Artificial Intelligent Techniques for Wireless Communication and Networking
Здесь есть возможность читать онлайн «Artificial Intelligent Techniques for Wireless Communication and Networking» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Artificial Intelligent Techniques for Wireless Communication and Networking
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Artificial Intelligent Techniques for Wireless Communication and Networking: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Artificial Intelligent Techniques for Wireless Communication and Networking»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The 20 chapters address AI principles and techniques used in wireless communication and networking and outline their benefit, function, and future role in the field.
Audience
Artificial Intelligent Techniques for Wireless Communication and Networking — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Artificial Intelligent Techniques for Wireless Communication and Networking», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The point is that learning similar tasks creates an inductive bias that causes a model to construct functions useful for the variety of tasks in the neural network. This formation of more essential characteristics, therefore, contributes to less over fitting. In deep RL, an abstract state can be constructed in such a way that it provides sufficient information to match the internal meaningful dynamics concurrently, as well as to estimate the estimated return of an optimal strategy. The CRAR agent shows how a lesser version of the task can be studied by explicitly observing both the design and prototype components via the description of the state, along with an estimated maximization penalty for entropy. In contrast, this approach would allow a model-free and model-based combination to be used directly, with preparation happening in a narrower conditional state space.
1.2.3.2 Modifying the Objective Function
In order to optimize the policy acquired by a deep RL algorithm, one can implement an objective function that diverts from the real victim. By doing so, a bias is typically added, although this can help with generalization in some situations. The main approaches to modify the objective function are
i) Reward shaping
For faster learning, incentive shaping is a heuristic to change the reward of the task to ease learning. Reward shaping incorporates prior practical experience by providing intermediate incentives for actions that lead to the desired outcome. This approach is also used in deep reinforcement training to strengthen the learning process in environments with sparse and delayed rewards.
ii) Tuning the discount factor
When the model available to the agent is predicted from data, the policy discovered using a short iterative horizon will probably be better than a policy discovered with the true horizon. On the one hand, since the objective function is revised, artificially decreasing the planning horizon contributes to a bias. If a long planning horizon is focused, there is a greater chance of over fitting (the discount factor is close to 1). This over fitting can be conceptually interpreted as related to the aggregation of errors in the transformations and rewards derived from data in relation to the real transformation and reward chances [4].
1.3 Deep Reinforcement Learning: Value-Based and Policy-Based Learning
1.3.1 Value-Based Method
Algorithms such as Deep-Q-Network (DQN) use Convolutional Neural Networks (CNNs) to help the agent select the best action [9]. While these formulas are very complicated, these are usually the fundamental steps (Figure 1.4):
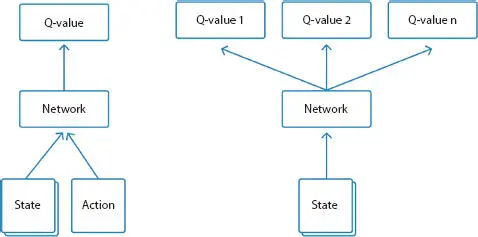
Figure 1.4Value based learning.
1 Take the status picture, transform it to grayscale, and excessive parts are cropped.
2 Run the picture through a series of contortions and pooling in order to extract the important features that will help the agent make the decision.
3 Calculate each possible action’s Q-Value.
4 To find the most accurate Q-Values, conduct back-propagation.
1.3.2 Policy-Based Method
In the modern world, the number of potential acts may be very high or unknown. For instance, a robot learning to move on open fields may have millions of potential actions within the space of a minute. In these conditions, estimating Q-values for each action is not practicable. Policy-based approaches learn the policy specific function, without computing a cost function for each action. An illustration of a policy-based algorithm is given by Policy Gradient (Figure 1.5).
Policy Gradient, simplified, works as follows:
1 Requires a condition and gets the probability of some action based on prior experience
2 Chooses the most possible action
3 Reiterates before the end of the game and evaluates the total incentives
4 Using back propagation to change connection weights based on the incentives.
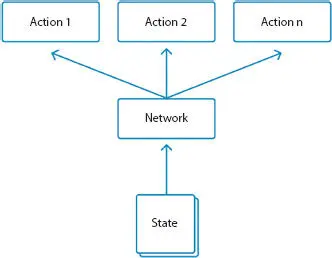
Figure 1.5Policy based learning.
1.4 Applications and Challenges of Applying Reinforcement Learning to Real-World
1.4.1 Applications
The ability to tackle a wide range of Deep RL techniques has been demonstrated to a variety of issues which were previously unsolved. A few of the most renowned accomplishments are in the game of backgammon, beating previous computer programmes, achieving superhuman-level performance from the pixels in Atari games, mastering the game of Go and beating professional poker players in the Nolimit Texas Hold’em Heads Up Game: Libratus and Deep stack.
Such achievements in popular games are essential because in a variety of large and nuanced tasks that require operating with high-dimensional inputs, they explore the effectiveness of deep RL. Deep RL has also shown a great deal of potential for real-world applications such as robotics, self-driving vehicles, finance, intelligent grids, dialogue systems, etc. Deep RL systems are still in production environments, currently. How Facebook uses Deep RL, for instance, can be found for pushing notifications and for faster video loading with smart prefetching.
RL is also relevant to fields where one might assume that supervised learning alone, such as sequence prediction, is adequate. It has also been cast as an RL problem to build the right neural architecture for supervised learning tasks. Notice that evolutionary techniques can also be addressed for certain types of tasks. Finally, it should be remembered that deep RL has prospects in the areas of computer science in classical and basic algorithmic issues, such as the travelling salesman problem. This is an NP-complete issue and the ability to solve it with deep RL illustrates the potential effect it could have on many other NP-complete issues, given that it is possible to manipulate the structure of these problems [2, 12].
1.4.2 Challenges
Off-Line Learning
Training is also not possible directly online, but learning happens offline, using records from a previous iteration of the management system. Broadly speaking, we would like it to be the case that the new system version works better than the old one and that implies that we will need to perform off-policy assessment (predicting performance before running it on the actual system). There are a couple of approaches, including large sampling, for doing this. The introduction of the first RL version (the initial policy) is one special case to consider; there is also a minimum output requirement to be met before this is supposed to occur. The warm-start efficiency is therefore another important ability to be able to assess.
Learning From Limited Samples
There are no different training and assessment environments for many actual systems. All training knowledge comes from the real system, and during training, the agent does not have a separate exploration policy as its exploratory acts do not come for free. Given this greater exploration expense, and the fact that very little of the state space is likely to be explored by logs for learning from, policy learning needs to be data-efficient. Control frequencies may be 1 h or even multi-month time steps (opportunities to take action) and even longer incentive horizons. One easy way to measure a model’s data efficiency is to look at the amount of data needed to meet a certain output threshold.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Artificial Intelligent Techniques for Wireless Communication and Networking»
Представляем Вашему вниманию похожие книги на «Artificial Intelligent Techniques for Wireless Communication and Networking» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Artificial Intelligent Techniques for Wireless Communication and Networking» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.