Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi
Здесь есть возможность читать онлайн «Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2003, ISBN: 2003, Издательство: ДиаСофтЮП, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Фундаментальные алгоритмы и структуры данных в Delphi
- Автор:
- Издательство:ДиаСофтЮП
- Жанр:
- Год:2003
- ISBN:ISBN 5-93772-087-3
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Фундаментальные алгоритмы и структуры данных в Delphi: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Фундаментальные алгоритмы и структуры данных в Delphi»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В книге подробно рассматриваются базовые понятия алгоритмов и основополагающие структуры данных, алгоритмы сортировки, поиска, хеширования, синтаксического разбора, сжатия данных, а также многие другие темы, тесно связанные с прикладным программированием. Изобилие тщательно проверенных примеров кода существенно ускоряет не только освоение фундаментальных алгоритмов, но также и способствует более квалифицированному подходу к повседневному программированию.
Несмотря на то что книга рассчитана в первую очередь на профессиональных разработчиков приложений на Delphi, она окажет несомненную пользу и начинающим программистам, демонстрируя им приемы и трюки, которые столь популярны у истинных «профи». Все коды примеров, упомянутые в книге, доступны для выгрузки на Web-сайте издательства.
Фундаментальные алгоритмы и структуры данных в Delphi — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Фундаментальные алгоритмы и структуры данных в Delphi», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Аналогично применению алгоритма Шеннона-Фано, нужно построить бинарное дерево, которое также будет префиксным деревом, где все данные хранятся в листьях. Но в отличие от алгоритма Шеннона-Фано, который является нисходящим, на этот раз построение будет выполняться снизу вверх. Вначале мы выполняем просмотр входных данных, подсчитывая количество появлений значений каждого байта, как это делалось и при использовании алгоритма Шеннона-Фано. Как только эта таблица частоты появления символов будет создана, можно приступить к построению дерева.
Будем считать эти пары символ-количество "пулом" узлов будущего дерева Хаффмана. Удалим из этого пула два узла с наименьшими значениями количества появлений. Присоединим их к новому родительскому узлу и установим значение счетчика родительского узла равным сумме счетчиков его двух дочерних узлов. Поместим родительский узел обратно в пул. Продолжим этот процесс удаления двух узлов и добавления вместо них одного родительского узла до тех пор, пока в пуле не останется только один узел. На этом этапе можно удалить из пула один узел. Он является корневым узлом дерева Хаффмана.
Описанный процесс не очень нагляден, поэтому создадим дерево Хаффмана для предложения "How much wood could a woodchuck chuck?" Мы уже вычислили количество появлений символов этого предложения и представили их в виде таблицы 11.1, поэтому теперь к ней потребуется применить описанный алгоритм с целью построения полного дерева Хаффмана. Выберем два узла с наименьшими значениями. Существует несколько узлов, из которых можно выбрать, но мы выберем узлы "m" и Для обоих этих узлов число появлений символов равно 1. Создадим родительский узел, значение счетчика которого равно 2, и присоединим к нему два выбранных узла в качестве дочерних. Поместим родительский узел обратно в пул. Повторим цикл с самого начала. На этот раз мы выбираем узлы "а" и "Д.", объединяем их в мини-дерево и помещаем родительский узел (значение счетчика которого снова равно 2) обратно в пул. Снова повторим цикл. На этот раз в нашем распоряжении имеется единственный узел, значение счетчика которого равно 1 (узел "Н") и три узла со значениями счетчиков, равными 2 (узел "к" и два родительских узла, которые были добавлены перед этим). Выберем узел "к", присоединим его к узлу "H" и снова добавим в пул родительский узел, значение счетчика которого равно 3. Затем выберем два родительских узла со значениями счетчиков, равными 2, присоединим их к новому родительскому узлу со значением счетчика, равным 4, и добавим этот родительский узел в пул. Несколько первых шагов построения дерева Хаффмана и результирующее дерево показаны на рис. 11.2.
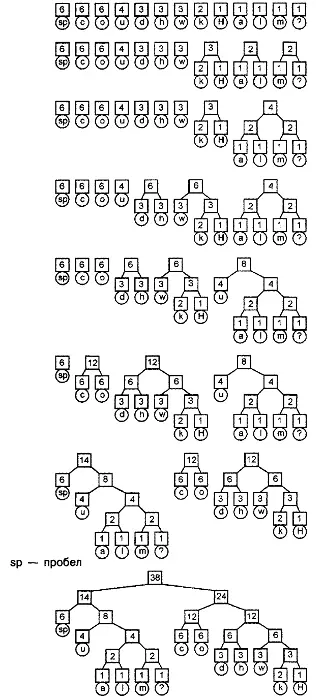
Рисунок 11.2. Построение дерева Хоффмана
Используя это дерево точно так же, как и дерево, созданное для кодирования Шеннона-Фано, можно вычислить код для каждого из символов в исходном предложении и построить таблицу 11.5.
Таблица 11.5. Коды Хаффмана для символов примера предложения
Символ - Количество появлений
Пробел - 00
c - 100
o - 101
u - 010
d - 1100
h - 1101
w - 1110
k - 11110
H - 11111
a - 01100
l - 01101
m - 01110
? - 01111
Обратите внимание, что эта таблица кодов - не единственная возможная. Каждый раз, когда имеется три или больше узлов, из числа которых нужно выбрать два, существуют альтернативные варианты результирующего дерева и, следовательно, результирующих кодов. Но на практике все эти возможные варианты деревьев и кодов будут обеспечивать максимальное сжатие. Все они эквивалентны.
Теперь можно вычислить код для всего предложения. Он начинается с битов:
1111110111100001110010100...
и содержит всего 131 бит. Если бы исходное предложение было закодировано кодами ASCII, по одному байту на символ, оно содержало бы 286 битов. Таким образом, в данном случае коэффициент сжатия составляет приблизительно 54%.
Повторим снова, что, как и при применении алгоритма Шеннона-Фано, необходимо каким-то образом сжать дерево и включить его в состав сжатых данных.
Восстановление выполняется совершенно так же, как при использовании кодирования Шеннона-Фано: необходимо восстановить дерево из данных, хранящихся в сжатом потоке, и затем воспользоваться им для считывания сжатого потока битов.
Рассмотрим кодирование Хаффмана с высокоуровневой точки зрения. В ходе реализации каждого из методов сжатия, которые будут описаны в этой главе, мы создадим простую подпрограмму, которая принимает как входной, так и выходной поток, и сжимает все данные входного потока и помещает их в выходной поток.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Фундаментальные алгоритмы и структуры данных в Delphi»
Представляем Вашему вниманию похожие книги на «Фундаментальные алгоритмы и структуры данных в Delphi» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Фундаментальные алгоритмы и структуры данных в Delphi» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.