Semantic Web for Effective Healthcare Systems
Здесь есть возможность читать онлайн «Semantic Web for Effective Healthcare Systems» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Semantic Web for Effective Healthcare Systems
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Semantic Web for Effective Healthcare Systems: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Semantic Web for Effective Healthcare Systems»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The aim of this book is to analyze the current status on how Semantic Web is used to solve the health data integration and interoperability problem, how it provides advanced data linking capabilities that can improve search and retrieval of medical data. There are chapters in the book which analyze the tools and approaches to semantic health data analysis and knowledge discovery. The book discusses the role of semantic technologies in extracting and transforming healthcare data before storing it in repositories. It also discusses different approaches for integrating heterogeneous healthcare data. To summarize, the book will help readers understand key concepts in semantic web applications for biomedical engineering and healthcare.
Semantic Web for Effective Healthcare Systems — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Semantic Web for Effective Healthcare Systems», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Table 1.6 List of correlated feature terms selected by CFS LDAmodel.
| Features of DS1 | Number of terms selected by CFSLDA | Correlated feature terms by CFSLDA model (DS1) |
| Cost | 68 | cost, test, money, charge, day, case, department, patient, room, pay, bill, ... |
| Medicare | 110 | doctor, discharge, medicine, treatment, appointment, admission, disease, option, pain, reply, duty, test, meeting, … |
| Staff | 112 | staff, patient, medicine, problem, report, manner, management, treatment, complaints, … |
| Infrastructure | 101 | hospital, room, facility, meals, rate, … |
| Time | 73 | time, service, hour, operation, day, bill, ... |
Thus, the feature extraction process model, the CFS LDAmodel, selects not only the terms with high term-topic probability value but also the terms which are highly correlated with the topmost term under each topic , which are contextually equivalent . The terms which are positively correlated with the top probable term are selected for the list. The topic name, the set of terms, and their LDA score are given to the Ontology builder tool for repository. Figure 1.11shows the spring view of domain Ontology built for Healthcare service reviews (DS1).
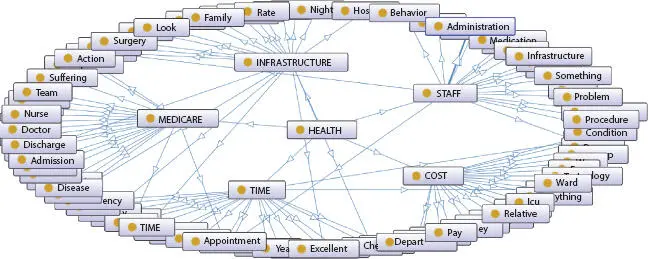
Figure 1.11 Spring view of domain ontology (DS1).
Figure 1.12shows the precision vs recall value curve and f-measure value when OnSI model is used on different query documents. It shows that recall improves continuously for higher number of query documents. When the document size is 500, OnSI model gives precision 0.61 , recall 0.53 , and F-measure 0.57 values.
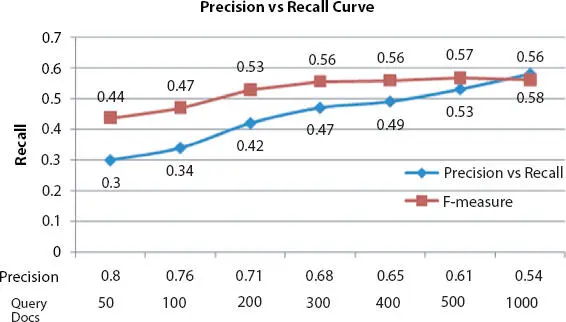
Figure 1.12 Precision vs recall curve for the Dataset DS1.
1.7.1 Discussion 1
Ontology querying involves direct extract of feature from its repository instead of doing similarity measures as other techniques like Naive Bayes algorithm do. The similarity between the terms is incorporated into the model during the CFS LDAmodelling technique itself rather than the querying phase. It is very much required as the lexicon-based indexing technique just uses the keywords with one-to-one mapping and it does not look for synonymous terms and contextually related terms. OnSI model retrieves these types of terms from the document collection for the features or topics, which in turn improves the recall value. 100% accuracy may not be attained sometimes, as some of the terms present in query documents may not be present in the Ontology and it may need to be updated. In the next iteration, the value gets improved.
1.7.2 Discussion 2
Time taken for modeling and querying (training and testing) text documents are measured. OnSI model takes 2.1 s for modeling (70% of DS1) and 0.35 s for querying (30% of DS1). The use of Sparql language in OnSI model greatly reduces the time for query processing. The time complexity of querying depends on the number of terms present in the documents and number of times each term conflicts with other topics. OnSI model of extracting features were compared with Naive Bayes classifier and k-Means clustering techniques, and the results are shown in Table 1.7.
Table 1.7 Performance evaluation.
| Technique | Recall | Accuracy | Time |
| Naive Bayes Classifier | 30% | 69% | 3.98 s |
| k-Means Clustering | 37% | 79% | 4.25 s |
| OnSI (Ontology-based CFS LDA) | 57% | 88% | 2.45 s |
1.7.3 Discussion 3
Generally, the term-document (TD) matrix is stored in .csv format which takes megabytes of storage whereas the .owl format, the Ontology file, takes only kilo bytes of storage. For example, size of .csv file was 3.5 MB (approx.) when review documents were converted into TD matrix for the dataset DS1. Each review document consumes 1 kB (approx.) storage and also it depends on the number of terms present in the dataset. However, DS1 takes only 360 kB (approx.) when .owl format is used.
This chapter focused on building of Ontology for the contextual representation of user-generated content, i.e., the review documents . The contextually aligned documents are represented in domain Ontology along with the semantics using the Ontology-based Semantic Indexing (OnSI) model.
It has been identified that the modeling of documents greatly impacts the query processing time and its recall value. The OnSI model improves the recall value by 27% and reduces the time by 1.53 s , when compared Naïve Bayes technique. Similarly, it improves the recall value by 20% and reduces the time by 1.8 s , when compared with k-means algorithm. The LDA parameters and the right choice of their values along with the correlation analysis involved in the CFS LDAfeature selection process improve the accuracy of model. Having the right of features in hand, the contextual feature-based sentiment analysis and predictive analytics are possible with the dataset using supervised machine learning techniques.
1.8 Applications
Much of the social media text research have been undertaken for ranking public/private sectors or products [41], for improving customer satisfaction [64], or for recommending new services of products [50]. Multi-Criteria Decision Making (MCDM) problem can be solved by using the OnSI model. Here OnSI model can be applied to extract the set of features from the given set of review documents. Ranking methods use suitable weights for each feature and the sentiment score from the sentiment analysis process. The MCDM hierarchy problem for determining the better healthcare service provider is shown in Figure 1.13.
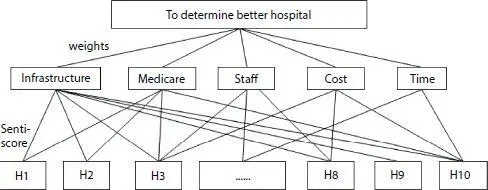
Figure 1.13 Hierarchy of MCDM problem.
There are many MCDM methods available like SAW (simple additive weight), TOPSIS, VIKOR and so on. This chapter focuses on applying VIKOR technique for determining the better hospital based on their features. VIKOR is one of the ranking methods for optimizing the multi-response process through compromise [42]. It compares the closeness of each criterion with the alternative and derives ranking index for each criterion. The core concept of VIKOR is that ranking the criteria from the set of different alternatives in the presence of conflicting criteria [43]. Figure 1.14shows the ranking of features for various alternatives (hospitals) under consideration.
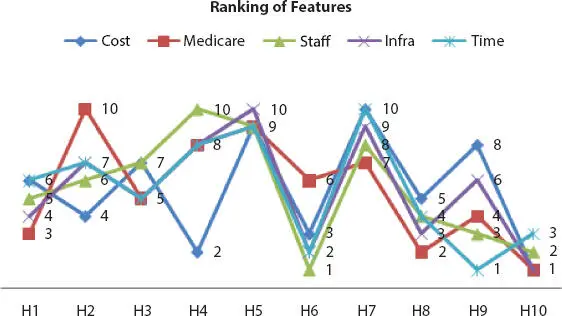
Figure 1.14 Ranking of features by VIKOR method.
Figure 1.7shows that the alternative H10 scored rank 1 for the features “Cost,” “Medicare,” and “Infrastructure,” the alternative H6 for the feature “Staff” and the alternative H9 for the feature “Time.” These data can be used for benchmarking by all the hospitals to improve their process.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Semantic Web for Effective Healthcare Systems»
Представляем Вашему вниманию похожие книги на «Semantic Web for Effective Healthcare Systems» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Semantic Web for Effective Healthcare Systems» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.