Андрей Райгородский - Кому нужна математика? Понятная книга о том, как устроен цифровой мир
Здесь есть возможность читать онлайн «Андрей Райгородский - Кому нужна математика? Понятная книга о том, как устроен цифровой мир» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2017, ISBN: 2017, Издательство: Литагент МИФ без БК, Жанр: Математика, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Кому нужна математика? Понятная книга о том, как устроен цифровой мир
- Автор:
- Издательство:Литагент МИФ без БК
- Жанр:
- Год:2017
- Город:Москва
- ISBN:978-5-00100-521-6
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Кому нужна математика? Понятная книга о том, как устроен цифровой мир: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Кому нужна математика? Понятная книга о том, как устроен цифровой мир»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга будет полезна широкому кругу читателей, но для наиболее заинтересованных и подготовленных читателей авторы добавили дополнительные сведения, объединив их в специальном приложении.
Кому нужна математика? Понятная книга о том, как устроен цифровой мир — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Кому нужна математика? Понятная книга о том, как устроен цифровой мир», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
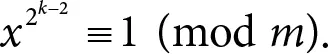
При этом φ (m) = 2 k −1, потому что числа, взаимно простые со степенью двойки, – это все нечетные числа, а их ровно 2 k −1. Значит, для любого х нашлось число
a = 2 k −2< 2 k −1= φ (m) ,
для которого выполняется x a ≡ 1 (mod m ). Получается, что у m = 2 k при k ≥ 3 первообразных корней нет.
Теперь мы можем объяснить, почему в качестве m удобно брать простое число р. Для простого р всегда существуют первообразные корни. На самом деле мы уже говорили о них выше, в приложении 2 к главе 6, только не называли этим термином. Это те самые числа g , которые дают разные остатки от деления на p в (П.15). Например, при p = 3 это g = 2, при p = 5 это g = 2, а при p = 7 это g = 3. В нашем примере в тексте главы число g = 2 – это один из первообразных корней числа p = 19.
Итак, если g – первообразный корень p , то все остатки в (П.15) разные и каждому остатку соответствует единственная степень х (дискретный логарифм, он же индекс), при которой такой остаток получается. Ничего подобного мы не можем сделать, если будем брать остаток от деления на число m , для которого первообразного корня нет. Именно поэтому работают с простыми числами.
Заметим, что первообразные корни есть еще для m = 4, m = p k и m = 2 p k . Но все равно с простыми числами работать проще.
Назад к Главе 6
Приложение к главе 7
Двойной логарифм в HyperLogLog
Хеш-значения – это последовательности из нулей и единиц одинаковой длины. Обозначим длину хеш-значений через т. Тогда получим 2 m разных хеш-значений (см. главу 3и приложение 1к ней).
Теперь допустим, что нам нужно сосчитать n различных объектов. Чтобы присвоить им всем разные хеш-значения, понадобится как минимум n хеш-значений, то есть
Стало быть, m должно быть того же порядка величины, что и log 2( n ).
Алгоритм К-Minimum Values запоминает К самых маленьких хеш-значений длины m , то есть для этого алгоритма нам нужен объем памяти примерно K log 2( n ).
HyperLogLog запоминает только максимальное количество нулей в начале хеш-значений. Если сами хеш-значения длины m , то и нулей может быть не больше, чем т. Значит, нам нужно держать в памяти число между 0 и m . Оно тоже записывается с помощью последовательности нулей и единиц. Какой длины должны быть эти последовательности? Если последовательности длины l , то мы можем записать 2 l разных чисел. Стало быть, чтобы записать m + 1 разных чисел, должно выполняться
В памяти нам нужно держать только l битов информации (последовательность из нулей и единиц длины l ). Из предыдущих формул получается:
Для повышения точности хеш-значения разбивают на r регистров и запоминают максимальное число нулей в каждом регистре отдельно. В результате требуется порядка r log 2(log 2( n )) битов памяти. Относительная точность оценки задается формулой 1,04÷ √ r {36}.
Назад к Главе 7
Приложение к главе 8
Доказательство совместимости по стимулам аукциона второй цены
Рассмотрим аукцион второй цены, на котором один товар разыгрывается между n участниками. Обозначим v i истинную ценность товара для участника i (от английского слова value – ценность). Далее обозначим через b i ставку участника i (от англ. bid – ставка ). Эти обозначения будем использовать для любого i = 1,2, …, n .
Совместимость по стимулам означает, что верна следующая теорема.
Теорема (Викри). Участник i получает максимальную прибыль, если b i = v i .
Доказательство.Если участник i получает товар, следовательно, его ставка b i была самой высокой. Поскольку мы имеем дело с аукционом второй цены, то стоимость товара равна самой высокой из оставшихся ставок:
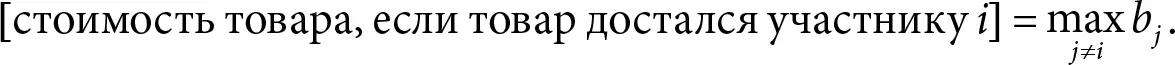
При этом ценность товара для участника i равна v i . Значит, если участник i получает товар, то его прибыль составит
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Кому нужна математика? Понятная книга о том, как устроен цифровой мир»
Представляем Вашему вниманию похожие книги на «Кому нужна математика? Понятная книга о том, как устроен цифровой мир» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Кому нужна математика? Понятная книга о том, как устроен цифровой мир» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.