Semantic Web for Effective Healthcare Systems
Здесь есть возможность читать онлайн «Semantic Web for Effective Healthcare Systems» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Semantic Web for Effective Healthcare Systems
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Semantic Web for Effective Healthcare Systems: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Semantic Web for Effective Healthcare Systems»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The aim of this book is to analyze the current status on how Semantic Web is used to solve the health data integration and interoperability problem, how it provides advanced data linking capabilities that can improve search and retrieval of medical data. There are chapters in the book which analyze the tools and approaches to semantic health data analysis and knowledge discovery. The book discusses the role of semantic technologies in extracting and transforming healthcare data before storing it in repositories. It also discusses different approaches for integrating heterogeneous healthcare data. To summarize, the book will help readers understand key concepts in semantic web applications for biomedical engineering and healthcare.
Semantic Web for Effective Healthcare Systems — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Semantic Web for Effective Healthcare Systems», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
For LDA model, the number of topics K has to be fixed in prior. It assumes the generative process for a document w = (w 1, . . . ,w N) of a corpus D containing N words from a vocabulary consisting of V different terms, w ϵ {1, …, V} for all i = {1, … , N}. LDA consists of the following steps [12]
1 (1) For each topic k, draw a distribution over words Φ(k) ~ Dir(α).
2 (2) For each document d,(a) Draw a vector of topic proportions θ(d) ~ Dir(β).(b) For each word i,(i) Draw a topic assignment zd,i ~ Mult(θd), zd,n ϵ {1, …, K},(ii) Draw a word wd,i ~ Mult(Φz d,i), wd,i ϵ {1, …, V}
where α is a Dirichlet prior on the per-document topic distribution, and β is a Dirichlet prior on the per-topic word distribution. Let θ tdbe the probability of topic t for document d , z dibe the topic distribution, and let Φ twbe the probability of word w in topic t . The probability of generating word w in document d is:
(1.2) 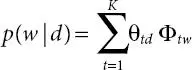
Equation 1.2gives the weighted average of the per-topic word probabilities, where the weights are the per-document topic probabilities. The resulting distribution p(w|d) varies from document to document, as the topic weights change among documents. Corpus documents are fitted into LDA model by inferring a collection of hidden variables. These variables are denoted by θ = {θ td}, the |K| × |D| matrix of per-document topic weights, and Φ = {Φ tw}, the |K| × |N| matrix of per-topic word weights. Inference for LDA is the problem of determining the joint posterior distribution of θ and Φ after observing a corpus of documents, which are influenced by LDA parameters.
Simple LDA model gives term-topic probabilities for all terms under each topic. According to literature [59, 60], only the top 5 or 10 terms under each topic were selected for modeling. However, the CFS LDAmodel (Contextual Feature Selection LDA) selects the set of probable terms from the data set which represent the topic or concept of a domain. It builds the contextual model using LDA and correlation technique for selecting the list of probable and correlated terms under each topic (or feature) for the data set. The lists of terms represent the topic or concept of a domain and establish the context between the terms. The plate notation of CFS LDAtopic modeling is shown in Figure 1.7. The notations used in CFS LDAmodel are:
D—number of documents
N—number of words or terms
K—number of topics
α—a Dirichlet prior on the per-document topic distribution
β—a Dirichlet prior on the per-topic word distribution
θtd—probability of topic t for document d
Φtw—probability of word w in topic t
zd,i—topic assignment of term “i”
wd,i—word assignment of term “i”
C—correlation between the terms
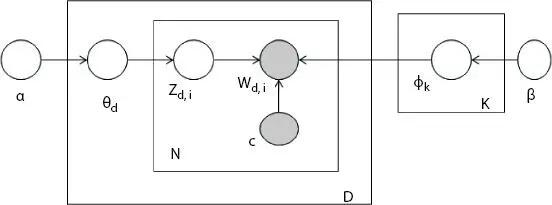
Figure 1.7 Plate notation of CFS LDAmodel.
LDA associates documents with a set of topics where each topic is a set of words. Using the LDA model, the next word is generated by first selecting a random topic from the set of topics T, then choosing a random word from that topic's distribution over the vocabulary W. The hidden variables θ and Φ are determined by fitting the LDA model to a set of corpus documents. CFS LDAmodel uses Gibbs sampling for performing the topic modeling of text documents. Given values for the Gibbs settings (b, n, iter), the LDA hyper-parameters (α, β, and k), and TD matrix M, a Gibbs sampler produces “n” random observations from the inferred posterior distribution of θ and Φ [60].
Here Gibbs parameters include “b” —burn-in iterations, “n” —number of samples, and “iter” —number of sample intervals. Gibbs sequences produce θ and Φ from the desired distribution, but only after a large number of iterations. For this reason, it is necessary to discard (or burn) the initial observations “b” [60]. The Gibbs setting “n” determines how many observations from the two Gibbs sequences are kept. The setting “iter” specifies how many iterations the Gibbs sampler runs before returning the next useful observation [60]. The procedure CFS LDAmodel is shown:


1.5 Ontology Development
Ontology development includes various approaches like Formal Concept Analysis (FCA) or Ontology Learning. FCA applies a user-driven step-by-step methodology for creating domain models, whereas Ontology learning refers to the task of automatically creating domain Ontology by extracting concepts and relations for the given data set [27]. This chapter focuses on building an automatic semantic indexer for online product/service reviews using Ontology. The representation of documents is semantically and contextually enriched by using the Context Feature Selection LDA (CFS LDA) topic modeling technique. Search query yields improved relevant results thereby increases the recall value [26, 27].
The problem statement is simply stated as “to extract all probable relevant features from the Corpus.” Given a set of terms for each feature (or topic), the objective is to construct index, which is embedded in the Ontology so as to reduce query processing time. Ontology-based Semantic Indexing (OnSI) model includes three main processes like semantic indexing, Ontology development, and evaluation, as shown in Figure 1.8.
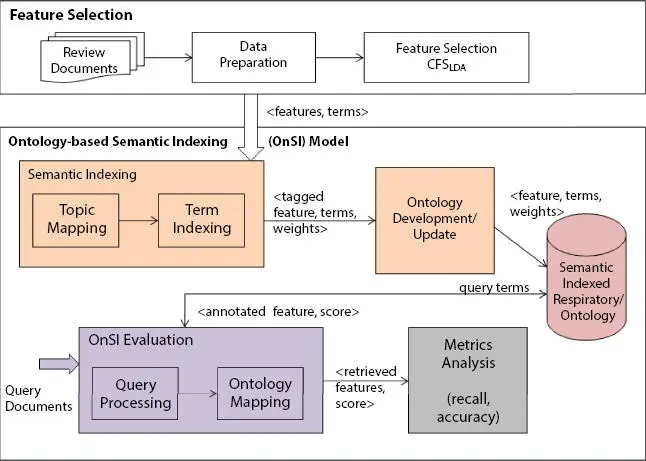
Figure 1.8 Ontology-based semantic indexing (OnSI) model.
The semantic indexing module includes topic mapping, and term indexing. Ontology development module populates Ontology with these terms and their weights (LDA weights). OnSI evaluation module evaluates the built Ontology through query processing.
1.5.1 Ontology-Based Semantic Indexing (OnSI) Model
Semantic indexing module builds indexer for the review documents with the support of CFS LDAmodel. The topic modeling technique CFS LDAis used in the feature selection process to extract the features (or topics) and their related terms. Those terms that are grouped under the same topic are selected and tagged to represent the features of domain (or concept). Finally, the index is built using the keywords representing the features and feature terms with their context.
Definition 1: Context is defined as a triplet < F, T, M >. F is the set of features, T is set of terms and their LDA scores, and M is the relationship between T and F, known as Ontology mapping. In other words, T is the set of terms used to describe F features of concept. Their contextual relationship is identified by M, a mapping function between T and F using the score.
1.5.2 Ontology Development
A topic (or feature) is a duplet , F is the set of features of the domain and T is the candidate set of terms representing F. CFSLDA model selects T = {tc | tc is correlated with tp}, where tp is the higher probable term of F selected by the model. The contextual relationship between this duplet is represented by the triplet , where M represents the mapping between F and T. The Ontology development or update procedure is shown:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Semantic Web for Effective Healthcare Systems»
Представляем Вашему вниманию похожие книги на «Semantic Web for Effective Healthcare Systems» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Semantic Web for Effective Healthcare Systems» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.