Data Mining and Machine Learning Applications
Здесь есть возможность читать онлайн «Data Mining and Machine Learning Applications» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Data Mining and Machine Learning Applications
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Data Mining and Machine Learning Applications: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Data Mining and Machine Learning Applications»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The book elaborates in detail on the current needs of data mining and machine learning and promotes mutual understanding among research in different disciplines, thus facilitating research development and collaboration.
Audience
Data Mining and Machine Learning Applications — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Data Mining and Machine Learning Applications», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
◦ Data source issuesData is collected from different sources, and it’s an incremental process. The number of data mining applications is increasing, which produces a large volume of data. It became a necessary task to store, process and categorized this large volume of data is a necessary task.
1.4 Data Mining Algorithms
Adaboost, KNN, PageRank, Naïve Bayes, Support Vector Machine (SVM), Apriori, and C 4.5 are some data mining algorithms. Data mining algorithms are primarily used for predictive modeling, which includes clustering and classification problems. Let us discuss each of them in detail [1–6].
Classification
It is a task in data mining where data can be modeled and distinguished into classes. One can say it is a process where given objects are classified/categorized to form a new class. Initially, the training set is identified, and new observations are derived. Hence, this task is classified into two phases, i.e., the learning/training phase and the classification of the given objects. E.g., a bank manager can wish to classify the loans borrowed by customers based on risky category, less risky category and trustworthiness, etc. To execute this classification technique on the given objects, the idea is to use classifier/s—where rules are applied, training is given, and given data is classified into the desired classes. The following are the classification algorithms that can be used in data mining:
Logistics regression
Naïve Bayes
K nearest
Decision tree
Random forest
Support Vector Model.
Clustering
It is a grouping of objects based on similarity. A threshold is applied, and an object can be added to the specific cluster where the criteria can be satisfied. This technique is helpful in various applications such as—
Market basket analysis
Pattern recognition
Image processing
Financial analysis.
It is categorized as unsupervised learning, where the given data is used to compare with the threshold (predefined value). The clustering approach can be categorized into intra-cluster and inter-cluster.
Types of Clustering
Clustering is nothing but a grouping of elements based on similarity and its unsupervised learning technique. One can apply partition clustering, which is also known as non-hierarchical clustering, to classify the data/records/values into ‘k’ groups/clusters. This is an iterative process and works until the last element is processed. Users can use the SVM model —support vector machine, where ‘n’ features will be identified in the initial phase, and then those features will be processed to identify the relevant results.
◦ K-means clustering algorithm can be used to train the samples. Using this clustering method, it is possible to identify the nearest cluster by training the samples. Training the samples is nothing but finding the distance between samples and the nearest clusters. Distance is calculated between the samples, and the sample with a larger distance is likely to be selected as a center point. (One can use Euclidean distance metric in this case). K-means stores centroids (‘k’ points) that it uses to define the clusters to be formed. An object/value is considered to be in a specific cluster if it is closer to that cluster’s centroid.
◦ Hierarchical: It is one of the popular algorithms used in data mining and machine learning. The idea is to find the two clusters which are closer to each other and merge them to form a single cluster. Repeat this process until all the desired clusters are merged. This is categorized into top-down and bottom-up approaches, i.e., known as agglomerative and divisive approaches. We can define this type as the nesting of clusters that can be nested together to form a tree (merged cluster).
◦ Fuzzy: Clusters are treated as fuzzy sets and allocate the objects to these clusters. It is unsupervised, and as its name suggests, one can check the probability of each point whether it belongs to multiple clusters instead of belonging to a single cluster. It is also treated as soft clustering. One of its popular applications is pattern recognition. Minimization of the objective function is its primary objective, and hence the number. of iterations may increase. As for the number of iterations are ‘n’, it may increase the time complexity of the algorithm.
1.5 Data Warehouse
It is a warehouse which means it collects data from multiple heterogeneous sources. It supports analytical data processing and helps in decision-making. As data is collected from various sources, before storing this data into the warehouse ( Table 1.1), data cleaning, data integration, and data consolidation, etc., steps must be performed and represented in Figure 1.3[18]. Data warehouse properties are as follows:
Table 1.1 Comparison in a data warehouse—OLTP.
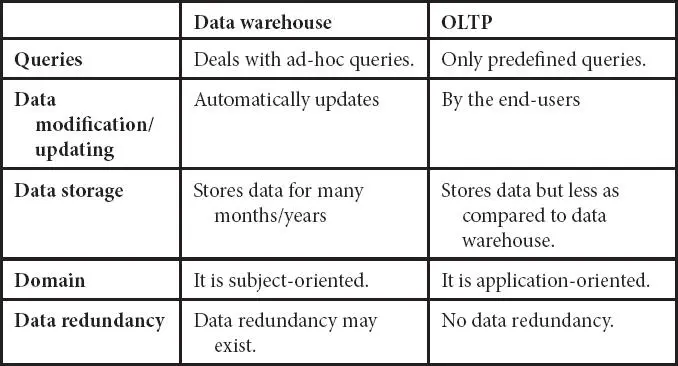
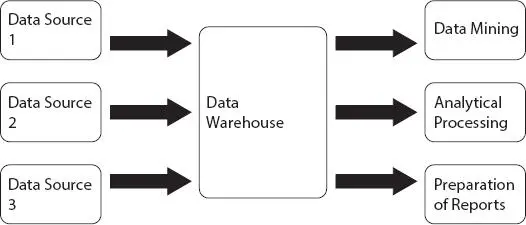
Figure 1.3 Data warehouse.
Subject-oriented—designed for a specific subject/s
Integrated—integrates different data from multiple sources.
Non-volatile—data once stored remains stable and does not change over time.
Time-variant—it looks at change over time.
One can compare data warehouse and OLTP as follows:
1.6 Data Mining Techniques
Decision trees: It is a tree-like structure that helps identify the possible outcomes/results/consequences, etc. It is usually used in a decision support system. One can say it can be used in classification and prediction. It resembles a tree-like structure where leaf nodes represent the outcomes/results, etc. as shown in Figure 1.4. As it is a tree-like structure, classification/prediction starts from the root node and traverses through the leaf nodes. Its benefit is there is no need for high computation to find perfect predictions [1–6].
If there are ‘n’ nodes (root node and leaf nodes) in a sorted manner, then the best option/desired option can be found within less time.
Genetic algorithms (GAs): It helps in finding possible solutions. These algorithms help to optimize the given problem and find better solutions. One can categorize the identified solutions into optimal and near-optimal solutions. It may comprise of ‘n’ computations and hence known as an evolutionary approach to find the perfect solution. In NP-hard problems, it has been proven that usable near-optimal solutions can be found using GAs. This concept is related to biology, i.e., chromosomes, genes, and population. These terms can be described in the computations as follows: Figure 1.4 Decision Tree.Chromosome—one possible solutionPopulations—set and subset of all possible solutionsGenes—one element of the chromosome
GAs could have the following steps involved—
Population initialization
Fitness function calculation
Crossover (finding the probabilities)
Mutation (a method to get a new solution)
Survivor selection (selecting the required and removing the unwanted)
Return the best solution.
Nearest neighbor method: As its name suggests, the nearest neighbor method tries to find the new possible solution, data based on some similarity. It classifies the given data and predicts the possible new data. Proximity among the given objects is calculated and as per the set threshold, objects close to each other are selected. E.g., KNN—‘k’ nearest neighbor algorithm. One has to decide the value of ‘k’ for better involvement of the objects. If someone decides the value of k = 1, possible outcomes become unstable, and as the value of ‘k’ increases, it involves the majority of objects which results in better predictions. Such algorithms can be used in Banking and financial systems and To calculate the credit of the users.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Data Mining and Machine Learning Applications»
Представляем Вашему вниманию похожие книги на «Data Mining and Machine Learning Applications» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Data Mining and Machine Learning Applications» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.