Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
Здесь есть возможность читать онлайн «Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2021, ISBN: 2021, Издательство: Издательство Питер, Жанр: Базы данных, popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
![Роман Зыков Роман с Data Science. Как монетизировать большие данные [litres] обложка книги](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova.webp)
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Издательство:Издательство Питер
- Жанр:
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Роман с Data Science. Как монетизировать большие данные [litres]: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Роман с Data Science. Как монетизировать большие данные [litres]»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Роман с Data Science. Как монетизировать большие данные [litres]», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Выбросы также могут вносить существенную ошибку в модель. Прямая линейной регрессии пройдет по-другому, если удалить выбросы, что особенно важно, когда данных мало. Удаление выбросов – непростая задача. Самый простой способ – удалить данные, которые лежат вне какого-либо перцентиля, например 99-го. На графике (рис. 9.1) представлен пример, как выброс изменил прямую, пунктиром показана прямая линейной регрессии для данных с выбросов, сплошной – без выброса. Видно, что точка выброса «поворачивает» прямую в свою сторону.
Категориальные переменные мы уже обсуждали в главе о данных. В их использовании есть нюансы. Обычно нет никаких проблем с бинарными переменными (да/нет, 0/1), нужно лишь свести их к значениям 0 и 1 (dummy variable), если работаете с линейными моделями. Сама операция называется label encoding. Что касается
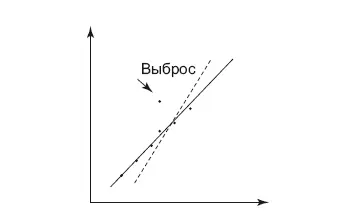
Рис. 9.1.Выброс меняет поведение
деревьев решений, нужно смотреть документацию конкретного метода – в каком виде представить категориальные переменные. Когда идет работа с категориальной переменной, у которой три и более значений, в большинстве случаев требуется ее разбить на несколько бинарных. Например, если есть переменная c тремя значениями: Да/Нет/Не знаю, то ее нужно разбить на три переменные (по числу значений). Можно назвать эти переменные по названию значений: Да, Нет, Не знаю. Каждая переменная будет принимать значение 0 или 1. Например, если у исходной переменной было значение «Да», то эти переменные примут следующие значения: Да = 1, Нет = 0, Не знаю = 0. Эта операция кодирования называется one-hot encoding. Выполнять ее необходимо потому что, в отличие от непрерывных числовых переменных, взаимоотношения между значениями переменных (больше или меньше) не определены, а значит, операция сравнения значений невозможна. Некоторые методы поддерживают категориальные переменные со множеством значений, например, catBoost от Яндекса. Есть еще один вариант кодирования динамичных категориальных значений, например слов текста, – метод называется hashing trick. Он нужен, чтобы не заводить огромное количество переменных, когда число значений очень велико.
В работе с данными часто встречается ситуация, когда значения некоторых переменных пустые (missing data). В самих данных в зависимости от системы можно увидеть либо пустоту, либо одно из значений: None или Null. Для категориальных переменных эта проблема решается легко – достаточно просто завести новое значение и назвать его «unknown». Для непрерывных числовых переменных это сделать сложнее – нужно понимать, не кроется ли за пустыми значениями какая-то закономерность. Если выяснится, что закономерности нет, можно или удалить данные, или заменить их на среднее значение. Подробно про работу с потерянными данными можно прочитать в книге Эндрю Гельмана [66].
В задачах классификации, когда мы обучаем модель различать два класса, часто возникает проблема несбалансированности этих классов. Это бывает в медицине при тестировании населения и диагностике редких болезней – если в датасете есть данные десяти тысяч людей и из них только десять заболевших, то алгоритму очень сложно обучиться. Другой пример – датасет показа рекламных баннеров в интернете: показов много, а кликов мало. Проблема в том, что модели проще не замечать данные малого класса, а просто предсказывать больший класс, ошибка точности при этом будет приближаться к 100 процентам. Что с этим делать? В курсе по машинному обучению от Google [67] советуют с помощью сэмплирования (downsampling) уменьшить самый большой класс, но назначить этим строкам пропорциональный вес. Это даст быструю сходимость, так как малый класс будет больше влиять на обучение, а веса дадут возможность сразу использовать вероятность, которую мы получим на выходе, для классификации.
Точность и стоимость ML-решения
Чем точнее изготовление какой-либо детали на производстве, тем оно дороже. То же самое можно сказать и про машинное обучение. Когда создается первая версия решения, получаем одну степень точности (рис. 9.2). Потом тратится очень много усилий и времени на улучшение этого результата – к сожалению, рост результата не пропорционален усилиям, которые были на него затрачены (правило Парето никто не отменял!). Мой опыт создания рекомендательной системы говорит, что затраты на каждый процент улучшения растут по экспоненциальному закону. То же самое можно увидеть и в соревнованиях Kaggle.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]»
Представляем Вашему вниманию похожие книги на «Роман с Data Science. Как монетизировать большие данные [litres]» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Роман с Data Science. Как монетизировать большие данные [litres]» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.