Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
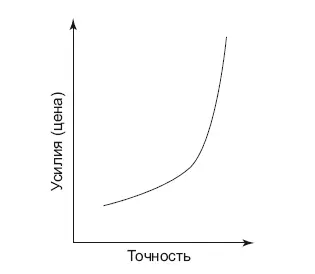
Рис. 9.2.Зависимость стоимости решения от его точности
Это можно учитывать, когда создается первая версия продукта. Не нужно гнаться сразу за сверхточностью, лучше выбрать приемлемую точность. Второй способ – сделать, что получится, довести решение до рабочей системы, а уже затем решать, нужно бизнесу улучшать метрики или нет. Возможно, стоит потратить усилия на другой продукт, вместо того чтобы бесконечно полировать один – а клиенты этого не заметят и не оценят по достоинству.
Простота решения
Уильям Оккам сформулировал принцип: «Что может быть сделано на основе меньшего числа [предположений], не следует делать, исходя из большего». Этот принцип экономности под названием «бритва Оккама» позволяет, например, выстроить цепь гипотез в порядке возрастания сложности, и именно этот порядок в большинстве случаев окажется удачным. Его также можно использовать при выборе ML-модели. Всегда лучше идти от простого к сложному, от линейных моделей к нелинейным, таким, как, например, нейронные сети.
Почему чем проще, тем лучше? Кроме точности любой ML-модели, есть стоимость ее содержания. Она складывается из вычислительных ресурсов – сложные модели требуют их больше. Специалисты для обслуживания сложных моделей требуются сильные, и у них выше заработная плата. И главное – внесение изменений в сложную систему будет сложным, а это приводит к потере времени и денег. Мы в Retail Rocket при проверке гипотезы всегда следовали простому правилу: если есть две модели, которые по эффективности почти равнозначны, то выбираем всегда модель проще.
В некоторых алгоритмах ML есть опция получения значимости фич (features importances). Этот принцип можно использовать и при отсечении фич. Я уже писал про трактовку коэффициентов линейных моделей – если они стандартизованы, то модуль (игнорируем знак) коэффициента говорит о силе вклада переменной в модель. Для нелинейной оценки можно воспользоваться алгоритмом Random Forests, чтобы получить значимость фич. Эти данные тоже можно использовать для отсечения фич. Чем меньше фич будет использовано в модели, тем проще ее будет поддерживать. От большего их числа модель становится только сложнее. И если отсечь наименее значимые фичи, не сильно потеряв при этом в точности, то выводить в рабочую систему такую модель будет проще. Дело в том, что каждая фича требует внимания, отдельных строк кода. За этим нужно следить, и если получится прийти от 20 к 10 фичам, то поддержка будет дешевле, а источников ошибок будет меньше.
Простота системы и отличает рабочие варианты ML-моделей от конкурсов Kaggle. При этом, чтобы добиться простоты, возможно, понадобится приложить больше усилий, чем при разработке очень сложной модели на Kaggle. Стремление к сложности я часто наблюдаю у новичков, они пытаются строить космический корабль там, где можно обойтись самокатом.
Трудоемкость проверки результата
В восьмом уроке от рекомендательной системы Quora [68] говорится о том, как важно уметь отвечать на вопрос, почему рекомендательная система дала ту или иную рекомендацию. В Retail Rocket мы также сталкиваемся с такими вопросами. Однажды в качестве альтернативного товара к туалетной бумаге выступила наждачная. Кстати, алгоритм предложил ее из-за реального поведения клиентов – но, конечно, рекомендация выглядела как пранк, и нам было не смешно, ведь с каждым таким случаем приходится разбираться в ручном режиме. В какой-то момент мы написали скрипты и инструкции нашей технической поддержке, чтобы подобные казусы можно было оперативно решать или просто объяснять клиенту без привлечения аналитиков.
Почему так происходит? Когда продукт, в основе которого лежат данные, работает на внешний мир, могут возникать ситуации, неожиданные для пользователей. И если система проста и в ней заложены средства поиска и отладки неисправностей, разрулить их можно быстро.
Mechanical Turk / Yandex Toloka
Даже в проектах с использованием ML-моделей все средства хороши. Совсем недавно писали про компанию ScaleFactor, которая, как утверждалось, использовала искусственный интеллект, чтобы оказывать бухгалтерские услуги [69]. В компанию было вложено порядка 100 миллионов долларов. На деле оказалось, что всю работу делали традиционным способом обычные бухгалтеры.
Впервые о ручном труде в ML я услышал на видео с конференции STRATA, когда сотрудники LinkedIn рассказывали о проекте Skills. Для создания датасета они с помощью сервиса Amazon Mechanical Turk использовали труд тысяч людей, чтобы разметить данные для проекта. Сама модель у них была простая – логистическая регрессия, но датасет для нее нужен был качественный. Конечно, можно было использовать метод анализа текстов, но дешевле и с гарантированным качеством можно получить результат через такие сервисы.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.