Миран Липовача - Изучай Haskell во имя добра!
Здесь есть возможность читать онлайн «Миран Липовача - Изучай Haskell во имя добра!» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2012, ISBN: 2012, Издательство: ДМК Пресс, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Изучай Haskell во имя добра!
- Автор:
- Издательство:ДМК Пресс
- Жанр:
- Год:2012
- Город:Москва
- ISBN:978-5-94074-749-9
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Изучай Haskell во имя добра!: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Изучай Haskell во имя добра!»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Язык Haskell имеет множество впечатляющих возможностей, но главное его свойство в том, что меняется не только способ написания кода, но и сам способ размышления о проблемах и возможных решениях. Этим Haskell действительно отличается от большинства языков программирования. С его помощью мир можно представить и описать нестандартным образом. И поскольку Haskell предлагает совершенно новые способы размышления о проблемах, изучение этого языка может изменить и стиль программирования на всех прочих.
Ещё одно необычное свойство Haskell состоит в том, что в этом языке придаётся особое значение рассуждениям о типах данных. Как следствие, вы помещаете больше внимания и меньше кода в ваши программы.
Вне зависимости от того, в каком направлении вы намерены двигаться, путешествуя в мире программирования, небольшой заход в страну Haskell себя оправдает. А если вы решите там остаться, то наверняка найдёте чем заняться и чему поучиться!
Эта книга поможет многим читателям найти свой путь к Haskell.
Отображения, монады, моноиды и другое! Всё сказано в названии: «Изучай Хаскель во имя добра!» – весёлый иллюстрированный самоучитель по этому сложному функциональному языку.
С помощью оригинальных рисунков автора, отсылке к поп-культуре, и, самое главное, благодаря полезным примерам кода, эта книга обучает основам функционального программирования так, как вы никогда не смогли бы себе представить.
Вы начнете изучение с простого материала: основы синтаксиса, рекурсия, типы и классы типов. Затем, когда вы преуспеете в основах, начнется настоящий мастер-класс от профессионала: вы изучите, как использовать аппликативные функторы, монады, застежки, и другие легендарные конструкции Хаскеля, о которых вы читали только в сказках.
Продираясь сквозь образные (и порой безумные) примеры автора, вы научитесь:
• Смеяться в лицо побочным эффектам, поскольку вы овладеете техниками чистого функционального программирования.
• Использовать волшебство «ленивости» Хаскеля для игры с бесконечными наборами данных.
• Организовывать свои программы, создавая собственные типы, классы типов и модули.
• Использовать элегантную систему ввода-вывода Хаскеля, чтобы делиться гениальностью ваших программ с окружающим миром.
Нет лучшего способа изучить этот мощный язык, чем чтение «Изучай Хаскель во имя добра!», кроме, разве что, поедания мозга его создателей. Миран Липовача (Miran Lipovača) изучает информатику в Любляне (Словения). Помимо его любви к Хаскелю, ему нравится заниматься боксом, играть на бас-гитаре и, конечно же, рисовать. У него есть увлечение танцующими скелетами и числом 71, а когда он проходит через автоматические двери, он притворяется, что на самом деле открывает их силой своей мысли.
Изучай Haskell во имя добра! — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Изучай Haskell во имя добра!», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Вырастим-ка дерево
Теперь мы собираемся реализовать бинарное поисковое дерево. Если вам не знакомы поисковые деревья из языков наподобие С, вот что они представляют собой: элемент указывает на два других элемента, один из которых правый, другой – левый. Элемент слева – меньше, чем текущий, элемент справа – больше. Каждый из этих двух элементов также может ссылаться на два других элемента (или на один, или не ссылаться вообще). Получается, что каждый элемент может иметь до двух поддеревьев. Бинарные поисковые деревья удобны тем, что мы знаем, что все элементы в левом поддереве элемента со значением, скажем, пять, будут меньше пяти. Элементы в правом поддереве будут больше пяти. Таким образом, если нам надо найти 8 в нашем дереве, мы начнём с пятёрки, и так как 8 больше 5, будем проверять правое поддерево. Теперь проверим узел со значением 7, и так как 8 больше 7, снова выберем правое поддерево. В результате элемент найдётся всего за три операции сравнения! Если мы бы искали в обычном списке (или в сильно разбалансированном дереве), потребовалось бы до семи сравнений вместо трёх для поиска того же элемента.
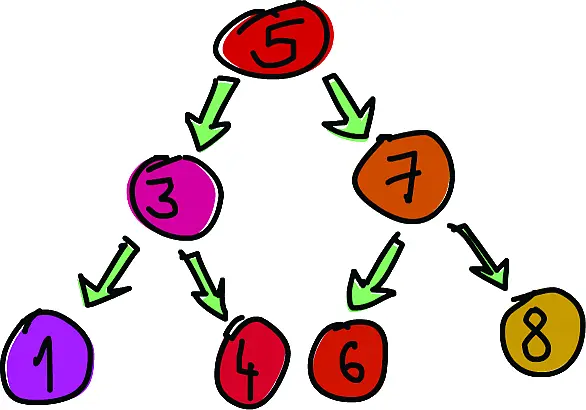
ПРИМЕЧАНИЕ.Множества и отображения из модулей Data.Setи Data.Mapреализованы с помощью деревьев, но вместо обычных бинарных поисковых деревьев они используют сбалансированные поисковые деревья. Дерево называется сбалансированным, если высоты его левого и правого поддеревьев примерно равны. Это условие ускоряет поиск по дереву. В наших примерах мы реализуем обычные поисковые деревья.
Вот что мы собираемся сказать: дерево – это или пустое дерево, или элемент, который содержит некоторое значение и два поддерева. Такая формулировка идеально соответствует алгебраическому типу данных.
data Tree a = EmptyTree | Node a (Tree a) (Tree a) deriving (Show)
Что ж, отлично. Вместо того чтобы вручную создавать дерево, мы напишем функцию, которая принимает дерево и элемент и добавляет элемент к дереву. Мы будем делать это, сравнивая вставляемый элемент с корневым. Если вставляемый элемент меньше корневого – идём налево, если больше – направо. Эту же операцию продолжаем для каждого последующего узла дерева, пока не достигнем пустого дерева. После этого мы добавляем новый элемент вместо пустого дерева.
В языках, подобных С, мы бы делали это, изменяя указатели и значения внутри дерева. В Haskell мы на самом деле не можем изменять наше дерево – придётся создавать новое поддерево каждый раз, когда мы переходим к левому или правому поддереву. Таким образом, в конце функции добавления мы вернём полностью новое дерево, потому что в языке Haskell нет концепции указателей, есть только значения. Следовательно, тип функции для добавления элемента будет примерно следующим: a –> Tree a – > Tree a. Она принимает элемент и дерево и возвращает новое дерево с уже добавленным элементом. Это может показаться неэффективным, но язык Haskell умеет организовывать совместное владение большей частью поддеревьев старым и новым деревьями.
Итак, напишем две функции. Первая будет вспомогательной функцией для создания дерева, состоящего из одного элемента; вторая будет вставлять элемент в дерево.
singleton :: a –> Tree a
singleton x = Node x EmptyTree EmptyTree
treeInsert :: (Ord a) => a –> Tree a –> Tree a
treeInsert x EmptyTree = singleton x
treeInsert x (Node a left right)
| x == a = Node x left right
| x < a = Node a (treeInsert x left) right
| x > a = Node a left (treeInsert x right)
Функция singletonслужит для создания узла, который хранит некоторое значение и два пустых поддерева. В функции для добавления нового элемента в дерево мы вначале обрабатываем граничное условие. Если мы достигли пустого поддерева, это значит, что мы в нужном месте нашего дерева, и вместо пустого дерева помещаем одноэлементное дерево, созданное из нашего значения. Если мы вставляем не в пустое дерево, следует кое-что проверить. Первое: если вставляемый элемент равен корневому элементу – просто возвращаем дерево текущего элемента. Если он меньше, возвращаем дерево, которое имеет то же корневое значение и то же правое поддерево, но вместо левого поддерева помещаем дерево с добавленным элементом. Так же (но с соответствующими поправками) обстоит дело, если значение больше, чем корневой элемент.
Следующей мы напишем функцию для проверки, входит ли некоторый элемент в наше дерево или нет. Для начала определим базовые случаи. Если мы ищем элемент в пустом дереве, его там определённо нет. Заметили – такой же базовый случай мы использовали для поиска элемента в списке? Если мы ищем в пустом списке, то ничего не найдём. Если ищем не в пустом дереве, надо проверить несколько условий. Если элемент в текущем корне равен тому, что мы ищем, – отлично. Ну а если нет, тогда как быть?.. Мы можем извлечь пользу из того, что все элементы в левом поддереве меньше корневого элемента. Поэтому, если искомый элемент меньше корневого, начинаем искать в левом поддереве. Если он больше – ищем в правом поддереве.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Изучай Haskell во имя добра!»
Представляем Вашему вниманию похожие книги на «Изучай Haskell во имя добра!» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Изучай Haskell во имя добра!» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.