Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi
Здесь есть возможность читать онлайн «Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2003, ISBN: 2003, Издательство: ДиаСофтЮП, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Фундаментальные алгоритмы и структуры данных в Delphi
- Автор:
- Издательство:ДиаСофтЮП
- Жанр:
- Год:2003
- ISBN:ISBN 5-93772-087-3
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Фундаментальные алгоритмы и структуры данных в Delphi: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Фундаментальные алгоритмы и структуры данных в Delphi»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В книге подробно рассматриваются базовые понятия алгоритмов и основополагающие структуры данных, алгоритмы сортировки, поиска, хеширования, синтаксического разбора, сжатия данных, а также многие другие темы, тесно связанные с прикладным программированием. Изобилие тщательно проверенных примеров кода существенно ускоряет не только освоение фундаментальных алгоритмов, но также и способствует более квалифицированному подходу к повседневному программированию.
Несмотря на то что книга рассчитана в первую очередь на профессиональных разработчиков приложений на Delphi, она окажет несомненную пользу и начинающим программистам, демонстрируя им приемы и трюки, которые столь популярны у истинных «профи». Все коды примеров, упомянутые в книге, доступны для выгрузки на Web-сайте издательства.
Фундаментальные алгоритмы и структуры данных в Delphi — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Фундаментальные алгоритмы и структуры данных в Delphi», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
По сравнению с классом TList связные списки требуют большего объема памяти. В качестве ссылки на элемент в TList используется один указатель, т.е. в массиве TList для каждого элемента требуется, по крайней мере, sizeof(pointer) байт. С другой стороны, односвязный список содержит два указателя: указатель на данные и указатель на следующий элемент. Таким образом, для каждого элемента в односвязном списке нужно, по меньшей мере, 2*sizeof(pointer) байт.
Очевидно, что для каждого элемента в двухсвязном списке требуется не менее 3*sizeof(pointer) байт.
Но это еще не все. Если неэффективно использовать массив TList (другими словами, не использовать свойство Capacity для установки размера массива), будут распределяться несколько блоков памяти, каждый из которых больше предыдущего, и потребуется больший объем работ, связанный с копированием данных массива. Если элементы вставляются только в начало, быстродействие массива TList существенно уменьшается. В настоящей книге будут приведены несколько реализаций алгоритмов и структур данных, которые позволяют достичь для связных списков гораздо большей эффективности, нежели это показывает TList, однако в общем случае массив TList лучше, быстрее и эффективнее связных списков.
Стеки
Еще одной известной и широко используемой структурой данных является стек. Стек представляет собой структуру, которая позволяет выполнять две основных операции: заталкивание для вставки элемента в стек и выталкивание с целью считывания данных из стека. Структура устроена таким образом, что операция выталкивания всегда возвращает элемент, вставленный в стек последним (самый "новый" элемент в стеке). Другими словами, элементы в стеке считываются в порядке, обратном порядку их записи в стек. Благодаря такому устройству стек известен как контейнер магазинного типа.
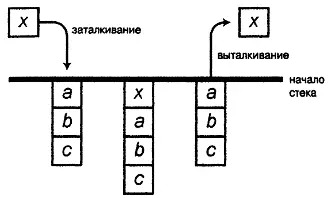
Рисунок 3.7. Операции заталкивания и выталкивания для стека
Написание кода стека не представляет никаких трудностей. Причем существуют два варианта реализации: первый - на основе односвязного списка, второй -на основе массива. Как и в случае со списками, будем считать, что записываться и считываться из стека будут указатели на элементы. Сначала рассмотрим организацию стека на базе связного списка.
Стеки на основе односвязных списков
В реализации стеков на основе односвязных списков операция заталкивания представляет собой вставку элемента в начало списка, а операция выталкивания - удаление элемента из начала списка и считывание его данных. Обе операции не зависят от количества элементов в списке, следовательно, их можно отнести к классу O(1). Вот и все, что касается организации стека.
Конечно, реализация описанной организации требует большего объема в плане принятия решений. Класс стека можно реализовать как дочерний класса односвязного списка или делегировать операции заталкивания и выталкивания внутреннему экземпляру класса связного списка. Первый вариант не особенно эффективен: мы придем к реализации класса с методами Push и Pop, но при этом у нас останутся и другие методы связного списка (Insert, Delete и т.д.). Понятно, что это не самое лучшее решение.
Второй вариант реализации, делегирование, - чисто в духе Delphi. Класс стека можно организовать именно таким образом. Конструктор Create будет создавать новый экземпляр класса TtdSingleLinkList и устанавливать курсор после начального узла, деструктор Destroy будет уничтожать созданный конструктором экземпляр. Метод Push будет пользоваться экземпляром класса для вставки элемента в позицию курсора, а метод Pop будет удалять элемент в позиции курсора, предварительно сохранив его значение. Вполне реализуемое решение.
Тем не менее, мы будем писать класс TtdStack, исходя из первых принципов. TtdStack - простой класс, и за счет этого мы попытаемся увеличить его быстродействие и эффективность.
Листинг 3.18. Класс TtdStack
TtdStack = class private
FCount : longint;
FDispose : TtdDisposeProc;
FHead : PslNode;
FName : TtdNameString;
protected
procedure sError(aErrorCode : integer;
const aMethodName : TtdNameString);
class procedure sGetNodeManager;
public
constructor Create(aDispose : TtdDisposeProc);
destructor Destroy; override;
procedure Clear;
function Examine : pointer;
function IsEmpty : boolean;
function Pop : pointer;
procedure Push(aItem : pointer);
property Count : longint read FCount;
property Name : TtdNameString read FName write FName;
end;
Метод Examine возвращает первый элемент стека, не выталкивая его из стека. Он бывает очень удобным в использовании, поскольку не требует выталкивания элемента с последующим заталкиванием. Метод IsEmpty возвращает значение true, если стек пуст, что эквивалентно проверке равенства нулю свойства Count.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Фундаментальные алгоритмы и структуры данных в Delphi»
Представляем Вашему вниманию похожие книги на «Фундаментальные алгоритмы и структуры данных в Delphi» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Фундаментальные алгоритмы и структуры данных в Delphi» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.