Christopher Hallinan - Embedded Linux Primer - A Practical, Real-World Approach
Здесь есть возможность читать онлайн «Christopher Hallinan - Embedded Linux Primer - A Practical, Real-World Approach» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2006, ISBN: 2006, Издательство: Prentice Hall, Жанр: ОС и Сети, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Embedded Linux Primer: A Practical, Real-World Approach
- Автор:
- Издательство:Prentice Hall
- Жанр:
- Год:2006
- ISBN:978-0-13-167984-9
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Embedded Linux Primer: A Practical, Real-World Approach: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Embedded Linux Primer: A Practical, Real-World Approach»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book brings together indispensable knowledge for building efficient, high-value, Linux-based embedded products: information that has never been assembled in one place before. Drawing on years of experience as an embedded Linux consultant and field application engineer, Christopher Hallinan offers solutions for the specific technical issues you're most likely to face, demonstrates how to build an effective embedded Linux environment, and shows how to use it as productively as possible.
Hallinan begins by touring a typical Linux-based embedded system, introducing key concepts and components, and calling attention to differences between Linux and traditional embedded environments. Writing from the embedded developer's viewpoint, he thoroughly addresses issues ranging from kernel building and initialization to bootloaders, device drivers to file systems.
Hallinan thoroughly covers the increasingly popular BusyBox utilities; presents a step-by-step walkthrough of porting Linux to custom boards; and introduces real-time configuration via CONFIG_RT--one of today's most exciting developments in embedded Linux. You'll find especially detailed coverage of using development tools to analyze and debug embedded systems--including the art of kernel debugging.
• Compare leading embedded Linux processors
• Understand the details of the Linux kernel initialization process
• Learn about the special role of bootloaders in embedded Linux systems, with specific emphasis on U-Boot
• Use embedded Linux file systems, including JFFS2--with detailed guidelines for building Flash-resident file system images
• Understand the Memory Technology Devices subsystem for flash (and other) memory devices
• Master gdb, KGDB, and hardware JTAG debugging
• Learn many tips and techniques for debugging within the Linux kernel
• Maximize your productivity in cross-development environments
• Prepare your entire development environment, including TFTP, DHCP, and NFS target servers
• Configure, build, and initialize BusyBox to support your unique requirements
Embedded Linux Primer: A Practical, Real-World Approach — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Embedded Linux Primer: A Practical, Real-World Approach», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
One of the most significant design goals for the ext3 file system was that it be both backward and forward compatible with the ext2 file system. It is possible to convert an ext2 file system to ext3 file system and back again without reformatting or rewriting all the data on the disk. Let's see how this is done. [73] Converting a file system in this manner should be considered a development activity only.
Listing 9-6 details the procedure.
Listing 9-6. Converting ext2 File System to ext3 File System
# mount /dev/sdb1 /mnt/flash<<< Mount the ext2 file system
# tune2fs -j /dev/sdb1<<< Create the journal
tune2fs 1.37 (21-Mar-2005)
Creating journal inode: done
This filesystem will be automatically checked every 23 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
#
Notice that we first mounted the file system on /mnt/flash for illustrative purposes only. Normally, we would execute this command on an unmounted ext2 partition. The design behavior for tune2fs when the file system is mounted is to create the journal file called .journal, a hidden file. A file in Linux preceded with the period (.) is considered a hidden file; most Linux command line file utilities silently ignore files of this type. From Listing 9-7, we can see that the ls command was invoked with the -a flag, which tells the ls utility to list all files.
Listing 9-7. ext3 Journal File
$ ls -al /mnt/flash
total 1063
drwxr-xr-x 15 root root 1024 Aug 25 19:25 .
drwxrwxrwx 5 root root 4096 Jul 18 19:49 ..
drwxr-xr-x 2 root root 1024 Aug 14 11:27 bin
drwxr-xr-x 2 root root 1024 Aug 14 11:27 boot
drwxr-xr-x 2 root root 1024 Aug 14 11:27 dev
drwxr-xr-x 2 root root 1024 Aug 14 11:27 etc
drwxr-xr-x 2 root root 1024 Aug 14 11:27 home
-rw------- 1 root root 1048576 Aug 25 19:25 .journal
drwxr-xr-x 2 root root 1024 Aug 14 11:27 lib
drwx------ 2 root root 12288 Aug 14 11:27 lost+found
drwxr-xr-x 2 root root 1024 Aug 14 11:27 proc
drwxr-xr-x 2 root root 1024 Aug 14 11:27 root
drwxr-xr-x 2 root root 1024 Aug 14 11:27 sbin
drwxr-xr-x 2 root root 1024 Aug 14 11:27 tmp
drwxr-xr-x 2 root root 1024 Aug 14 11:27 usr
drwxr-xr-x 2 root root 1024 Aug 14 11:27 var
Now that we have created the journal file on our Flash module, it is effectively formatted as an ext3 file system. The next time the system is rebooted or the e2fsck utility is run on the partition containing the newly created ext3 file system, the journal file is automatically made invisible. Its metadata is stored in a reserved inode set aside for this purpose. As long as you can see the .journal file, it is dangerous to modify or delete this file.
It is possible and sometimes advantageous to create the journal file on a different device. For example, if you have more than one physical device on your system, you can place your ext3 journaling file system on the first drive and have the journal file on the second drive. This method works regardless of whether your physical storage is based on Flash or rotational media. To create the journaling file system from an existing ext2 file system with the journal file in a separate partition, invoke tune2fs in the following manner:
# tune2fs -J device=/dev/sda1 -j /dev/sdb1
For this to work, you must have already formatted the device where the journal is to reside with a journal fileit must be an ext3 file system.
9.4. ReiserFS
The ReiserFS file system has enjoyed popularity among some desktop distributions such as SuSE and Gentoo. As of this writing, Reiser4 is the current incarnation of this journaling file system. Like the ext3 file system, ReiserFS guarantees that either a given file system operation completes in its entirety or none of it completes. Unlike ext3, Reiser4 has introduced an API for system programmers to guarantee the atomicity of a file system transaction. Consider the following example:
A database program is busy updating records in the database. Several writes are issued to the file system. Power is lost after the first write but before the last one has completed. A journaling file system guarantees that the metadata changes have been stored to the journal file so that when power is again applied to the system, the kernel can at least establish a consistent state of the file system. That is, if file A was reported has having 16KB before the power failure, it will be reported as having 16KB afterward, and the directory entry representing this file (actually, the inode) properly records the size of the file. This does not mean, however, that the file data was properly written to the file; it indicates only that there are no errors on the file system. Indeed, it is likely that data was lost by the database program in the previous scenario, and it would be up to the database logic to recover the lost data if recovery is to occur at all.
Reiser4 implements high-performance "atomic" file system operations designed to protect both the state of the file system (its consistency) and the data involved in a file system operation. Reiser4 provides a user-level API to enable programs such as database managers to issue a file system write command that is guaranteed to either succeed in its entirety or fail in a similar manner, thus guaranteeing not only that file system consistency is maintained, but that no partial data or garbage data remains in files after system crash.
For more details and the actual software for ReiserFS, visit the home page referenced in Section 9.11.1 at the end of this chapter.
9.5. JFFS2
Flash memory has been used extensively in embedded products. Because of the nature of Flash memory technology, it is inherently less efficient and more prone to data corruption caused by power loss from much larger write times. The inefficiency stems from the block size. Block sizes of Flash memory devices are often measured in the tens or hundreds of kilobytes. Flash memory can be erased only a block at a time, although writes can usually be executed 1 byte or word at a time. To update a single file, an entire block must be erased and rewritten.
It is well known that the distribution of file sizes on any given Linux machine (or other OS) contains many more smaller files than larger files. The histogram in Figure 9-2, generated with gnuplot, illustrates the distribution of file sizes on a typical Linux development system.
Figure 9-2. File sizes in bytes
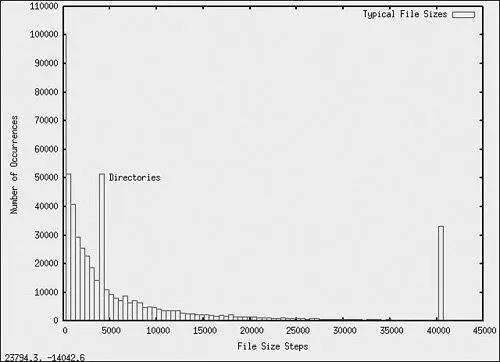
From Figure 9-2, we can see that the bulk of the file sizes are well below approximately 10KB. The spike at 4096 represents directories. Directory entries (also files themselves) are exactly 4096 bytes in length, and there are many of them. The spike above 40,000 bytes is an artifact of the measurement. It is a count of the number of files greater than approximately 40KB, the end of the measurement quantum. It is interesting to note that the vast majority of files are very small.
Small file sizes present a unique challenge to the Flash file system designer. Because Flash memory must be erased one entire block at a time, and the size of a Flash block is often many multiples of the smaller file sizes, Flash is subject to time-consuming block rewriting. For example, assume that a 128KB block of Flash is being used to hold a couple dozen files of 4096 bytes or less. Now assume that one of those files needs to be modified. This causes the Flash file system to invalidate the entire 128KB block and rewrite every file in the block to a newly erased block. This can be a time-consuming process.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Embedded Linux Primer: A Practical, Real-World Approach»
Представляем Вашему вниманию похожие книги на «Embedded Linux Primer: A Practical, Real-World Approach» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Embedded Linux Primer: A Practical, Real-World Approach» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.