Artificial Intelligent Techniques for Wireless Communication and Networking
Здесь есть возможность читать онлайн «Artificial Intelligent Techniques for Wireless Communication and Networking» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Artificial Intelligent Techniques for Wireless Communication and Networking
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Artificial Intelligent Techniques for Wireless Communication and Networking: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Artificial Intelligent Techniques for Wireless Communication and Networking»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The 20 chapters address AI principles and techniques used in wireless communication and networking and outline their benefit, function, and future role in the field.
Audience
Artificial Intelligent Techniques for Wireless Communication and Networking — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Artificial Intelligent Techniques for Wireless Communication and Networking», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Deep reinforcement learning contains aspects of neural networks and learning with reinforcement (Figure 1.1). Deep reinforcement learning is achieved using two different methods: deep Q-learning and policy specular highlights. Deep Q-learning techniques attempt to anticipate the rewards will accompany certain steps taken in a particular state, while policy gradient strategies seek to optimize the operational space, predicting the behavior themselves. Policy-based approaches of deep reinforcement learning are either stochastic in architecture. Certainly, probabilistic measures map states to policies, while probabilistic policies build probabilistic models for behavior [6].
The aim of this chapter is to provide the reader with accessible tailoring of basic deep reinforcement learning and to support research experts. The primary contribution made by this work is
1 Originated with a complete review study of comprehensive deep reinforcement learning concept and framework.
2 Provided detailed applications and challenges in deep reinforcement learning.
This chapter is clearly distinguished by the points mentioned above from other recent surveys. This gives the data as comprehensive as previous works. The chapter is organized as follows: Section 1.2summarizes the complete description of reinforcement learning. The different applications and problems are explored in Section 1.3, accompanied by a conclusion in Section 1.4.
1.2 Comprehensive Study
1.2.1 Introduction
In most Artificial Intelligence (AI) subjects, we build mathematical structures to tackle problems. For RL, the Markov Decision Process (MDP) is the solution. It sounds complicated, but it provides a basic structure to model a complex problem. The world is observed and behavior performed by an individual (e.g. a human). Rewards are released, but they may be rare and delayed. The long-delayed incentives very often make it incredibly difficult to untangle the data and track what series of acts led to the rewards [11].
Markov decision process (MDP) Figure 1.2 is composed of:
State in MDP can be represented as raw images or we use sensors for robotic controls to calculate the joint angles, velocity, and pose of the end effector.
A movement in a chess game or pushing a robotic arm or a joystick may be an event.
The reward is very scarce for a GO match: 1 if we win or −1 if we lose. We get incentives more often. We score whenever we hit the sharks in the Atari Seaquest game (Figure 1.3).
If it is less than one the discount factor discounts potential incentives. In the future, money raised also has a smaller current value, and we will need it to further converge the solution for a strictly technical reason.
We can indefinitely rollout behaviour or limit the experience to N steps in time. This is called the horizon.
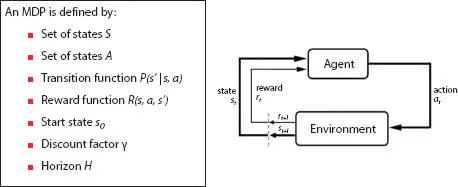
Figure 1.2Markov process.
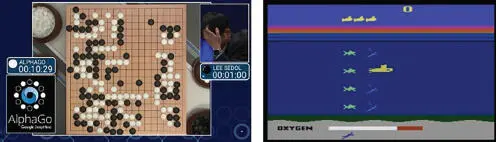
Figure 1.3Raw images of State.
System dynamics is the transformation function. After taking action, it predicts the next condition. When we address model-based RL later, it is called the model that plays a significant role. RL’s ideas come from many areas of study, including the theory of power. In a particular setting, distinct notations can be used. It is possible to write the state as s or x, and the behavior as an or u. An action is the same as a control operation. We may increase the benefits or and the costs that are actually negative for each other [10].
1.2.2 Framework
Compared to other fields such as Deep Learning, where well-established frameworks such as Tensor Flow, PyTorch, or MXnet simplify the lives of DL practitioners, the practical implementations of Reinforcement Learning are relatively young. The advent of RL frameworks, however, has already started and we can select from many projects right now that greatly encourage the use of specialized RL techniques. Frameworks such as Tensor Flow or PyTorch have appeared in recent years to help transform pattern recognition into a product, making deep learning easier for practitioners to try and use [17].
In the Reinforcement Learning arena, a similar pattern is starting to play out. We are starting to see the resurgence of many open source libraries and tools to deal with this, both by helping to create new pieces (not by writing from scratch) and above all, by combining different algorithmic components of prebuild. As a consequence, by generating high abstractions of the core components of an RL algorithm, these Reinforcement Learning frameworks support engineers [7].
A significant number of simulations include Deep Reinforcement Learning algorithms, introducing another multiplicative dimension to the time load of Deep Learning itself. This is mainly needed by the architectures we have not yet seen in this sequence, such as, among others, the distributed actor-critic methods or behaviors of multi-agents. But even choosing the best model also involves tuning hyper parameters and searching between different settings of hyper parameters; it can be expensive. All this includes the need for supercomputers based on distributed systems of heterogeneous servers (with multi-core CPUs and hardware accelerators such as GPUs or TPUs) to provide high computing power [18].
1.2.3 Choice of the Learning Algorithm and Function Approximator Selection
In deep learning, the function approximator characterizes how the characteristics are handled to higher levels of abstraction ( a fortiori can therefore give certain characteristics more or less weight). In the first levels of a deep neural network, for example, if there is an attention system, the mapping made up of those first layers can be used as a framework for selecting features. On the other hand, an asymptotic bias can occur if the function approximator used for the weighted sum and/or the rule and/or template is too basic. But on the other hand, there would be a significant error due to the limited size of the data (over fitting) when the feature approximator has weak generalization.
An especially better decision of a model-based or model-free method identified as a leading function approximator choice may infer that the state’s y-coordinate is less essential than the x-coordinate, and generalize that to the rule. It is helpful to share a performant function approximator in either a model-free or a model-based approach depending on the mission. Therefore the option to focus more on one or the other method is also a key factor in improving generalization [13, 19].
One solution to eliminating non-informative characteristics is to compel the agent to acquire a set of symbolic rules tailored to the task and to think on a more extreme scale. This abstract level logic and increased generalization have the potential to activate cognitive high-level functions such as analogical reasoning and cognitive transition. For example, the feature area of environmental may integrate a relational learning system and thus extend the notion of contextual reinforcement learning.
1.2.3.1 Auxiliary Tasks
In the era of successful reinforcement learning, growing a deep reinforcement learning agent with allied tasks within a jointly learned representation would substantially increase sample academic success.
This is accomplished by causing genuine several pseudo-reward functions, such as immediate prediction of rewards (= 0), predicting pixel changes in the next measurement, or forecasting activation of some secret unit of the neural network of the agent.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Artificial Intelligent Techniques for Wireless Communication and Networking»
Представляем Вашему вниманию похожие книги на «Artificial Intelligent Techniques for Wireless Communication and Networking» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Artificial Intelligent Techniques for Wireless Communication and Networking» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.