Christopher Hallinan - Embedded Linux Primer - A Practical, Real-World Approach
Здесь есть возможность читать онлайн «Christopher Hallinan - Embedded Linux Primer - A Practical, Real-World Approach» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2006, ISBN: 2006, Издательство: Prentice Hall, Жанр: ОС и Сети, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Embedded Linux Primer: A Practical, Real-World Approach
- Автор:
- Издательство:Prentice Hall
- Жанр:
- Год:2006
- ISBN:978-0-13-167984-9
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Embedded Linux Primer: A Practical, Real-World Approach: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Embedded Linux Primer: A Practical, Real-World Approach»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book brings together indispensable knowledge for building efficient, high-value, Linux-based embedded products: information that has never been assembled in one place before. Drawing on years of experience as an embedded Linux consultant and field application engineer, Christopher Hallinan offers solutions for the specific technical issues you're most likely to face, demonstrates how to build an effective embedded Linux environment, and shows how to use it as productively as possible.
Hallinan begins by touring a typical Linux-based embedded system, introducing key concepts and components, and calling attention to differences between Linux and traditional embedded environments. Writing from the embedded developer's viewpoint, he thoroughly addresses issues ranging from kernel building and initialization to bootloaders, device drivers to file systems.
Hallinan thoroughly covers the increasingly popular BusyBox utilities; presents a step-by-step walkthrough of porting Linux to custom boards; and introduces real-time configuration via CONFIG_RT--one of today's most exciting developments in embedded Linux. You'll find especially detailed coverage of using development tools to analyze and debug embedded systems--including the art of kernel debugging.
• Compare leading embedded Linux processors
• Understand the details of the Linux kernel initialization process
• Learn about the special role of bootloaders in embedded Linux systems, with specific emphasis on U-Boot
• Use embedded Linux file systems, including JFFS2--with detailed guidelines for building Flash-resident file system images
• Understand the Memory Technology Devices subsystem for flash (and other) memory devices
• Master gdb, KGDB, and hardware JTAG debugging
• Learn many tips and techniques for debugging within the Linux kernel
• Maximize your productivity in cross-development environments
• Prepare your entire development environment, including TFTP, DHCP, and NFS target servers
• Configure, build, and initialize BusyBox to support your unique requirements
Embedded Linux Primer: A Practical, Real-World Approach — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Embedded Linux Primer: A Practical, Real-World Approach», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
In Linux, we refer to two distinctly separate operational contexts, based on the environment in which a given thread [13] The term thread here is used in the generic sense to indicate any sequential flow of instructions.
is executing. Threads executing entirely within the kernel are said to be operating in kernel context, while application programs are said to operate in user space context . A user space process can access only memory it owns, and uses kernel system calls to access privileged resources such as file and device I/O. An example might make this more clear.
Consider an application that opens a file and issues a read request (see Figure 2-6). The read function call begins in user space, in the C library read() function. The C library then issues a read request to the kernel. The read request results in a context switch from the user's program to the kernel, to service the request for the file's data. Inside the kernel, the read request results in a hard-drive access requesting the sectors containing the file's data.
Figure 2-6. Simple file read request
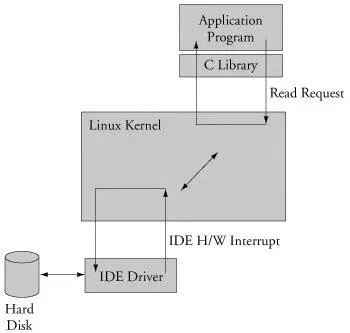
Usually the hard-drive read is issued asynchronously to the hardware itself. That is, the request is posted to the hardware, and when the data is ready, the hardware interrupts the processor. The application program waiting for the data is blocked on a wait queue until the data is available. Later, when the hard disk has the data ready, it posts a hardware interrupt. (This description is intentionally simplified for the purposes of this illustration.) When the kernel receives the hardware interrupt, it suspends whatever process was executing and proceeds to read the waiting data from the drive. This is an example of a thread of execution operating in kernel context.
To summarize this discussion, we have identified two general execution contexts, user space and kernel space. When an application program executes a system call that results in a context switch and enters the kernel, it is executing kernel code on behalf of a process. You will often hear this referred to as process context within the kernel. In contrast, the interrupt service routine (ISR) handling the IDE drive (or any other ISR, for that matter) is kernel code that is not executing on behalf of any particular process. Several limitations exist in this operational context, including the limitation that the ISR cannot block (sleep) or call any kernel functions that might result in blocking. For further reading on these concepts, consult Section 2.5.1, "Suggestions for Additional Reading," at the end of this chapter.
2.3.7. Process Virtual Memory
When a process is spawnedfor example, when the user types ls at the Linux command promptthe kernel allocates memory for the process and assigns a range of virtual-memory addresses to the process. The resulting address values bear no fixed relationship to those in the kernel, nor to any other running process. Furthermore, there is no direct correlation between the physical memory addresses on the board and the virtual memory as seen by the process. In fact, it is not uncommon for a process to occupy multiple different physical addresses in main memory during its lifetime as a result of paging and swapping.
Listing 2-4 is the venerable "Hello World," as modified to illustrate the previous concepts. The goal with this example is to illustrate the address space that the kernel assigns to the process. This code was compiled and run on the AMCC Yosemite board, described earlier in this chapter. The board contains 256MB of DRAM memory.
Listing 2-4. Hello World, Embedded Style
#include
int bss_var; /* Uninitialized global variable */
int data_var = 1; /* Initialized global variable */
int main(int argc, char **argv) {
void *stack_var; /* Local variable on the stack */
stack_var = (void *)main; /* Don't let the compiler optimize it out */
printf("Hello, World! Main is executing at %p\n", stack_var);
printf("This address (%p) is in our stack frame\n", &stack_var);
/* bss section contains uninitialized data */
printf("This address (%p) is in our bss section\n", &bss_var);
/* data section contains initializated data */
printf("This address (%p) is in our data section\n", &data_var);
return 0;
}
Listing 2-5 shows the console output that this program produces. Notice that the process called hello thinks it is executing somewhere in high RAM just above the 256MB boundary (0x10000418). Notice also that the stack address is roughly halfway into a 32-bit address space, well beyond our 256MB of RAM (0x7ff8ebb0). How can this be? DRAM is usually contiguous in systems like these. To the casual observer, it appears that we have nearly 2GB of DRAM available for our use. These virtual addresses were assigned by the kernel and are backed by physical RAM somewhere within the 256MB range of available memory on the Yosemite board.
Listing 2-5. Hello Output
root@amcc:~# ./hello
Hello, World! Main is executing at 0x10000418
This address (0x7ff8ebb0) is in our stack frame
This address (0x10010a1c) is in our bss section
This address (0x10010a18) is in our data section
root@amcc:~#
One of the characteristics of a virtual memory system is that when available physical RAM goes below a designated threshold, the kernel can swap memory pages out to a bulk storage medium, usually a hard disk drive. The kernel examines its active memory regions, determines which areas in memory have been least recently used, and swaps these memory regions out to disk, to free them up for the current process. Developers of embedded systems often disable swapping on embedded systems because of performance or resource constraints. For example, it would be ridiculous in most cases to use a relatively slow Flash memory device with limited write life cycles as a swap device. Without a swap device, you must carefully design your applications to exist within the limitations of your available physical memory.
2.3.8. Cross-Development Environment
Before we can develop applications and device drivers for an embedded system, we need a set of tools (compiler, utilities, and so on) that will generate binary executables in the proper format for the target system. Consider a simple application written on your desktop PC, such as the traditional "Hello World" example. After you have created the source code on your desktop, you invoke the compiler that came with your desktop system (or that you purchased and installed) to generate a binary executable image. That image file is properly formatted to execute on the machine on which it was compiled. This is referred to as native compilation. That is, using compilers on your desktop system, you generate code that will execute on that desktop system.
Note that native does not imply an architecture. Indeed, if you have a toolchain that runs on your target board, you can natively compile applications for your target's architecture. In fact, one great way to test a new kernel and custom board is to repeatedly compile the Linux kernel on it.
Developing software in a cross-development environment requires that the compiler running on your development host output a binary executable that is incompatible with the desktop development workstation on which it was compiled. The primary reason these tools exist is that it is often impractical or impossible to develop and compile software natively on the embedded system because of resource (typically memory and CPU horsepower) constraints.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Embedded Linux Primer: A Practical, Real-World Approach»
Представляем Вашему вниманию похожие книги на «Embedded Linux Primer: A Practical, Real-World Approach» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Embedded Linux Primer: A Practical, Real-World Approach» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.