Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
Здесь есть возможность читать онлайн «Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: СПб., Год выпуска: 2018, ISBN: 2018, Издательство: Питер, Жанр: Программирование, Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Владстон Феррейра Фило Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] обложка книги](/books/389524/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp)
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Издательство:Питер
- Жанр:
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Связный список тоже имеет свои недостатки: мы не можем сразу получить n -й элемент. Сначала придется прочитать первую ячейку, извлечь из нее адрес второй ячейки, затем прочитать вторую ячейку, извлечь из нее указатель на следующую ячейку и т. д., пока мы не доберемся до n -й ячейки.
Кроме того, когда известен адрес всего одной ячейки, не так просто ее удалить или переместиться по списку назад. Не имея другой информации, нельзя узнать адрес предыдущей ячейки в цепи.
Двусвязный список
Двусвязный список (double linked list) — это связный список, где ячейки имеют два указателя: один на предыдущую ячейку, другой — на следующую (рис. 4.4).
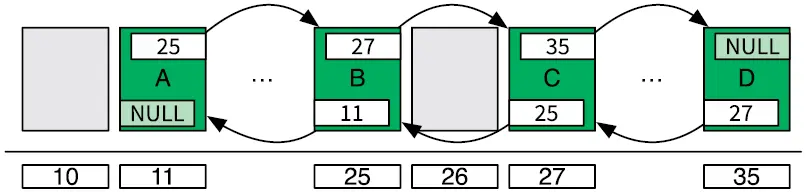
Рис. 4.4.Двусвязный список в памяти компьютера
Он обладает тем же преимуществом, что и связный список: не требует предварительного выделения большого блока памяти, потому что пространство для новых ячеек может выделяться по мере необходимости. При этом дополнительные указатели позволяют двигаться по цепи ячеек вперед и назад. В таком случае, если известен адрес всего одной ячейки, мы сможем быстро ее удалить.
И тем не менее мы по-прежнему не имеем прямого доступа к n -му элементу. Кроме того, для поддержки двух указателей в каждой ячейке требуется более сложный код и больше памяти.
Массивы против связных списков
Языки программирования с богатым набором средств обычно включают встроенные реализации списка, очереди, стека и других АТД. Эти реализации часто основаны на некоторой стандартной структуре данных. Некоторые из них могут даже автоматически переключаться с одной структуры данных на другую во время выполнения программ, в зависимости от способа доступа к данным.
Когда производительность не является проблемой, мы можем опереться на эти универсальные реализации АТД и не переживать по поводу структур данных. Но когда производительность должна быть оптимальной либо когда вы имеете дело с низкоуровневым языком, не имеющим таких встроенных средств, вы сами должны решать, какие структуры данных использовать. Проанализируйте операции, посредством которых вы будете обрабатывать информацию, и выберите реализацию с надлежащей структурой данных. Связные списки предпочтительнее массивов, когда:
• нужно, чтобы операции вставки и удаления выполнялись чрезвычайно быстро;
• не требуется произвольный доступ к данным;
• приходится вставлять или удалять элементы между других элементов;
• заранее не известно количество элементов (оно будет расти или уменьшится по ходу выполнения программы).
Массивы предпочтительнее связных списков, когда:
• нужен произвольный доступ к данным;
• нужен очень быстрый доступ к элементам;
• число элементов не изменяется во время выполнения программы, благодаря чему легко выделить непрерывное пространство памяти.
Дерево
Как и связный список, дерево (tree) использует элементы, которым для хранения объектов не нужно располагаться в физической памяти непрерывно. Ячейки здесь тоже имеют указатели на другие ячейки, однако, в отличие от связных списков, они располагаются не линейно, а в виде ветвящейся структуры. Деревья особенно удобны для иерархических данных, таких как каталоги с файлами или система субординации (рис. 4.5).
В терминологии деревьев ячейка называется узлом , а указатель из одной ячейки на другую — ребром . Самая первая ячейка — это корневой узел , он единственный не имеет родителя. Все остальные узлы в деревьях должны иметь строго одного родителя [47] Если узел нарушает это правило, многие алгоритмы поиска по дереву не будут работать.
.
Два узла с общим родителем называются братскими. Родитель узла, прародитель, прапрародитель (и т. д. вплоть до корневого узла) — это предки. Аналогично дочерние узлы, внуки, правнуки (и т. д. вплоть до нижней части дерева) называются потомками.
Узлы, не имеющие дочерних узлов, — это листья (по аналогии с листьями настоящего дерева  ). Путь между двумя узлами определяется множеством узлов и ребер.
). Путь между двумя узлами определяется множеством узлов и ребер.
Уровень узла — это длина пути от него до корневого узла, высота дерева — уровень самого глубокого узла в дереве (рис. 4.6). И, наконец, множество деревьев называется лесом .
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]»
Представляем Вашему вниманию похожие книги на «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.