Александра Малова - Основы эконометрики в среде GRETL. Учебное пособие
Здесь есть возможность читать онлайн «Александра Малова - Основы эконометрики в среде GRETL. Учебное пособие» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2016, ISBN: 2016, Издательство: ООО «Проспект», Жанр: management, economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы эконометрики в среде GRETL. Учебное пособие
- Автор:
- Издательство:ООО «Проспект»
- Жанр:
- Год:2016
- ISBN:9785392202348
- Рейтинг книги:4 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы эконометрики в среде GRETL. Учебное пособие: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы эконометрики в среде GRETL. Учебное пособие»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы эконометрики в среде GRETL. Учебное пособие — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы эконометрики в среде GRETL. Учебное пособие», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Сравниваем расчетное значение F- статистики с критическим 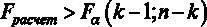 , то есть 78,2 > 2,6. Следовательно, можно сделать вывод, что гипотеза
, то есть 78,2 > 2,6. Следовательно, можно сделать вывод, что гипотеза 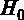 о незначимости регрессии в целом отвергается.
о незначимости регрессии в целом отвергается.
Тест Фишера можно провести также в полуавтоматическом режиме и в автоматическом режиме. Полуавтоматический режим состоит в том, что нам не нужно вручную вычислять значение расчетной F- статистики, оно дано в распечатке на рис. 2.2. В этом случае нужно лишь выяснить критическое значение F- статистики и сравнить расчетное значение с критическим.
В автоматическом режиме нужно также воспользоваться распечаткой GRETLи посмотреть на р- значение статистики Фишера на рис. 2.2 (в распечатке р- значение (F) ). В р- значении содержится вероятность ошибки I рода. Таким образом, р- значение (F) для теста Фишера – это вероятность ошибки I рода при тестировании гипотезы  . По существу это вероятность ошибиться, отвергнув гипотезу H 0. Для принятия решения, можно ли отвергнуть гипотезу H 0, нужно сравнить р- значение с заданным уровнем значимости a. Уровень значимости задает вероятность ошибки I рода, то есть, грубо говоря, какую долю ошибок мы готовы себе позволить, отвергнув гипотезу H 0. Если р- значение меньше принятого уровня значимости, то маловероятно, что мы ошибемся, отвергая гипотезу H 0в ситуации, когда р- значение больше уровня значимости, вероятна ошибка в случае отклонения нулевой гипотезы, поэтому ее стоит принять. Отсюда можно сделать вывод, что р- значение показывает вероятность ошибиться, отвергнув гипотезу H 0, при том, что она верна. Эта интерпретация р- значения справедлива для всех статистических тестов, и мы будем иметь ее в виду в дальнейшем. В данном случае р- значение (F)
. По существу это вероятность ошибиться, отвергнув гипотезу H 0. Для принятия решения, можно ли отвергнуть гипотезу H 0, нужно сравнить р- значение с заданным уровнем значимости a. Уровень значимости задает вероятность ошибки I рода, то есть, грубо говоря, какую долю ошибок мы готовы себе позволить, отвергнув гипотезу H 0. Если р- значение меньше принятого уровня значимости, то маловероятно, что мы ошибемся, отвергая гипотезу H 0в ситуации, когда р- значение больше уровня значимости, вероятна ошибка в случае отклонения нулевой гипотезы, поэтому ее стоит принять. Отсюда можно сделать вывод, что р- значение показывает вероятность ошибиться, отвергнув гипотезу H 0, при том, что она верна. Эта интерпретация р- значения справедлива для всех статистических тестов, и мы будем иметь ее в виду в дальнейшем. В данном случае р- значение (F) 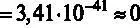 ( р- значение (F) в распечатке представляет собой « 3,41e-41 » – это компьютерный способ записи числа
( р- значение (F) в распечатке представляет собой « 3,41e-41 » – это компьютерный способ записи числа 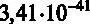 , которое практически равно 0). Это говорит о том, что можно отвергнуть гипотезу H 0(вероятность ошибки близка к 0).
, которое практически равно 0). Это говорит о том, что можно отвергнуть гипотезу H 0(вероятность ошибки близка к 0).
Стоит обратить внимание еще на один полезный факт. При расчете F- статистики вручную мы использовали формулу 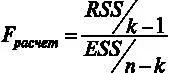 . Используя соотношение
. Используя соотношение 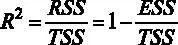 , можно переписать расчетную статистику через коэффициент детерминации, не используя квадраты остатков
, можно переписать расчетную статистику через коэффициент детерминации, не используя квадраты остатков 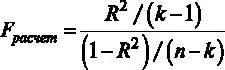 .
.
4. Тест Стьюдента (t-test)
После того как мы проверили незначимость регрессионного уравнения в целом, рассмотрим, как проверять незначимость коэффициентов при отдельных регрессорах. Для этой цели воспользуемся тестом Стьюдента [3].

Проверим незначимость коэффициента при переменной 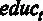 . Сформулируем гипотезы теста для указанной переменной [ файл с данными wage1.gdt ]. Они будут выглядеть следующим образом:
. Сформулируем гипотезы теста для указанной переменной [ файл с данными wage1.gdt ]. Они будут выглядеть следующим образом:
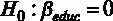
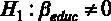
Значение оцененного коэффициента при этой переменной находится в столбце « Коэффициент » – 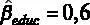 . Для того чтобы вычислить расчетную t- статистикy, необходимо знать значение стандартной ошибки для коэффициента, оно содержится в столбце « Ст. ошибка ». Для переменной стандартная ошибка
. Для того чтобы вычислить расчетную t- статистикy, необходимо знать значение стандартной ошибки для коэффициента, оно содержится в столбце « Ст. ошибка ». Для переменной стандартная ошибка 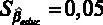 . Отсюда можем вычислить
. Отсюда можем вычислить 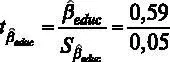 . Для принятия решения о том, можно ли отвергнуть гипотезу H 0, сравним значение
. Для принятия решения о том, можно ли отвергнуть гипотезу H 0, сравним значение 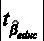 с критическим значением статистики
с критическим значением статистики 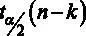 . Примем уровень значимости
. Примем уровень значимости 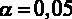 . Как уже было сказано, объем выборки составляет 526 наблюдений, то есть n = 526. Число регрессоров в модели составляет 4 (константа тоже регрессор), то есть, k = 4. Отсюда следует, что нужно искать критическое значение из двустороннего распределения Стьюдента
. Как уже было сказано, объем выборки составляет 526 наблюдений, то есть n = 526. Число регрессоров в модели составляет 4 (константа тоже регрессор), то есть, k = 4. Отсюда следует, что нужно искать критическое значение из двустороннего распределения Стьюдента 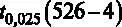 на уровне значимости 5 % (одностороннее распределение 2,5 %) с 522 степенями свободы. Для поиска критического значения из распределения Стьюдента можно воспользоваться статистическими таблицами, например из [7]. Но можно воспользоваться возможностями GRETL. Для этого в основном меню выберем Инструменты – Критические значения .
на уровне значимости 5 % (одностороннее распределение 2,5 %) с 522 степенями свободы. Для поиска критического значения из распределения Стьюдента можно воспользоваться статистическими таблицами, например из [7]. Но можно воспользоваться возможностями GRETL. Для этого в основном меню выберем Инструменты – Критические значения .
Интервал:
Закладка:
Похожие книги на «Основы эконометрики в среде GRETL. Учебное пособие»
Представляем Вашему вниманию похожие книги на «Основы эконометрики в среде GRETL. Учебное пособие» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![Михаил Гельберт - Физиологические основы поведения и дрессировки собак [Учебное пособие]](/books/406777/mihail-gelbert-fiziologicheskie-osnovy-povedeniya-i-thumb.webp)



Обсуждение, отзывы о книге «Основы эконометрики в среде GRETL. Учебное пособие» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.