Joan Pallerola Comamala - Excel y SQL de la mano
Здесь есть возможность читать онлайн «Joan Pallerola Comamala - Excel y SQL de la mano» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Excel y SQL de la mano
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Excel y SQL de la mano: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Excel y SQL de la mano»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
En este libro encontrará los conceptos necesarios para interrelacionar uno de los programas sencillos con más posibilidades del mercado, la hoja de cálculo Excel, con otras hojas y otros libros, con otras bases de datos en Microsoft Access o en dBASE, en ficheros de texto o en SQL Server.
Sin duda, el contenido del libro deviene un medio imprescindible para ahorrarle tiempo y facilitarle su trabajo, pues trata desde el propio análisis de la base de datos hasta lo más manual, como la obtención, la copia, la selección y los filtros desde y hacia otras bases.
Asimismo, con el código de descarga que se facilita en la primera página del libro, podrá contar con ejemplos reales y poner en práctica todo lo aprendido sobre Excel, el lenguaje SQL y mucho más.
Gracias a este libro y a las herramientas que desarrolla, encontrará siempre una nueva idea, explicación o causa a todo lo que envuelve a sus bases de datos. No espere más y adéntrese sin miedo en el campo de las bases de datos para proveer a su trabajo del prestigio que merece.
Excel y SQL de la mano — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Excel y SQL de la mano», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Mejora en la accesibilidad a los datos.Muchos SGBD proporcionan lenguajes de consultas o generadores de informes que permiten al usuario hacer cualquier tipo de consulta sobre los datos, sin que sea necesario que un programador escriba una aplicación que realice tal tarea.
Mejora en la productividad.El SGBD proporciona muchas de las funciones estándar que el programador necesita escribir en un sistema de ficheros. A nivel básico, el SGBD proporciona todas las rutinas de manejo de ficheros típicas de los programas de aplicación. Al programador, el hecho de disponer de estas funciones le permite centrarse en la función específica requerida por los usuarios, sin tener que preocuparse de los detalles de implementación de bajo nivel.
Mejora en el mantenimiento.En los sistemas de ficheros, las descripciones de los datos se encuentran inmersas en los programas de aplicación que los manejan. Esto hace que los programas sean dependientes de los datos, de modo que un cambio en su estructura, o un cambio en el modo en que se almacena en disco, requiere cambios importantes en los programas cuyos datos se ven afectados. Sin embargo, los SGBD separan las descripciones de los datos de las aplicaciones. Esto es lo que se conoce como independencia de datos, gracias a la cual se simplifica el mantenimiento de las aplicaciones que acceden a la base de datos.
Aumento de la concurrencia.En algunos sistemas de ficheros, si hay varios usuarios que pueden acceder simultáneamente a un mismo fichero, es posible que el acceso interfiera entre ellos de modo que se pierda información o se pierda la integridad. La mayoría de los SGBD gestionan el acceso concurrente a la base de datos y garantizan que no ocurran problemas de este tipo.
Mejora en los servicios de copias de seguridad.Muchos sistemas de ficheros dejan que sea el usuario quien proporcione las medidas necesarias para proteger los datos ante fallos en el sistema o en las aplicaciones. Los usuarios tienen que hacer copias de seguridad cada día y, si se produce algún fallo, utilizar estas copias para restaurarlas. En este caso, todo el trabajo realizado sobre los datos desde que se hizo la última copia de seguridad se pierde y se tiene que volver a realizar. Sin embargo, los SGBD actuales funcionan de modo que se minimiza la cantidad de trabajo perdido cuando se produce un fallo.
1.2.2 Desventajas de las bases de datos
Complejidad.Los SGBD son conjuntos de programas que pueden llegar a ser complejos con una gran funcionalidad. Es preciso comprender muy bien esta funcionalidad para poder realizar un buen uso de ellos.
Coste del equipamiento adicional.Tanto el SGBD como la propia base de datos pueden hacer que sea necesario adquirir más espacio de almacenamiento. Además, para alcanzar las prestaciones deseadas, es posible que sea necesario adquirir una máquina más grande o que se dedique solamente al SGBD. Todo esto hará que la implantación de un sistema de bases de datos sea más cara.
Vulnerable a los fallos.El hecho de que todo esté centralizado en el SGBD hace que el sistema sea más vulnerable ante los fallos que puedan producirse. Por ello, deben tenerse copias de seguridad, llamadas backup.
1.3 TIPOS DE BASES DE DATOS
Entre los diferentes tipos de base de datos, podemos encontrar los siguientes:
MySql:Es una base de datos con licencia GPL (General Public License), aunque solo en parte, basada en un servidor. Se caracteriza por su rapidez. No es recomendable para grandes volúmenes de datos.
PostgreSql y Oracle:Son sistemas de base de datos poderosos. Administran muy bien grandes cantidades de datos, y suelen ser utilizadas en intranets y sistemas de gran calibre.
Access:Es una base de datos desarrollada por Microsoft. Esta base de datos debe ser creada bajo el programa Microsoft Access, el cual crea un archivo .mdb o .accdb .
Microsoft SQL Server:Es una base de datos más potente que Access desarrollada por Microsoft. Se utiliza para manejar grandes volúmenes de informaciones.
Estas bases de datos poseen muchos elementos en común, y todas ellas con el siguiente orden jerárquico:
1. Tablas
2. Campos
3. Registros
4. Lenguaje SQL
El lenguaje SQL es el más universal en los sistemas de base de datos. Este lenguaje permite realizar consultas a las bases de datos para mostrar, insertar, actualizar y/o borrar información.
Cada base de datos se compone de una o más tablas que guardan un conjunto de datos. Cada tabla se compone de una o más columnas, llamadas campos, y también de filas, que se denominan registros. Las columnas o campos guardan una parte de la información y el conjunto de campos conforman un registro, de acuerdo con el siguiente gráfico:

Los campos que se pueden ver en la figura anterior, cuyo nombre es DIARIO, son FECHA, SUBCTA, CONCEPTO, DEBE, HABER, MES y 3DIG.
El conjunto de estos campos conforma un registro. El registro carece de nombre; solo tiene un número de orden, que será el que tenga porque le toca, pero se podrán ordenar con base en distintos criterios.
En este caso se podría ordenar por FECHA o por SUBCTA, o por la combinación de varios campos, subordinados los posteriores a los anteriores. Sería el caso de ordenar por FECHA y luego por SUBCTA.
El lenguaje que sirve para realizar estas operaciones es el lenguaje SQL, que tiene variantes según las bases de datos. No es exactamente el mismo el que se utiliza en SQL Server del que se utiliza en MySql o Access, a pesar de que algunos programas o sistemas sean de un mismo fabricante. Aunque, frente a esta dificultad, la ventaja es que son muy parecidos. Sirva esto de consuelo.
Si se quiere enlazar datos de una tabla con otra, aparecen las CONSULTAS o QUERIES. Para ello debe haber un campo en cada tabla que sirva de nexo entre ellas. Sería el caso del campo SUBCTA en la figura vista anteriormente, con el campo CUENTA en una tabla del plan de cuentas. De esta manera, de una forma práctica se evitará la redundancia de datos.
Y otra ventaja de las consultas es que, establecido el nexo, se pueden seleccionar todos los campos de ambas tablas o los campos de una u otra que se necesiten. Y, además, se pueden crear nuevos campos que provengan de los existentes: podría ser el caso de un nuevo campo que podría llamarse AÑO, obtenido por la aplicación de la función YEAR sobre el campo FECHA.
El tratamiento de la consulta obtenida sería parecido al que se realiza en una tabla existente. Y la consulta, que tal y como se ha explicado se ha realizado vinculando dos tablas, se podría hacer con más tablas.
Y, en lugar de un solo nexo, puede haber varios:
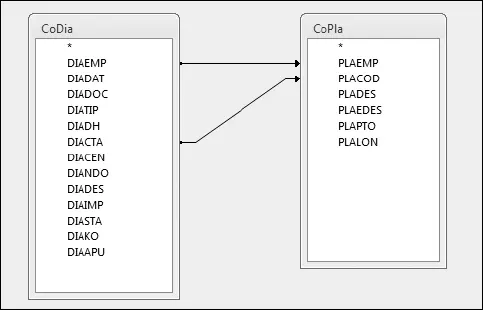
En este caso, se relacionan dos tablas: CoDia y CoPla. Una es un diario contable que tiene el código de cuenta en DIACTA, al que le falta la descripción, que está en CoPla, para evitar redundancias. Si se modifica esta descripción en CoPla, quedará modificada en todas las consultas que se hagan porque en estas se relaciona la empresa con el código de cuenta.
La flecha indica que en el caso de que no se encuentre la correspondiente cuenta de CoDia en CoPla, se muestre la cuenta de CoDia sin descripción. Si no hubiese ninguna flecha, solo se mostrarían los campos coincidentes. Más adelante, en el capítulo dedicado a las consultas de Access o del Query de Excel, ya se verá cómo se indica esta condición.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Excel y SQL de la mano»
Представляем Вашему вниманию похожие книги на «Excel y SQL de la mano» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Excel y SQL de la mano» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.