Марио Ливио - Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса
Здесь есть возможность читать онлайн «Марио Ливио - Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: М., Год выпуска: 2016, ISBN: 2016, Издательство: Литагент АСТ, Жанр: foreign_edu, Математика, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса
- Автор:
- Издательство:Литагент АСТ
- Жанр:
- Год:2016
- Город:М.
- ISBN:978-5-17-095136-9
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Блестящий физик и остроумный писатель Марио Ливио рассказывает о математических идеях от Пифагора до наших дней и показывает, как абстрактные формулы и умозаключения помогли нам описать Вселенную и ее законы.
Книга адресована всем любознательным читателям независимо от возраста и образования.
Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Рассмотрим простой пример того, как эти две области встречаются, так сказать, посередине и дополняют друг друга. Начнем с того факта, что статистические исследования показывают, что измерения самых разных физических величин и даже человеческих черт распределяются согласно кривой нормального распределения . Но на самом деле кривая нормального распределения – это не какая-то одна кривая, а целое семейство кривых, описываемых одной и той же общей функцией, и все они полностью характеризуются всего двумя математическими величинами. Первая из них – среднее значение – это центральное значение, относительно которого распределение симметрично. Эта величина зависит, разумеется, от того, какую именно переменную измеряют (рост, вес, IQ и так далее). Среднее значение одной и той же переменной может быть разным в разных популяциях. Например, средний рост шведов, скорее всего, отличается от среднего роста перуанцев. Вторая величина, определяющая кривую нормального распределения, называется стандартным отклонением . Это мера того, насколько тесно данные сосредоточены вокруг среднего значения. На рис. 36 у кривой нормального распределения (а) самое большое стандартное отклонение, поскольку значения рассеяны шире. Однако тут мы сталкиваемся с интересным фактом. Если с помощью интегрирования сосчитать площадь под кривой, легко математически доказать, что независимо от среднего значения и величины стандартного отклонения, 68,2 % измерений лежат в области, ограниченной одним стандартным отклонением по обе стороны от среднего значения (рис. 37). Иначе говоря, если среднее значение IQ в определенной (крупной) популяции равно 100, а стандартное отклонение равно 15, то 68,2 % людей в этой популяции обладают IQ между 85 и 115. Более того, для всех кривых нормального распределения 95,4 % всех случаев лежат в пределах двух стандартных отклонений от среднего, а 99,7 % данных попадают в пределы трех стандартных отклонений по обе стороны от среднего (рис. 37). Из этого следует, что в вышеприведенном примере 95,4 % популяции обладают IQ между 70 и 130, а 99,7 % – между 55 и 145.
Теперь предположим, что мы хотим предсказать, какова вероятность, что у случайно выбранного человека из этой популяции IQ окажется между 85 и 100. Рис. 37 подсказывает нам, что эта вероятность – 0,341 (или 34,1 %), поскольку по законам теории вероятности вероятность – это количество желаемых результатов, деленное на общее количество возможностей. А если нам интересно выяснить, какова вероятность, что кто-то (случайно выбранный) из этой популяции обладает IQ выше 130, то взгляд на рис. 37 покажет, что эта вероятность равна примерно 0,022, то есть 2,2 %. Примерно так же, опираясь на свойства нормального распределения и на метод интегрального исчисления (для вычисления площади под кривой), можно вычислить вероятность, что значение IQ попадет в тот или иной заданный диапазон. Иными словами, ответы нам дают теория вероятности и ее половинка-помощница статистика – в сочетании.
Как я уже не раз подчеркивал, вероятность и статистика обретают смысл, если имеешь дело с большим количеством событий, но не с отдельными событиями. Этой фундаментальной оговоркой, известной как закон больших чисел , мы обязаны Якобу Бернулли, который сформулировал ее в виде теоремы в своей книге « Ars Conjectandi » («Искусство предположений»; на рис. 38 приведен титульный лист) [95] Великолепный перевод на английский – Bernoulli 1713b.
. В переводе на обыденный язык теорема гласит, что если вероятность, что событие случится, равна p, то p – это самое вероятное соотношение количества случаев, когда это событие происходит, к общему числу попыток. Если же общее число попыток приближается к бесконечности, то доля успешных попыток становится в точности равна p . Вот как Бернулли формулирует закон больших чисел в «Искусстве предположений»: «Еще предстоит выяснить, увеличиваем ли мы при увеличении числа наблюдений и вероятность, что регистрируемое соотношение желаемых случаев к нежелательным приблизится к подлинному значению, и тогда эта вероятность в конце концов превзойдет всякую желаемую точность». Затем он пояснил это на конкретном примере [96] Приводится в Newman 1956.
.
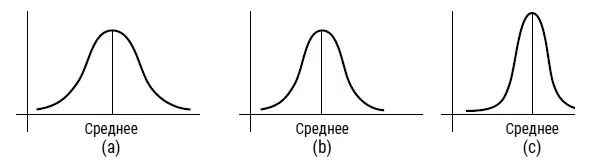
Рис. 36
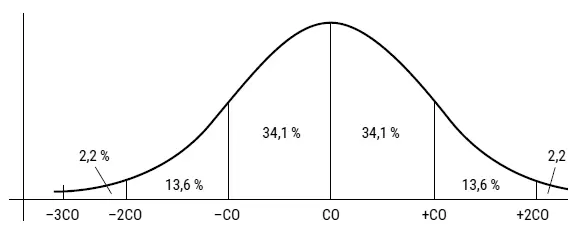
Рис. 37
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса»
Представляем Вашему вниманию похожие книги на «Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Был ли Бог математиком? Галопом по божественной Вселенной с калькулятором, штангенциркулем и таблицами Брадиса» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.