Advanced Analytics and Deep Learning Models
Здесь есть возможность читать онлайн «Advanced Analytics and Deep Learning Models» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Advanced Analytics and Deep Learning Models
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Advanced Analytics and Deep Learning Models: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Advanced Analytics and Deep Learning Models»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The book provides readers with an in-depth understanding of concepts and technologies related to the importance of analytics and deep learning in many useful real-world applications such as e-healthcare, transportation, agriculture, stock market, etc.
Audience
Advanced Analytics and Deep Learning Models — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Advanced Analytics and Deep Learning Models», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Here, they trained their stacked autoencoder with the three-hidden layers and five-hidden layers, and also, they applied sigmoid and hyperbolic tangents. In sigmoid transfer function, the data are transformed in between 0 and 1. In hyperbolic tangents, the data are transformed in between −1 and 1. They used mini batch GD Optimizer and Adam Optimizer for regularization. Dropout regularization is added to each hidden layer with probability p = 0.5. Research was done for dissimilar parameters. Finest parameter values are shown in the research work. In this proposed approach, 90% of data are utilized for training purposes along with the rest samples for testing purposes [4].
3.4.2.3 Result
To compare this approach with single- as well as multi-criteria rating systems, they implemented the approach with some different research result proposed by different researchers. Those are MF, 2016 Hybrid AE [23] and multi-criteria recommendation techniques: 2011 Liwei Liu [13], 2017 Learning [22], three approaches from [27] (2017 CCC, 2017 CCA, and 2017 CIC). Certain procedures are used on all the functioning datasets. The results are shown in Tables 3.1to 3.3. Conventional matrix factorization got the most ever loss in terms of MAE, GIMAE, and GPIMAE with values 1.2077, 1.3055, and 0.8079, respectively, as shown in Table 3.1. In terms of mean absolute error and F1, 2017 Pref Learning carry out superior to existing single and multi-criteria rating techniques. However, this method performs well in all the existing methods. It can be seen that MF got the maximum loss and least F1. Their preferred extended stacked autoencoder approach went beyond all the methods sufficiently in various evaluation metrics, as shown in Table 3.2. Similar trends are also found on the other datasets, YM 10-10 and YM 20-20 in Tables 3.3and 3.4, respectively [4].
3.4.3 Situation-Aware Multi-Criteria Recommender System: Using Criteria Preferences as Contexts by Zheng
Inside this research activity, they tried to implement the new methods which manage criteria likings as contextual situations. To be specific, they trust that one portion of multi-criteria preferences may be observed as contexts and the other part managed in the conventional way in MCRS. They differentiate the suggestion efficiency between three settings. First one is applying every criteria rating in the conventional way. Second setting that they used is managing every criteria preference as contexts and the last one issuing preferred criteria ratings as contexts. Their demonstrations are depending on two practical rating datasets. It reveals that managing criteria priorities as contexts can upgrade the efficiency of module recommendations if those are being selected very carefully. They have used a hybrid model which selects criteria preference as contexts and solve remaining part in traditional way. They have illustrated this proposed model and got very efficient result and the model becomes the winner of their experiment [19].
Now, we will see its experimental evaluation and result to ensure its efficiency.
3.4.3.1 Evaluation Setting
They have very limited datasets which have multiple-criteria ratings for experiment. For this research, they use two popular real-world datasets: TripAdvisor dataset and Yahoo! Movies dataset. Successively, they used 80% of rated moves or hotels for training purposes and rest 20% for the testing purpose. They evaluated and compared the algorithms which are declared placed to calculate the prediction of rating. They predicted in general ratings mentioned by users on every item for test set, along with calculate efficiency by the very popular mean absolute error method [19].
3.4.3.2 Experimental Result
The outputs are revealed in Figure 3.4. If we take a sincere look, then we will find that the data tags on above of every bar present the rate of development by HCM in correspondence with other methods. In association with algorithms, biased MF represented the outcomes that are generated by the biased MF algorithm. The present results formed on the aggregation-based approach that takes benefits of multiple-criteria ratings. The aggregation is the hybrid model that merges user-specific aggregation models with item-specific aggregation models. In this paper, the proposed models are FCM, PCM, and HCM. In PCM, they choose the most authoritative criteria as contexts using information gain. They tried many selections and combinations here and represented the best selections in this research work [19].
First, biased MF does not require more details like multi-criteria ratings or contexts. So, for this reason, it is the worst model here. As FCM carries outpour efficiency than the Agg method in the TripAdvisor dataset, so applying contexts as criteria preference will not be inadequate choice every time. Choosing the most influential criteria, PCM performs better Agg in those two datasets. Eventually, they observed, HCM is the finest predictive model with the shortest mean absolute error. It has enough to provide remarkable improvements compared with other models and depends on the statistical paired t-test. To be more specific, it is fit to acquire 4.7% and 8.7% improvements in balancing with the aggregation model, 6.7% and 6.9% improvements compared with the FCM, in the TripAdvisor and Yahoo! Movies datasets, respectively. They have proved that HCM performs better than PCM in this experiment [19].
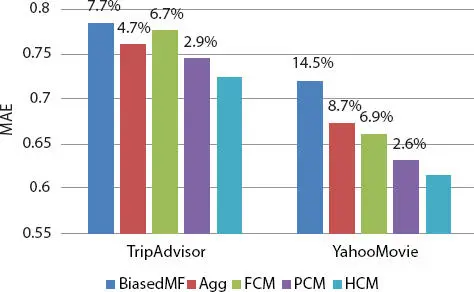
Figure 3.4 Result comparison.
3.4.4 Utility-Based Multi-Criteria Recommender Systems by Zheng
In this research activity, they introduced a utility-based multi-criteria recommendation algorithm. In this algorithm, they studied customer expectations by dissimilar learning to rank approaches. Their experimental outputs are depending on practical datasets. It demonstrates the usefulness of these approaches [3].
3.4.4.1 Experimental Dataset
In this research activity, they used two practical datasets where ratings are scaled between 1 and 5. The TripAdvisor data had used. In this dataset, it has more than 22,000 ratings provided by more than 1,500 clients with around 14,000 plus hotels. Every client rated at least 10 ratings. These ratings relate to multi-criteria ratings on seven criteria. Those criteria are cost-effective, convenience, quality of rooms, check-in, and cleanliness of the hotel and general standard of facility and specific business facilities. The Yahoo! Movies dataset was used here. There are more than 62,000 ratings given by more than 2000 clients on around 3,100 movies. Every client rates minimum 10 ratings. These ratings are related with multiple-criteria ratings on furrieries. Those critters are acting, direction, stories, and visual effects. They compared their utility-based models with some approaches. The approaches are MF, linear aggregation model (LAM), hybrid context model (HCM), and criteria chain model (CCM) [3].
They evaluated the efficiency of recommender form on the top 10 recommendations by using accuracy and NDCG to calculate the efficiency. To calculate the utility scores, they used three measures. By applying Pearson correlation, they get little improved results rather than applying cosine similarity. They found that Euclidean distance was the bad choice. They represented the best outcome by using Pearson correlation [3].
3.4.4.2 Experimental Result
As we can see in Figure 3.5, it represents the results the experiment. FMM becomes the best performing baseline method for the TripAdvisor data, but LAM and CCM beat MF by 1%. Here, HCM performs even lower than the MF approach. Through applying the utility-based method, the UBM by applying the listwise ranking can perform well the FMM method. If they use the pointwise and pairwise ranking optimizations, then the other UBM models will fail to beat FMM. From Yahoo! Movies dataset, all methods can perform the MF method that does not consider multi-criteria ratings. To be to detail, the UBM using listwise ranking can upgrade NDGC and precision by 6.3% and 5.4% in the TripAdvisor data, and 4.1% and 8% in FMM in comparison with Yahoo! Movies data [3].
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Advanced Analytics and Deep Learning Models»
Представляем Вашему вниманию похожие книги на «Advanced Analytics and Deep Learning Models» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Advanced Analytics and Deep Learning Models» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.