Брайан Керниган - Язык программирования Си. Издание 3-е, исправленное
Здесь есть возможность читать онлайн «Брайан Керниган - Язык программирования Си. Издание 3-е, исправленное» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2001, ISBN: 2001, Издательство: Невский Диалект, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Язык программирования Си. Издание 3-е, исправленное
- Автор:
- Издательство:Невский Диалект
- Жанр:
- Год:2001
- Город:Санкт-Петербург
- ISBN:0-13-110362-8
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Язык программирования Си. Издание 3-е, исправленное: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Язык программирования Си. Издание 3-е, исправленное»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для настоящего третьего русского издания перевод заново сверен с оригиналом, в него внесены некоторые поправки, учитывающие устоявшиеся за прошедшие годы изменения в терминологии, а так же учтены замечания, размещенные автором на странице http://cm.bell-labs.com/cm/cs/cbook/2ediffs.html.
Для программистов, преподавателей и студентов.
Издание подготовлено при участии издательства "Финансы и статистика"
Язык программирования Си. Издание 3-е, исправленное — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Язык программирования Си. Издание 3-е, исправленное», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
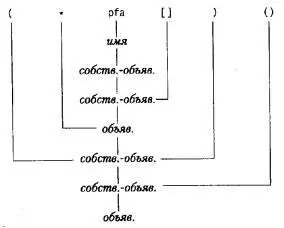
Эту грамматику можно использовать для грамматического разбора объявлений. Рассмотрим, например, такой объявитель:
(*pfa[])()
Имя pfa будет классифицировано как имя и, следовательно, как собственно- объявитель . Затем pfa[] будет распознано как собственно-объявитель , а *pfa[] - как объявитель и, следовательно, (*pfa[]) есть собственно-объявитель . Далее, (*pfa[])() есть собственно-объявитель и, таким образом, объявитель . Этот грамматический разбор можно проиллюстрировать деревом разбора, приведенным на следующей странице (где собственно-объявитель обозначен более коротко, а именно собств.-объяв. ).
Сердцевиной программы обработки объявителя является пара функций dcl и dirdcl , осуществляющих грамматический разбор объявления согласно приведенной грамматике. Поскольку грамматика определена рекурсивно, эти функции обращаются друг к другу рекурсивно, по мере распознавания отдельных частей объявления. Метод, примененный в обсуждаемой программе для грамматического разбора, называется рекурсивным спуском.
/* dcl: разбор объявителя */
void dcl(void)
{
int ns;
for (ns = 0, gettoken() == '*';) /* подсчет звездочек */
ns++;
dirdcl();
while(ns- › 0)
strcat(out, "указ. на");
}
/* dirdcl: разбор собственно объявителя */
void dirdcl(void)
{
int type;
if (tokentype == '(') {
dcl();
if (tokentype != ')')
printf("oшибкa: пропущена)\n");
} else if (tokentype == NAME) /* имя переменной */
strcpy(name, token);
else
printf("ошибка: должно быть name или (dcl)\n");
while((type = gettoken()) == PARENS || type == BRACKETS)
if (type == PARENS)
strcat(out, "функц. возвр.");
else {
strcat(out, " массив");
strcat(out, token);
strcat(out, " из");
}
}
Приведенные программы служат только иллюстративным целям и не вполне надежны. Что касается dcl , то ее возможности существенно ограничены. Она может работать только с простыми типами вроде char и int и не справляется с типами аргументов в функциях и с квалификаторами вроде const . Лишние пробелы для нее опасны. Она не предпринимает никаких мер по выходу из ошибочной ситуации, и поэтому неправильные описания также ей противопоказаны. Устранение этих недостатков мы оставляем для упражнений. Ниже приведены глобальные переменные и главная программа main .
#include ‹stdio.h›
#include ‹string.h›
#include ‹ctype.h›
#define MAXTOKEN 100
enum {NAME, PARENS, BRACKETS};
void dcl(void);
void dirdcl(void);
int gettoken(void);
int tokentype; /* тип последней лексемы */
char token[MAXTOKEN]; /* текст последней лексемы */
char name[MAXTOKEN]; /* имя */
char datatype[MAXTOKEN]; /* тип = char, int и т.д. */
char out[1000]; /* выдаваемый текст */
main() /* преобразование объявления в словесное описание */
{
while (gettoken() != EOF) {/* 1-я лексема в строке */
strcpy(datatype, token); /* это тип данных */
out[0] = '\0';
dcl(); /* разбор остальной части строки */
if (tokentype != '\n')
printf("синтаксическая ошибка\n");
printf("%s: %s %s\n", name, out, datatype);
}
return 0;
}
Функция gettoken пропускает пробелы и табуляции и затем получает следующую лексему из ввода: "лексема" ( token ) - это имя, или пара круглых скобок, или пара квадратных скобок (быть может, с помещенным в них числом), или любой другой единичный символ.
int gettoken(void) /* возвращает следующую лексему */
{
int с, getch(void);
void ungetch(int);
char *p = token;
while ((c = getch()) == ' ' || с == '\t')
;
if (c == '(') {
if ((c = getch()) == ')' {
strcpy(token, "()");
return tokentype = PARENS;
} else {
ungetch(c);
return tokentype = '(';
}
} else if (c == '[') {
for (*p++ = c; (*p++ = getch()) != ']';)
;
*p = '\0';
return tokentype = BRACKETS;
} else if (isalpha(c)) {
for (*p++ = c; isalnum(c = getch());)
*p++ = c;
*p = '\0';
ungetch(c);
return tokentype = NAME;
} else
return tokentype = c;
}
Функции getch и ungetch были рассмотрены в главе 4.
Обратное преобразование реализуется легче, особенно если не придавать значения тому, что будут генерироваться лишние скобки. Программа undcl превращает фразу вроде "x есть функция, возвращающая указатель на массив указателей на функции, возвращающие char ", которую мы будем представлять в виде
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Язык программирования Си. Издание 3-е, исправленное»
Представляем Вашему вниманию похожие книги на «Язык программирования Си. Издание 3-е, исправленное» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.

![Виктор Суворов - Тень Победы [Новое издание, исправленное и переработанное]](/books/69098/viktor-suvorov-ten-pobedy-novoe-izdanie-ispravl-thumb.webp)





![Коллектив авторов Биографии и мемуары - Ковалиная книга. Вспоминая Юрия Коваля [второе издание, исправленное и дополненное]](/books/430445/kollektiv-avtorov-biografii-i-memuary-kovalinaya-kn-thumb.webp)




Обсуждение, отзывы о книге «Язык программирования Си. Издание 3-е, исправленное» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.