Тимур Машнин - Введение в облачные и распределенные информационные системы
Здесь есть возможность читать онлайн «Тимур Машнин - Введение в облачные и распределенные информационные системы» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Жанр: Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Введение в облачные и распределенные информационные системы
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:9785005303110
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Введение в облачные и распределенные информационные системы: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Введение в облачные и распределенные информационные системы»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Введение в облачные и распределенные информационные системы — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Введение в облачные и распределенные информационные системы», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Так, например, если сервер имеет 4 ядра и 4 гигабайта ОЗУ, в каждом контейнере есть одно ядро и 1 гигабайт ОЗУ, и у этого сервера есть 4 контейнера и, по существу, он может выполнять четыре задачи по одной в каждом контейнере.
YARN имеет три основных компонента.
Это менеджер ресурсов, администраторы узлов и мастера приложений.
И существует один глобальный менеджер ресурсов, который запускает планировщика.
Существует один менеджер узла на один сервер в системе.
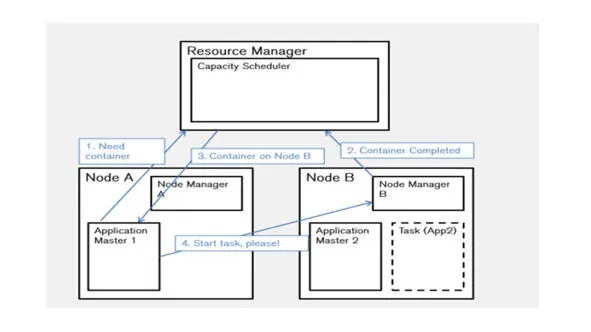
Это Daemon, который отвечает за все специфическое управление сервером, а также отвечает за мониторинг сбоев задач, которые выполняются на этой конкретной машине.
Затем есть Application Master, или мастер приложения, который также работает на одном из серверов, и отвечает за согласование контейнеров с диспетчером ресурсов и менеджерами узлов.
Он также отвечает за взаимодействие с менеджерами узлов, чтобы выяснить, умер ли какой-либо из них, чтобы перенести с него запущенные задачи.
Теперь давайте посмотрим, как MapReduce разбирается с ошибками.
Наиболее частой ошибкой является отказ самого сервера, и отказ сервера может привести к сбою нескольких компонентов Hadoop планировщика YARN.
Серверы запускают менеджеров узлов, у них запущены задачи, на одном из серверов работает диспетчер ресурсов, а также может работать мастер приложений.
И для решения проблем с отказами серверов, есть пульсация.
Менеджер узла на каждом сервере отправляет пульсацию центральному менеджеру ресурсов.
И если сервер не работает, и эта пульсация останавливается, менеджер ресурсов знает, что менеджер узла не работает.
Он дает знать об этом всем мастерам приложений, и мастера приложений перенаправляют свои задачи.
Менеджер узлов отслеживает каждую задачу, запущенную на своем сервере, поэтому, если одна из задач выходит из строя, эта задача помечается как протаивающая, и, либо менеджер узла ее перезапускает, если это возможно, либо он сообщает диспетчеру ресурсов или мастеру приложения, что эта задача не выполнена.
И наконец, мастер приложения также периодически пульсирует менеджеру ресурсов.
Если, мастер приложения не работает, менеджер ресурсов перезапустит мастер приложения, и он затем синхронизируется с его запущенными задачами.
Далее сам менеджер ресурсов может перестать работать.
В этом случае, чтобы справиться с этим, поддерживается вторичное жесткое резервное копирование, чтобы вторичный менеджер ресурсов мог сразу заработать после отказа менеджера ресурсов.
Протокол Gossip

Далее мы рассмотрим класс протоколов, называемый gossip протоколами сплетен или эпидемическими протоколами.
Но сначала начнем с постановки задачи.
Задача, которую gossip пытается решить, называется групповой передачей multicast.
Итак, что такое групповая передача?
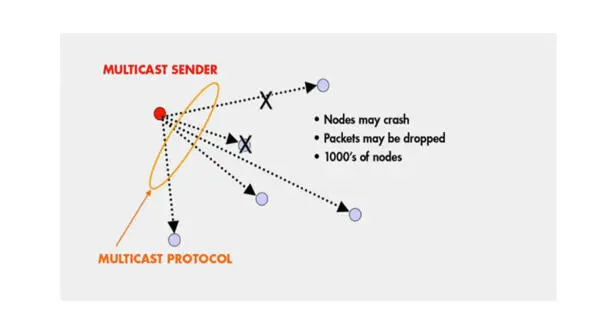
Предположим, что у вас есть группа процессов, или группа узлов.
И каждый из этих процессов или каждый из этих узлов является процессом на каком-либо хосте в Интернете или процессом, подключенном к сети.
И, по сути, все, что нам нужно, это чтобы эти процессы или узлы могли взаимодействовать друг с другом, отправляя и получая сообщения.
Это задача многоадресной рассылки.
Это задача, когда вы хотите получить информацию от других членов вашей группы и, конечно же, здесь я показываю только одно сообщение многоадресной рассылки, но может быть одновременно много сообщений многоадресной рассылки, каждое из которых от потенциально другого отправителя.
Теперь, многоадресная рассылка отличается от широковещательной трансляции, где у вас есть блок информации, который вы хотите отправить на всю сеть, – многоадресная рассылка более ограничена.
Она работает только внутри определенной группы узлов или группы процессов.
Итак, какие требования для протокола многоадресной рассылки?
Ну, два из самых важных требований для облачных вычислений, это отказоустойчивость и масштабируемость.
Вы хотите, чтобы ваша многоадресная рассылка была надежной, и чтобы все определенные получатели получили эту рассылку, несмотря на сбои и задержки, которые могут произойти в сети.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Введение в облачные и распределенные информационные системы»
Представляем Вашему вниманию похожие книги на «Введение в облачные и распределенные информационные системы» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Введение в облачные и распределенные информационные системы» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.