Qing Li - Real-Time Concepts for Embedded Systems
Здесь есть возможность читать онлайн «Qing Li - Real-Time Concepts for Embedded Systems» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: San Francisco, Год выпуска: 2003, ISBN: 2003, Издательство: CMP books, Жанр: ОС и Сети, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Real-Time Concepts for Embedded Systems
- Автор:
- Издательство:CMP books
- Жанр:
- Год:2003
- Город:San Francisco
- ISBN:1-57820-124-1
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Real-Time Concepts for Embedded Systems: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Real-Time Concepts for Embedded Systems»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Delve into the details of real-time programming so you can develop a working knowledge of the common design patterns and program structures of real-time operating systems (RTOS). The objects and services that are a part of most RTOS kernels are described and real-time system design is explored in detail. You learn how to decompose an application into units and how to combine these units with other objects and services to create standard building blocks. A rich set of ready-to-use, embedded design “building blocks” is also supplied to accelerate your development efforts and increase your productivity.
Experienced developers new to embedded systems and engineering or computer science students will both appreciate the careful balance between theory, illustrations, and practical discussions. Hard-won insights and experiences shed new light on application development, common design problems, and solutions in the embedded space. Technical managers active in software design reviews of real-time embedded systems will find this a valuable reference to the design and implementation phases.
Qing Li is a senior architect at Wind River Systems, Inc., and the lead architect of the company’s embedded IPv6 products. Qing holds four patents pending in the embedded kernel and networking protocol design areas. His 12+ years in engineering include expertise as a principal engineer designing and developing protocol stacks and embedded applications for the telecommunications and networks arena. Qing was one of a four-member Silicon Valley startup that designed and developed proprietary algorithms and applications for embedded biometric devices in the security industry.
Caroline Yao has more than 15 years of high tech experience ranging from development, project and product management, product marketing, business development, and strategic alliances. She is co-inventor of a pending patent and recently served as the director of partner solutions for Wind River Systems, Inc. About the Authors
Real-Time Concepts for Embedded Systems — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Real-Time Concepts for Embedded Systems», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Figure 2.3 illustrates these two concepts in a simplified view and serves as an example for the following discussions.
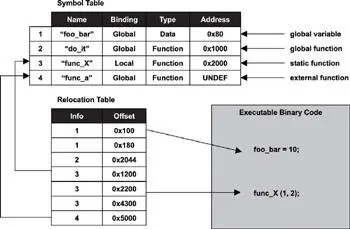
Figure 2.3: Relationship between the symbol table and the relocation table.
For an executable image, all external symbols must be resolved so that each symbol has an absolute memory address because an executable image is ready for execution. The exception to this rule is that those symbols defined in shared libraries may still contain relative addresses, which are resolved at runtime (dynamic linking).
A relocatable object file may contain unresolved external symbols. Similar to a library, a linker-reproduced relocatable object file is a concatenation of multiple object files with one main difference-the file is partially resolved and is used for further linking with other object files to create an executable image or a shared object file. A shared object file has dual purposes. It can be used to link with other shared object files or relocatable object modules, or it can be used as an executable image with dynamic linking.
2.3 Executable and Linking Format
Typically an object file contains
· general information about the object file, such as file size, binary code and data size, and source file name from which it was created,
· machine-architecture-specific binary instructions and data
· symbol table and the symbol relocation table, and
· debug information, which the debugger uses.
The manner in which this information is organized in the object file is the object file format. The idea behind a standard object file format is to allow development tools which might be produced by different vendors-such as a compiler, assembler, linker, and debugger that conform to the well-defined standard-to interoperate with each other.
This interoperability means a developer can choose a compiler from vendor A to produce object code used to form a final executable image by a linker from vendor B. This concept gives the end developer great flexibility in choice for development tools because the developer can select a tool based on its functional strength rather than its vendor.
Two common object file formats are the common object file format (COFF) and the executable and linking format (ELF). These file formats are incompatible with each other; therefore, be sure to select the tools, including the debugger, that recognize the format chosen for development.
We focus our discussion on ELF because it supersedes COFF. Understanding the object file format allows the embedded developer to map an executable image into the target embedded system for static storage, as well as for runtime loading and execution. To do so, we need to discuss the specifics of ELF, as well as how it relates to the linker.
Using the ELF object file format, the compiler organizes the compiled program into various system-defined, as well as user-defined, content groupings called sections . The program's binary instructions, binary data, symbol table, relocation table, and debug information are organized and contained in various sections. Each section has a type. Content is placed into a section if the section type matches the type of the content being stored.
A section also contains important information such as the load address and the run address. The concept of load address versus run address is important because the run address and the load address can be different in embedded systems. This knowledge can also be helpful in understanding embedded system loader and link loader concepts introduced in Chapter 3.
Chapter 1 discusses the idea that embedded systems typically have some form of ROM for non-volatile storage and that the software for an embedded system can be stored in ROM. Modifiable data must reside in RAM. Programs that require fast execution speed also execute out of RAM. Commonly therefore, a small program in ROM, called a loader, copies the initialized variables into RAM, transfers the program code into RAM, and begins program execution out of RAM. This physical ROM storage address is referred to as the section's load address. The section's run address refers to the location where the section is at the time of execution. For example, if a section is copied into RAM for execution, the section's run address refers to an address in RAM, which is the destination address of the loader copy operation. The linker uses the program's run address for symbol resolutions.
The ELF file format has two different interpretations, as shown in Figure 2.4. The linker interprets the file as a linkable module described by the section header table, while the loader interprets the file as an executable module described by the program header table.
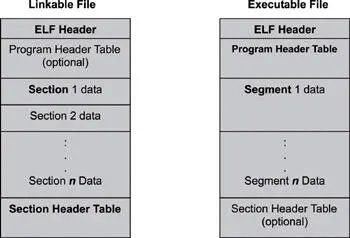
Figure 2.4: Executable and linking format.
Listing 2.1 shows both the section header and the program header, as represented in C programming structures. We describe the relevant fields during the course of this discussion.
Listing 2.1: Section header and program header.
typedef struct {
Elf32_Word sh_name;
Elf32_Word sh_type;
Elf32_Word sh_flags;
Elf32_Addr sh_addr;
Elf32_Off sh_offset;
Elf32_Word sh_size;
Elf32_Word sh_link;
Elf32_Word sh_info;
Elf32_Word sh_addralign;
Elf32_Word sh_entsize;
} Elf32_Shdr;
typedef struct {
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
Elf32_Word p_filesz;
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
} Elf32_Phdr;
A section header table is an array of section header structures describing the sections of an object file. A program header table is an array of program header structures describing a loadable segment of an image that allows the loader to prepare the image for execution. Program headers are applied only to executable images and shared object files.
One of the fields in the section header structure is sh_type, which specifies the type of a section. Table 2.1 lists some section types .
Table 2.1: Section types.
| NULL | Inactive header without a section. |
| PROGBITS | Code or initialized data. |
| SYMTAB | Symbol table for static linking. |
| STRTAB | String table. |
| RELA/REL | Relocation entries. |
| HASH | Run-time symbol hash table. |
| DYNAMIC | Information used for dynamic linking. |
| NOBITS | Uninitialized data. |
| DYNSYM | Symbol table for dynamic linking. |
The sh_flags field in the section header specifies the attribute of a section. Table 2.2 lists some of these attributes.
Table 2.2: Section attributes.
| WRITE | Section contains writeable data. |
| ALLOC | Section contains allocated data. |
| EXECINSTR | Section contains executable instructions. |
Some common system-created default sections with predefined names for the PROGBITS are.text,.sdata,.data,.sbss, and.bss. Program code and constant data are contained in the.text section. This section is read-only because code and constant data are not expected to change during the lifetime of the program execution. The.sbss and.bss sections contain uninitialized data. The.sbss section stores small data , which is the data such as variables with sizes that fit into a specific size. This size limit is architecture-dependent. The result is that the compiler and the assembler can generate smaller and more efficient code to access these data items. The.sdata and.data sections contain initialized data items. The small data concept described for.sbss applies to.sdata. A.text section with executable code has the EXECINSTR attribute. The.sdata and.data sections have the WRITE attribute. The.sbss and.bss sections have both the WRITE and the ALLOC attributes.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Real-Time Concepts for Embedded Systems»
Представляем Вашему вниманию похожие книги на «Real-Time Concepts for Embedded Systems» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Real-Time Concepts for Embedded Systems» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.