Александра Малова - Основы эконометрики в среде GRETL. Учебное пособие
Здесь есть возможность читать онлайн «Александра Малова - Основы эконометрики в среде GRETL. Учебное пособие» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2016, ISBN: 2016, Издательство: ООО «Проспект», Жанр: management, economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы эконометрики в среде GRETL. Учебное пособие
- Автор:
- Издательство:ООО «Проспект»
- Жанр:
- Год:2016
- ISBN:9785392202348
- Рейтинг книги:4 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы эконометрики в среде GRETL. Учебное пособие: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы эконометрики в среде GRETL. Учебное пособие»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы эконометрики в среде GRETL. Учебное пособие — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы эконометрики в среде GRETL. Учебное пособие», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2. 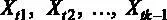 ,
, 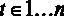 – детерминированные величины.
– детерминированные величины.
3. 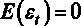 – математическое ожидание ошибок равно нулю,
– математическое ожидание ошибок равно нулю, 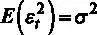 , дисперсия ошибок не зависит от номера наблюдения.
, дисперсия ошибок не зависит от номера наблюдения.
4. 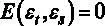 ,
, 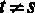 – совместное математическое ожидание ошибок разных наблюдений равно нулю.
– совместное математическое ожидание ошибок разных наблюдений равно нулю.
5. Если выполняется дополнительная предпосылка о нормальном распределении ошибок 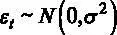 , то классическая линейная регрессионная модель называется нормальной линейной регрессионной моделью (НЛРМ).
, то классическая линейная регрессионная модель называется нормальной линейной регрессионной моделью (НЛРМ).
Подробнее о предпосылках линейной регрессионной модели можно прочесть в [2, 3].
2. Оценка линейной регрессионной модели
Рассмотрим множественную линейную регрессию
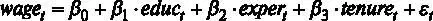 ,
, 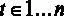 ,
,
где 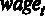 – средний уровень заработной платы в час в долларах,
– средний уровень заработной платы в час в долларах, 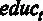 – образование в годах,
– образование в годах, 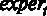 – общий стаж работы в годах,
– общий стаж работы в годах, 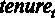 – опыт работы у текущего работодателя, в годах,
– опыт работы у текущего работодателя, в годах, 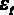 – ошибка регрессии, n – число наблюдений [ файл с данными wage1.gdt ].
– ошибка регрессии, n – число наблюдений [ файл с данными wage1.gdt ].
Для того чтобы оценить предложенную модель по методу наименьших квадратов (МНК), используем команду меню Модель – Метод наименьших квадратов .
В появившемся диалоговом окне в поле Зависимая переменная помещаем переменную 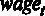 (для этого выделяем ее курсором в списке переменных и нажимаем на стрелку, соответствующую окну Зависимая переменная . Данный способ перемещения переменных справедлив для всех операций с диалоговыми окнами).
(для этого выделяем ее курсором в списке переменных и нажимаем на стрелку, соответствующую окну Зависимая переменная . Данный способ перемещения переменных справедлив для всех операций с диалоговыми окнами).
Для дальнейшего удобства можно поставить галочку в окошке Установить по умолчанию . Это делается для того, чтобы при изменении спецификации исследуемой модели зависимая переменная не менялась. В окно Регрессоры отправляем регрессоры модели – это переменные , , .
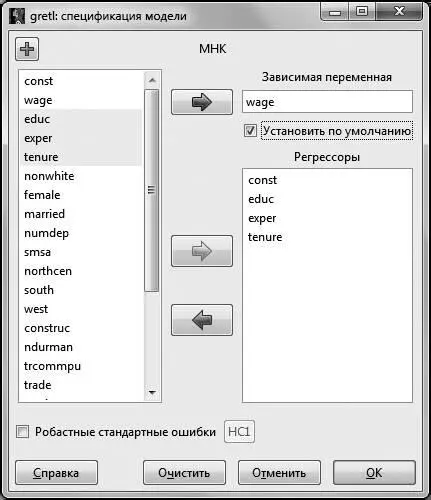
Рис. 2.1
После этого нажимаем ОК . В результате коэффициенты модели были оценены методом наименьших квадратов. Результат оценки представлен на рис. 2.2.
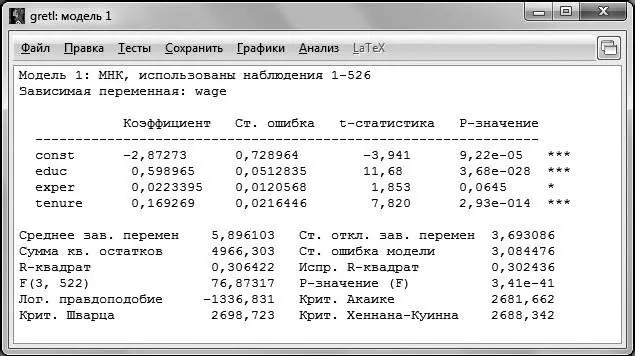
Рис. 2.2
Для того чтобы понимать, какие результаты позволяет получить GRETL, разберем информацию, представленную на распечатке по строкам сверху вниз.
В первой строке указывается метод оценки и количество наблюдений, по которым производилась оценка. Достаточно часто случается, что количество наблюдений, по которым производилась оценка, не совпадает с числом наблюдений в исходной выборке, даже если она не была ограничена. Это может быть связано, например, с наличием пропусков в данных.
Вторая строка напоминает нам о том, какая переменная была выбрана в качестве зависимой.
После двух первых строк следуют подтаблицы непосредственно с результатами оценивания. В первой подтаблице указаны регрессоры, включенные в модель, напротив каждого из них указывается его коэффициент (столбец Коэффициенты ), стандартная ошибка оценки коэффициента (столбец Ст. ошибка ), значение статистики Стьюдента для коэффициента (столбец t-статистика ) и вероятность ошибки I рода (столбец P-значение ). Стоит отметить, что константа тоже является регрессором, и для нее также рассчитываются все указанные характеристики.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы эконометрики в среде GRETL. Учебное пособие»
Представляем Вашему вниманию похожие книги на «Основы эконометрики в среде GRETL. Учебное пособие» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![Михаил Гельберт - Физиологические основы поведения и дрессировки собак [Учебное пособие]](/books/406777/mihail-gelbert-fiziologicheskie-osnovy-povedeniya-i-thumb.webp)



Обсуждение, отзывы о книге «Основы эконометрики в среде GRETL. Учебное пособие» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.