Pedro Domingos - The Master Algorithm - How the Quest for the Ultimate Learning Machine Will Remake Our World
Здесь есть возможность читать онлайн «Pedro Domingos - The Master Algorithm - How the Quest for the Ultimate Learning Machine Will Remake Our World» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Прочая околокомпьтерная литература, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Machine learning is the automation of discovery-the scientific method on steroids-that enables intelligent robots and computers to program themselves. No field of science today is more important yet more shrouded in mystery. Pedro Domingos, one of the field’s leading lights, lifts the veil for the first time to give us a peek inside the learning machines that power Google, Amazon, and your smartphone. He charts a course through machine learning’s five major schools of thought, showing how they turn ideas from neuroscience, evolution, psychology, physics, and statistics into algorithms ready to serve you. Step by step, he assembles a blueprint for the future universal learner-the Master Algorithm-and discusses what it means for you, and for the future of business, science, and society.
If data-ism is today’s rising philosophy, this book will be its bible. The quest for universal learning is one of the most significant, fascinating, and revolutionary intellectual developments of all time. A groundbreaking book, The Master Algorithm is the essential guide for anyone and everyone wanting to understand not just how the revolution will happen, but how to be at its forefront.
The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Another popular method is to prefer simpler hypotheses. The “divide and conquer” algorithm implicitly prefers simpler rules because it stops adding conditions to a rule as soon as it covers only positive examples and stops adding rules as soon as all positive examples are covered. But to combat overfitting, we need a stronger preference for simpler rules, one that will cause us to stop adding conditions even before all negative examples have been covered. For example, we can subtract a penalty proportional to the length of the rule from its accuracy and use that as an evaluation measure.
The preference for simpler hypotheses is popularly known as Occam’s razor, but in a machine-learning context this is somewhat misleading. “Entities should not be multiplied beyond necessity,” as the razor is often paraphrased, just means choosing the simplest theory that fits the data. Occam would probably have been perplexed by the notion that we should prefer a theory that does not perfectly account for the evidence on the grounds that it will generalize better. Simple theories are preferable because they incur a lower cognitive cost (for us) and a lower computational cost (for our algorithms), not because we necessarily expect them to be more accurate. On the contrary, even our most elaborate models are usually oversimplifications of reality. Even among theories that perfectly fit the data, we know from the “no free lunch” theorem that there’s no guarantee that the simplest one will generalize best, and in fact some of the best learning algorithms-like boosting and support vector machines-learn what appear to be gratuitously complex models. (We’ll see why they work in Chapters 7 and 9.)
If your learner’s test-set accuracy disappoints, you need to diagnose the problem. Was it blindness or hallucination? In machine learning, the technical terms for these are bias and variance . A clock that’s always an hour late has high bias but low variance. If instead the clock alternates erratically between fast and slow but on average tells the right time, it has high variance but low bias. Suppose you’re down at the pub with some friends, drinking and playing darts. Unbeknownst to them, you’ve been practicing for years, and you’re a master of the game. All your darts go straight to the bull’s-eye. You have low bias and low variance, which is shown in the bottom left corner of this diagram:
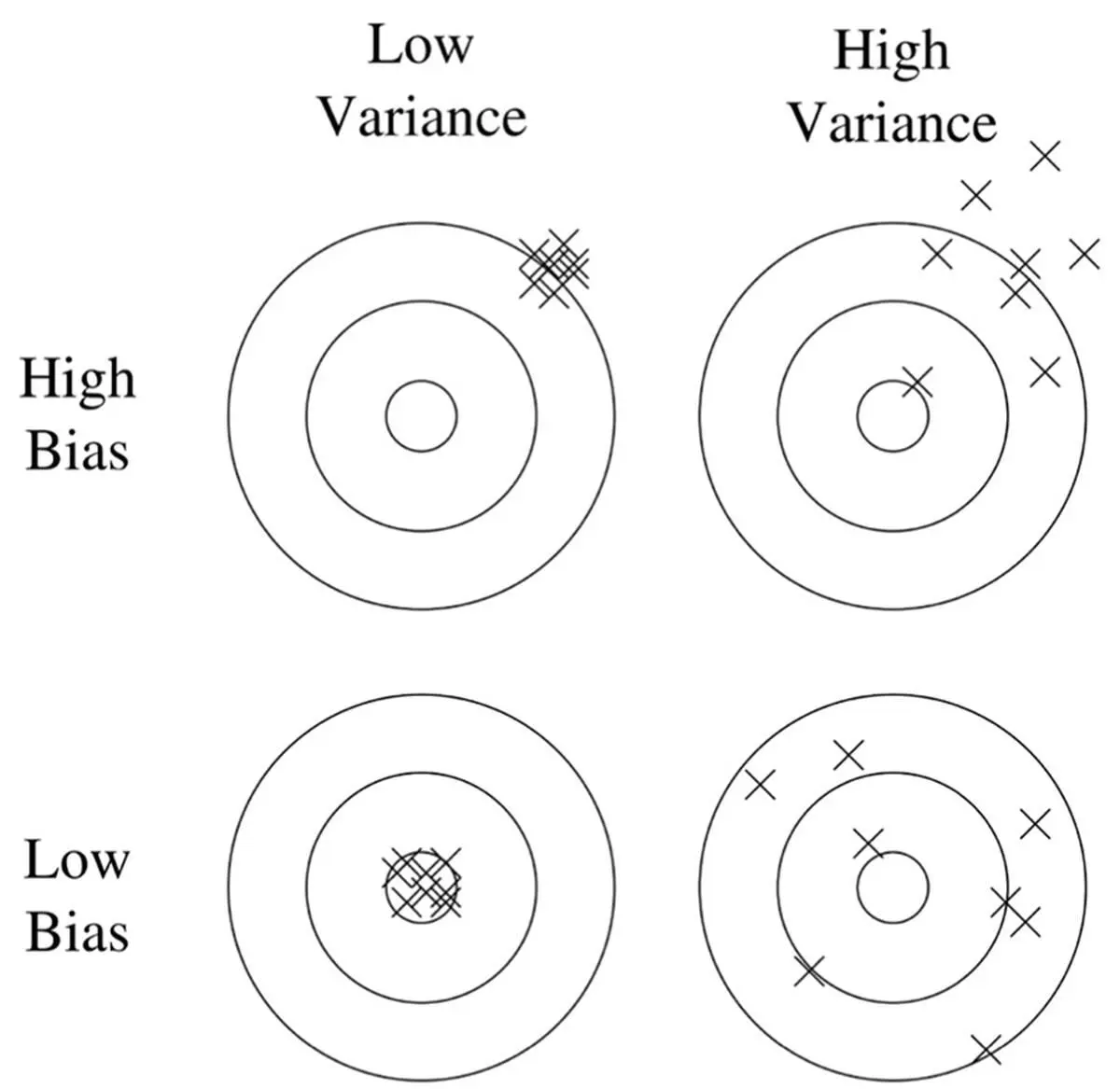
Your friend Ben is also pretty good, but he’s had a bit too much to drink. His darts are all over, but he loudly points out that on average he’s hitting the bull’s-eye. (Maybe he should have been a statistician.) This is the low-bias, high-variance case, shown in the bottom right corner. Ben’s girlfriend, Ashley, is very steady, but she has a tendency to aim too high and to the right. She has low variance and high bias (top left corner). Cody, who’s visiting from out of town and has never played darts before, is both all over and off center. He has both high bias and high variance (top right).
You can estimate the bias and variance of a learner by comparing its predictions after learning on random variations of the training set. If it keeps making the same mistakes, the problem is bias, and you need a more flexible learner (or just a different one). If there’s no pattern to the mistakes, the problem is variance, and you want to either try a less flexible learner or get more data. Most learners have a knob you can turn to make them more or less flexible, such as the threshold for significance tests or the penalty on the size of the model. Tweaking that knob is your first resort.
Induction is the inverse of deduction
The deeper problem, however, is that most learners start out knowing too little, and no amount of knob-twiddling will get them to the finish line. Without the guidance of an adult brain’s worth of knowledge, they can easily go astray. Even though it’s what most learners do, just assuming you know the form of the truth (for example, that it’s a small set of rules) is not much to hang your hat on. A strict empiricist would say that that’s all a newborn has, encoded in her brain’s architecture, and indeed children overfit more than adults do, but we would like to learn faster than a child does. (Eighteen years is a long time, and that’s not counting college.) The Master Algorithm should be able to start with a large body of knowledge, whether it was provided by humans or learned in previous runs, and use it to guide new generalizations from data. That’s what scientists do, and it’s as far as it gets from a blank slate. The “divide and conquer” rule induction algorithm can’t do it, but there’s another way to learn rules that can.
The key is to realize that induction is just the inverse of deduction, in the same way that subtraction is the inverse of addition, or integration the inverse of differentiation. This idea was first proposed by William Stanley Jevons in the late 1800s. Steve Muggleton and Wray Buntine, an English Australian team, designed the first practical algorithm based on it in 1988. The strategy of taking a well-known operation and figuring out its inverse has a storied history in mathematics. Applying it to addition led to the invention of the integers, because without negative numbers, addition doesn’t always have an inverse (3 – 4 = -1). Similarly, applying it to multiplication led to the rationals, and applying it to squaring led to complex numbers. Let’s see if we can apply it to deduction. A classic example of deductive reasoning is:
Socrates is human.
All humans are mortal.
Therefore…?…
The first statement is a fact about Socrates, and the second is a general rule about humans. What follows? That Socrates is mortal, of course, by applying the rule to Socrates. In inductive reasoning we start instead with the initial and derived facts, and look for a rule that would allow us to infer the latter from the former:
Socrates is human.
…?…
Therefore Socrates is mortal.
One such rule is: If Socrates is human, then he’s mortal. This does the job, but is not very useful because it’s specific to Socrates. But now we apply Newton’s principle and generalize the rule to all entities: If an entity is human, then it’s mortal. Or, more succinctly: All humans are mortal. Of course, it would be rash to induce this rule from Socrates alone, but we know similar facts about other humans:
Plato is human. Plato is mortal.
Aristotle is human. Aristotle is mortal.
And so on.
For each pair of facts, we construct the rule that allows us to infer the second fact from the first one and generalize it by Newton’s principle. When the same general rule is induced over and over again, we can have some confidence that it’s true.
So far we haven’t done anything that the “divide and conquer” algorithm couldn’t do. Suppose, however, that instead of knowing that Socrates, Plato, and Aristotle are human, we just know that they’re philosophers. We still want to conclude that they’re mortal, and we have previously induced or been told that all humans are mortal. What’s missing now? A different rule: All philosophers are human. This also a valid generalization (at least until we solve AI and robots start philosophizing), and it “fills the hole” in our reasoning:
Socrates is a philosopher.
All philosophers are human.
All humans are mortal.
Therefore Socrates is mortal.
We can also induce rules purely from other rules. If we know that all philosophers are human and mortal, we can induce that all humans are mortal. (We don’t induce that all mortals are human because we know other mortal creatures, like cats and dogs. On the other hand, scientists, artists, and so on are also human and mortal, reinforcing the rule.) In general, the more rules and facts we start out with, the more opportunities we have to induce new rules using “inverse deduction.” And the more rules we induce, the more rules we can induce. It’s a virtuous circle of knowledge creation, limited only by overfitting risk and computational cost. But here, too, having initial knowledge helps: if instead of one large hole we have many small ones to fill, our induction steps will be less risky and therefore less likely to overfit. (For example, given the same number of examples, inducing that all philosophers are human is less risky than inducing that all humans are mortal.)
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World»
Представляем Вашему вниманию похожие книги на «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.