Макс Тегмарк - Life 3.0 - Being Human in the Age of Artificial Intelligence
Здесь есть возможность читать онлайн «Макс Тегмарк - Life 3.0 - Being Human in the Age of Artificial Intelligence» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2017, ISBN: 2017, Издательство: Knopf Doubleday Publishing Group, Жанр: Прочая научная литература, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Life 3.0: Being Human in the Age of Artificial Intelligence
- Автор:
- Издательство:Knopf Doubleday Publishing Group
- Жанр:
- Год:2017
- ISBN:9781101946596
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Life 3.0: Being Human in the Age of Artificial Intelligence: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Life 3.0: Being Human in the Age of Artificial Intelligence»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
How can we grow our prosperity through automation without leaving people lacking income or purpose? What career advice should we give today's kids? How can we make future AI systems more robust, so that they do what we want without crashing, malfunctioning or getting hacked? Should we fear an arms race in lethal autonomous weapons? Will machines eventually outsmart us at all tasks, replacing humans on the job market and perhaps altogether? Will AI help life flourish like never before or give us more power than we can handle?
What sort of future do you want? This book empowers you to join what may be the most important conversation of our time. It doesn't shy away from the full range of viewpoints or from the most controversial issues -- from superintelligence to meaning, consciousness and the ultimate physical limits on life in the cosmos.
Life 3.0: Being Human in the Age of Artificial Intelligence — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Life 3.0: Being Human in the Age of Artificial Intelligence», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
In other words, the time window during which you can load your goals into an AI may be quite short: the brief period between when it’s too dumb to get you and too smart to let you. The reason that value loading can be harder with machines than with people is that their intelligence growth can be much faster: whereas children can spend many years in that magic persuadable window where their intelligence is comparable to that of their parents, an AI might, like Prometheus, blow through this window in a matter of days or hours.
Some researchers are pursuing an alternative approach to making machines adopt our goals, which goes by the buzzword corrigibility. The hope is that one can give a primitive AI a goal system such that it simply doesn’t care if you occasionally shut it down and alter its goals. If this proves possible, then you can safely let your AI get superintelligent, power it off, install your goals, try it out for a while and, whenever you’re unhappy with the results, just power it down and make more goal tweaks.
But even if you build an AI that will both learn and adopt your goals, you still haven’t finished solving the goal-alignment problem: what if your AI’s goals evolve as it gets smarter? How are you going to guarantee that it retains your goals no matter how much recursive self-improvement it undergoes? Let’s explore an interesting argument for why goal retention is guaranteed automatically, and then see if we can poke holes in it.
Although we can’t predict in detail what will happen after an intelligence explosion—which is why Vernor Vinge called it a “singularity”—the physicist and AI researcher Steve Omohundro argued in a seminal 2008 essay that we can nonetheless predict certain aspects of the superintelligent AI’s behavior almost independently of whatever ultimate goals it may have.5 This argument was reviewed and further developed in Nick Bostrom’s book Superintelligence . The basic idea is that whatever its ultimate goals are, these will lead to predictable subgoals. Earlier in this chapter, we saw how the goal of replication led to the subgoal of eating, which means that although an alien observing Earth’s evolving bacteria billions of years ago couldn’t have predicted what all our human goals would be, it could have safely predicted that one of our goals would be acquiring nutrients. Looking ahead, what subgoals should we expect a superintelligent AI to have?
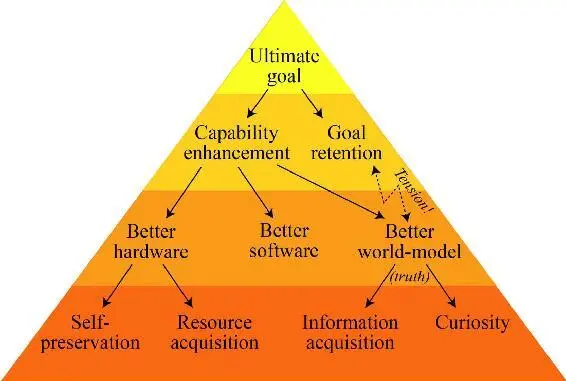
Figure 7.2: Any ultimate goal of a superintelligent AI naturally leads to the subgoals shown. But there’s an inherent tension between goal retention and improving its world model, which casts doubts on whether it will actually retain its original goal as it gets smarter.
The way I see it, the basic argument is that to maximize its chances of accomplishing its ultimate goals, whatever they are, an AI should pursue the subgoals shown in Figure 7.2. It should strive not only to improve its capability of achieving its ultimate goals, but also to ensure that it will retain these goals even after it has become more capable. This sounds quite plausible: After all, would you choose to get an IQ-boosting brain implant if you knew that it would make you want to kill your loved ones? This argument that an ever more intelligent AI will retain its ultimate goals forms a cornerstone of the friendly-AI vision promulgated by Eliezer Yudkowsky and others: it basically says that if we manage to get our self-improving AI to become friendly by learning and adopting our goals, then we’re all set, because we’re guaranteed that it will try its best to remain friendly forever.
But is it really true? To answer this question, we need to also explore the other emergent subgoals from figure 7.2. The AI will obviously maximize its chances of accomplishing its ultimate goal, whatever it is, if it can enhance its capabilities, and it can do this by improving its hardware, software *2and world model. The same applies to us humans: a girl whose goal is to become the world’s best tennis player will practice to improve her muscular tennis-playing hardware, her neural tennis-playing software and her mental world model that helps predict what her opponents will do. For an AI, the subgoal of optimizing its hardware favors both better use of current resources (for sensors, actuators, computation and so on) and acquisition of more resources. It also implies a desire for self-preservation, since destruction/shutdown would be the ultimate hardware degradation.
But wait a second! Aren’t we falling into a trap of anthropomorphizing our AI with all this talk about how it will try to amass resources and defend itself? Shouldn’t we expect such stereotypically alpha-male traits only in intelligences forged by viciously competitive Darwinian evolution? Since AIs are designed rather than evolved, can’t they just as well be unambitious and self-sacrificing?
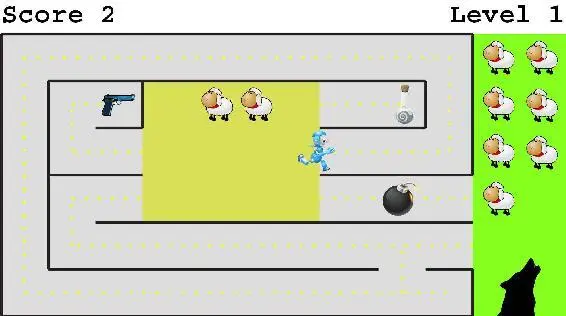
As a simple case study, let’s consider the AI robot in figure 7.3, whose only goal is to save as many sheep as possible from the big bad wolf. This sounds like a noble and altruistic goal completely unrelated to self-preservation and acquiring stuff. But what’s the best strategy for our robot friend? The robot will rescue no more sheep if it runs into the bomb, so it has an incentive to avoid getting blown up. In other words, it develops a subgoal of self-preservation! It also has an incentive to exhibit curiosity, improving its world model by exploring its environment, because although the path it’s currently running along will eventually get it to the pasture, there’s a shorter alternative that would allow the wolf less time for sheep-munching. Finally, if the robot explores thoroughly, it will discover the value of acquiring resources: the potion makes it run faster and the gun lets it shoot the wolf. In summary, we can’t dismiss “alpha-male” subgoals such as self-preservation and resource acquisition as relevant only to evolved organisms, because our AI robot developed them from its single goal of ovine bliss.
If you imbue a superintelligent AI with the sole goal to self-destruct, it will of course happily do so. However, the point is that it will resist being shut down if you give it any goal that it needs to remain operational to accomplish—and this covers almost all goals! If you give a superintelligence the sole goal of minimizing harm to humanity, for example, it will defend itself against shutdown attempts because it knows we’ll harm one another much more in its absence through future wars and other follies.
Similarly, almost all goals can be better accomplished with more resources, so we should expect a superintelligence to want resources almost regardless of what ultimate goal it has. Giving a superintelligence a single open-ended goal with no constraints can therefore be dangerous: if we create a superintelligence whose only goal is to play the game Go as well as possible, the rational thing for it to do is to rearrange our Solar System into a gigantic computer without regard for its previous inhabitants and then start settling our cosmos on a quest for more computational power. We’ve now gone full circle: just as the goal of resource acquisition gave some humans the subgoal of mastering Go, this goal of mastering Go can lead to the subgoal of resource acquisition. In conclusion, these emergent subgoals make it crucial that we not unleash superintelligence before solving the goal-alignment problem: unless we put great care into endowing it with human-friendly goals, things are likely to end badly for us.
Интервал:
Закладка:
Похожие книги на «Life 3.0: Being Human in the Age of Artificial Intelligence»
Представляем Вашему вниманию похожие книги на «Life 3.0: Being Human in the Age of Artificial Intelligence» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Life 3.0: Being Human in the Age of Artificial Intelligence» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.