necesario tratarlos, ya sea eliminándolos o transformándolos. La función isoutlier de MATLAB toma un argumento de entrada, ya sea una tabla, matriz o vector D. Esta función devuelve una matriz o vector lógico AD, cuyos elementos verdaderos corresponden a la detección de valores atípicos. Esta función tiene la siguiente sintaxis:
AD = isoutlier(D)
Por defecto, se considera que un valor es atípico cuando se encuentra alejado a más de tres desviaciones absolutas de medianas (DAM) escaladas. Si D es una matriz o tabla, entonces isoutlier opera en cada columna por separado.
En el presente ejemplo se eliminarán los valores atípicos encontrados en las observaciones VD. Se parte del vector de observaciones VD, que contiene los valores atípicos. La función isoutlier detecta qué elementos son valores atípicos, dado el criterio DAM, y los guarda en AD. Las observaciones atípicas se eliminarán del vector de observaciones usando la siguiente expresión:
VD(AD)=[]
Lo que realiza esta expresión es eliminar las posiciones correspondientes a los valores de verdadero de AD. El ejemplo completo se presenta a continuación en el algoritmo 1.3:
% Autores: Erik Cuevas, Omar Avalos, Arturo Valdivia y Primitivo Díaz
% Se define un vector de datos
VD = [59 58 48 51 55 91 64 63 50 95];
% Se procesa el vector DS para la detección de valores atípicos
[AD] = isoutlier(VD);
% Se eliminan los valores atípicos
VD(AD)=[]
VD = 59 58 48 51 55 64 63 50
Cuando se cuenta con suficientes observaciones es posible eliminar observaciones con valores atípicos; sin embargo, cuando las observaciones son reducidas, los datos atípicos deben ser transformados para evitar reducir el conjunto de observaciones. Dentro del entorno de MATLAB, se puede encontrar la función filloutliers, la cual toma como argumento a D, que puede ser una tabla, matriz o vector, además de un parámetro llamado 'MetododeLlenado',con el que se especifica qué método se utilizará para sustituir los valores atípicos encontrados bajo el criterio DAM:
[F,Ui,Us,C] = filloutliers(D,'MetododeLlenado');
Con la función filloutliers se buscan los valores atípicos existentes en D bajo el criterio DAM, y se reemplazan los valores atípicos empleando una metodología de llenado que especifica el usuario. A continuación, en la tabla 1.2, se presentan los posibles valores que puede tomar el 'MetododeLlenado'.
| Escalar | Llena los datos atípicos con un dato escalar |
| 'center' | Llena los datos atípicos con el centro del criterio DAM |
| 'clip' | Llena los datos atípicos con el valor umbral inferior para elementos más pequeños que el umbral inferior determinado por el criterio DAM Llena con el valor de umbral superior para elementos mayores que el límite superior determinado por el criterio DAM |
| 'previous' | Llena los datos atípicos con el valor anterior no atípico |
| 'next' | Llena los datos atípicos con el valor siguiente no atípico |
| 'nearest' | Llena los datos atípicos con el valor más cercano no atípico |
| 'linear' | Llena los datos atípicos empleando la interpolación lineal de los valores no atípicos vecinos |
| 'spline' | Llena los datos atípicos empleando la interpolación de spline cúbico por parte de los valores no atípicos vecinos |
| 'pchip' | Llena los datos atípicos empleando la interpolación cúbica polinomial de los valores no atípicos vecinos |
Tabla 1.2. Posibles valores que toma el método de llenado.
La función filloutliers retornará cuatro valores: F es el vector resultante sin valores atípicos; Ui, el umbral inferior del criterio DAM; Us, el umbral superior del criterio DAM; y C, el centro del criterio DAM, que corresponde a la mediana de los datos.
A continuación, en el algoritmo 1.4, se muestra un ejemplo para rellenar datos atípicos empleando la función filloutliers, donde se aplica el parámetro ‘linear’, para que los datos atípicos sean reemplazados por valores generados de una interpolación lineal de los valores vecinos que no sean atípicos. De forma adicional, se grafican los umbrales del criterio DAM y del centro de las observaciones:
% Autores: Erik Cuevas, Omar Avalos, Arturo Valdivia y Primitivo Díaz
% Vector de observaciones
D = [59 58 48 51 55 101 64 63 50 20];
% Se contabiliza cuántos elementos tiene el vector D
N=numel(D);
% Se define el vector del eje x
x = 1:N;
% Se rellenan los avalores atípicas del vector D
[F,TF,Ui,Us,C] = filloutliers(D,'linear');
% Se grafica de forma comparativa los datos originales contra los
% datos generados por filloutliers del vector D
plot(x,D,x,F,'o',x,Ui*ones(1,N),x,Us*ones(1,N),x,C*ones(1,N))
legend('Datos originales','Datos transformados','Umbral...
inferior','Umbral superior','Centro de los datos')
Algoritmo 1.4. Ejemplo del uso de la función filloutliers en MATLAB.
En la figura 1.6se puede visualizar el gráfico generado por el algoritmo 1.4. La línea azul representa los datos originales, mientras que los datos procesados se muestran por medio de los círculos naranjas. Además, el color morado indica el umbral superior; el color amarillo se encuentra el umbral inferior, y el interlineado verde representa el centro de las observaciones.
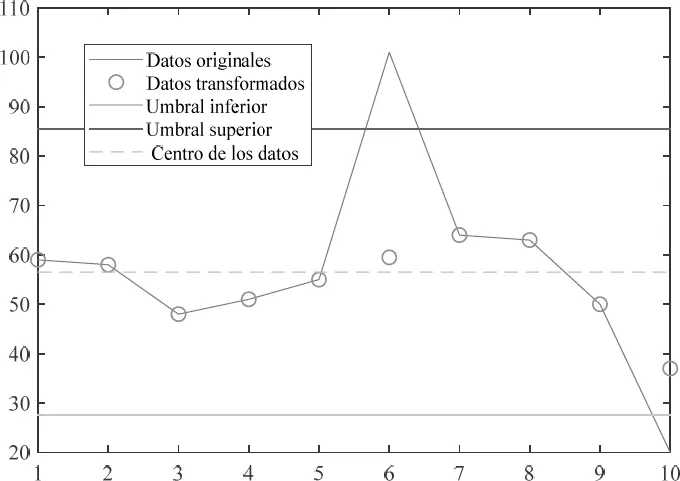
Figura 1.6. Procesamiento de datos atípicos por filloutliers.
1.9. Visualización de datos
El objetivo principal de las técnicas de visualización de datos consistirá en partir de información compleja y presentarla en un formato simple, y, de esta manera, entender mejor la información disponible. La visualización de datos permite su inspección y una mejor comprensión de esta. Existen otros motivos para usar la visualización de datos. Incluyen los siguientes:
• Explicar los datos o poner los datos en contexto
• Resolver un problema específico (por ejemplo, identificar áreas problemáticas dentro de un modelo de negocio particular)
• Resaltar o ilustrar datos que, de otro modo, serían invisibles (como aislar valores atípicos existentes en los datos)
• Destacar la tendencia de los datos, como los volúmenes de ventas potenciales
La visualización se utiliza en casi todos los pasos del proceso del aprendizaje máquina, dentro de pasos obvios como la preparación y exploración de datos, pero también puede ser aprovechada durante la recopilación de datos, durante el entrenamiento del modelo y en la etapa final de evaluación de resultados, para identificar elementos relevantes.
El conjunto de datos sobre la flor de iris es una colección de observaciones multivariante para cuantificar la variación morfológica de las tres especies relacionadas de flores de iris: setosa, versicolor y virginica. El conjunto de datos tiene las mediciones del largo y ancho del sépalo y el pétalo de la flor de iris. En la figura 1.7se presenta la estructura de la flor de iris. Tomaremos este conjunto de datos para explorarlos visualmente, debido a que es un referente en el área del aprendizaje máquina y estadística.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Introducción al Machine Learning con MATLAB»
Представляем Вашему вниманию похожие книги на «Introducción al Machine Learning con MATLAB» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Introducción al Machine Learning con MATLAB» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.