Денис Соломатин - Основы статистической обработки педагогической информации
Здесь есть возможность читать онлайн «Денис Соломатин - Основы статистической обработки педагогической информации» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2020, ISBN: 2020, Жанр: Программирование, management, Детская образовательная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы статистической обработки педагогической информации
- Автор:
- Жанр:
- Год:2020
- ISBN:978-5-532-04389-3
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы статистической обработки педагогической информации: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы статистической обработки педагогической информации»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы статистической обработки педагогической информации — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы статистической обработки педагогической информации», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
 Историческая справка. Не сказать чтобы бейсбол был нашей национальной забавой, но многие в России знают «сколько пинчеров на базе», и именно россиянин, уроженец Нижнего Тагила, Виктор Константинович Старухин стал первым питчером, кто одержал 300 побед в японской бейсбольной лиге, являясь одним из лучших бейсболистов мира в 20 веке.
Историческая справка. Не сказать чтобы бейсбол был нашей национальной забавой, но многие в России знают «сколько пинчеров на базе», и именно россиянин, уроженец Нижнего Тагила, Виктор Константинович Старухин стал первым питчером, кто одержал 300 побед в японской бейсбольной лиге, являясь одним из лучших бейсболистов мира в 20 веке.
Когда строится график визуализирующий уровень мастерства игроков, измеряется среднее значение эффективных попаданий по мячу по отношению к общему количеству предпринятых попыток, возникает две статистические предпосылки:
1. Как было в примере с самолётами, вариативность показателей уменьшается при увеличении количества наблюдений.
2. Существует положительная корреляция между результативностью и элементарно предоставляемой возможностью бить по мячу. Дело в том, что команды контролируют свой состав, поэтому очевидно, что на поле выходят только лучшие игроки из лучших.
Предварительно преобразуем сведения об ударах игроков в табличную форму, так они легче воспринимаются:
удары <���– as_tibble(Lahman::Batting)
эффективность <���– удары %>%
group_by(playerID) %>%
summarise(
результативность = sum(H, na.rm = TRUE) / sum(AB, na.rm = TRUE),
возможность = sum(AB, na.rm = TRUE)
)
эффективность %>%
filter(возможность > 100) %>%
ggplot(mapping = aes(x = возможность, y = результативность)) +
geom_point() +
geom_smooth(se = FALSE)
Функция geom_smooth() здесь формирует график методом обобщенных аддитивных моделей с интегрированной оценкой гладкости (method = "gam") рассчитывая значения по формуле formula = y ~ s(x, bs = "cs"), так как имеется более 1 000 наблюдений.
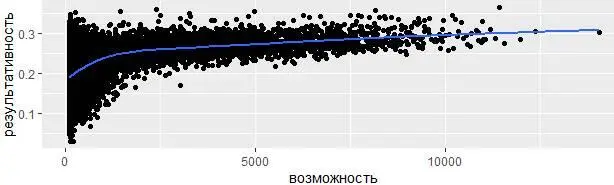
Особый интерес вызывает ранжирование результатов. Если наивно отсортировать показатели эффективности по убыванию результативности, то первыми с самой лучшей результативностью окажутся скорее везучие, а не квалифицированные игроки, за всю карьеру сделавшие лишь 1 удар, но при этом попавшие по мячу:
эффективность %>%
arrange(desc(результативность))
Можно найти хорошее объяснение этого парадокса в пословице «новичкам везёт». Используя простые инструменты, подсчет количества одинаковых значений, их суммирование, можно долго искать любопытные закономерности, но R предоставляет и много других полезных функций для генерации статистических отчетов:
Выше использовалась функция, вычисляющая среднее значение mean( x ), но вычисляющая медианное значение функция median( x ) тоже бывает полезна. Ведь среднее как 36.6° по больнице, а медиана – это величина, относительно которой 50% значений x находится выше, и 50% находится ниже, что гораздо информативнее. Иногда полезно комбинировать подобные функции с логическим условием. Мы еще не говорили о таких вещах как подмножество значений, этому можно посвятить целый раздел, пока лишь приведем наглядный пример, на тех же неотмененных авиарейсах, сгруппированных по дате вылета.
Отрицательные значения «задержки» рейса символизируют прибытие с опережением графика, оказывается, такое тоже бывает:
неотмененные %>% group_by(year, month, day) %>%
summarise(
средняя_задержка = mean(arr_delay),
средняя_положительная_задержка = mean(arr_delay[arr_delay > 0])
)
Особый интерес вызывают функции вычисления стандартного отклонения sd(x), меры разброса наблюдаемой величины, вычисления интерквартильного размаха IQR(x) и вычисления медианы абсолютного отклонения mad(x), которые являются надежными эквивалентами друг друга и могут быть полезны, если у данных есть выбросы. Любопытно, почему расстояние до одних пунктов назначения варьируются сильнее, чем до других, являя собой не иначе как чудеса телепортации:
неотмененные %>% group_by(dest) %>%
summarise(среднеквадратическое_отклонение_дистанции = sd(distance)) %>%
arrange(desc(среднеквадратическое_отклонение_дистанции))
Функции поиска минимального значение min(x), первого квантиля quantile(x, 0.25), вычисления максимума max(x), неизменные спутники при построении ранжирования. Квантили являются обобщением медианы. Так, например, quantile(x, 0.25) найдет значение x , которое больше чем 25% значений из всех возможных значений анализируемой переменной, и меньше чем остальные 75%.
Найдем время отправления первого и последнего рейса каждый день:
неотмененные %>% group_by (year, month, day) %>%
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы статистической обработки педагогической информации»
Представляем Вашему вниманию похожие книги на «Основы статистической обработки педагогической информации» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы статистической обработки педагогической информации» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.