Денис Соломатин - Основы статистической обработки педагогической информации
Здесь есть возможность читать онлайн «Денис Соломатин - Основы статистической обработки педагогической информации» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2020, ISBN: 2020, Жанр: Программирование, management, Детская образовательная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы статистической обработки педагогической информации
- Автор:
- Жанр:
- Год:2020
- ISBN:978-5-532-04389-3
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы статистической обработки педагогической информации: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы статистической обработки педагогической информации»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы статистической обработки педагогической информации — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы статистической обработки педагогической информации», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Упражнения
1. На переменные, хранящие длительность перелёта, удобно смотреть, но трудно выполнять операции над ними, так как они не совсем порядковые числа, за 159 (которое символизирует 1 час, 59 минут) идет сразу 200 (2 часа ровно). Конвертируйте их в более удобное представление, чтобы хранилось общее количество минут начиная с полуночи.
2. Сравните значения часы_полёта с опоздание_в_каждом_часе. Что надеялись увидеть и что увидели? Что нужно сделать, чтобы исправить ошибку?
3. Найдите 10 самых задерживаемых рейсов, используя функции ранжирования. Как это связано? Внимательно прочитайте текст документация по min_rank().
4. Что возвращает 2:4 – 5:8 и почему?
5. Какие тригонометрические функции определены в R?
Последняя ключевая функция summary(), – она собирает сводную статистику по переменным при помощи вспомогательных функций. Например, среднее значение (mean) переменной dep_delay посчитается в переменную средняя_задержка_рейсов:
summarise(flights, средняя_задержка_рейсов = mean(dep_delay, na.rm = TRUE))
Ниже объясним подробно, что значит последний параметр na.rm = TRUE. Функция summary() не очень полезна, если используется без вспомогательной функции group_by(), которая переключает разбивает анализ всего набора данных на отдельные группы. Когда вызывается функция из пакета dplyr на сгруппированных данных, автоматически подключается group_by() для распараллеливания вычислений в целях повышения производительности и дробления информации. Например, если применить точно такой же вызов как в предыдущем примере, но для сгруппированных по дате записях, то на выходе получится средняя задержка по дням:
сгруппированные_по_дням <���– group_by(flights, year, month, day)
summarise(сгруппированные_по_дням,
средняя_задержка_рейсов_по_датам = mean(dep_delay, na.rm = TRUE))
Вызов функций group_by() совместно с summary() чаще всего используется при работе в пакете dplyr для получения статистических отчетов по группам. Но прежде, чем погрузиться в детали, дополнительно изложим одну техническую идею, касающуюся обработки информации путём её направления по специальным каналам. Представьте, что хотим исследовать закономерность между расстоянием и средней задержкой рейса для каждого пункта назначения. Опираясь на имеющиеся знания о возможностях dplyr, для этого достаточно использовать такой код:
группы_рейсов_по_месту_назначения <���– group_by(flights, dest)
задержки <���– summarise(группы_рейсов_по_месту_назначения,
опозданий = n(), средняя_длина_маршрута = mean(distance, na.rm = TRUE),
средняя_задержка = mean(arr_delay, na.rm = TRUE))
Оставим в выборке рейсы имеющие более сотни регулярных опозданий и, например, не на московских направлениях:
задержки <���– filter(задержки, опозданий > 100, dest != "MSK")
Визуализируем оставшиеся записи:
ggplot(data = задержки, mapping =
aes(x = средняя_длина_маршрута, y = средняя_задержка)) +
geom_point(aes(size = опозданий), alpha = 1/5) +
geom_smooth(se = FALSE)
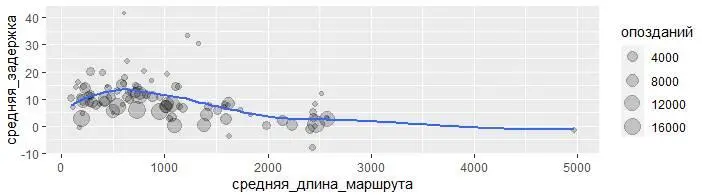
Похоже, что задержки растут с увеличением расстояния до ~750 миль, а затем сокращаются. Неужели, когда рейсы становятся длиннее, появляется возможность компенсировать опоздание находясь в полёте?
Предварительно было пройдено три вспомогательных этапа подготовки данных:
1. Сгруппированы рейсы по направлениям.
2. В каждой из групп усреднены расстояния, длительность задержки и вычислено количество опоздавших рейсов.
3. Отфильтрованы шумы и аэропорт, который не подчиняется законам логики.
Этот код немного перегружен, так как каждому промежуточному блоку данных присвоено имя. Вспомогательные таблицы сохранялись, даже когда их содержимое не востребовано на заключительном этапе, и замедляли анализ. Но есть отличный способ справиться с обозначенной проблемой посредством настройки каналов передачи данных служебным оператором %>%:
задержки <���– flights %>%
group_by(dest) %>%
summarise(
опозданий = n(),
средняя_длина_маршрута = mean(distance, na.rm = TRUE),
средняя_задержка = mean(arr_delay, na.rm = TRUE) ) %>%
filter(опозданий > 100, dest != " MSK ")
Такой синтаксис фокусирует внимание исследователя на выполняемых преобразованиях, а не на том, что получается на каждом из вспомогательных этапов, и делает код более читаемым. Это звучит как ряд предписаний: сгруппируй, после этого подведи итоги, после этого отфильтруй полученное. Как подсказывает здравый смысл, можно читать %>% в коде как «после этого». По сути же, формируется информационный канал последовательной передачи данных на обработку от одной функции через другую к третьей. Технически, x %>% f(y) превращается в f(x, y), а x %>% f(y) %>% g(z) превращается в композицию функций g(f(x, y), z) и так далее, что позволяет использовать канал для объединения нескольких операций в одну, которую можно читать слева направо, сверху вниз. Будем часто пользоваться каналами, так как это значительно упрощает читаемость кода, разберём их более подробно в соответствующем разделе.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы статистической обработки педагогической информации»
Представляем Вашему вниманию похожие книги на «Основы статистической обработки педагогической информации» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы статистической обработки педагогической информации» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.