Джон Келлехер - Наука о данных. Базовый курс
Здесь есть возможность читать онлайн «Джон Келлехер - Наука о данных. Базовый курс» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина Паблишер, Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Наука о данных. Базовый курс
- Автор:
- Издательство:Альпина Паблишер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Наука о данных. Базовый курс: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Наука о данных. Базовый курс»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Наука о данных. Базовый курс», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
• сбор данных — 19 %;
• очистка и организация данных — 60 %;
• построение обучающих моделей — 3 %;
• анализ данных для выявления закономерностей — 9 %;
• уточнение алгоритмов — 4 %;
• другие задачи — 5 %.
Показатель 79 % для подготовки суммирует время, затраченное на сбор, очистку и организацию данных. Этот показатель — около 80 % времени проекта — присутствует в разных отраслевых опросах уже в течение ряда лет. Такой вывод может удивить, поскольку принято считать, что специалист по данным тратит свое время на создание сложных моделей, помогающих получить новые знания. Но простая истина состоит в том, что, как бы ни был хорош ваш анализ, он не найдет полезных закономерностей в неправильных данных.
Источники
‹1›. Han, Jiawei, Micheline Kamber, and Jian Pei. 2011. Data Mining: Concepts and Techniques, Third Edition. Haryana, India; Burlington, MA: Morgan Kaufmann.
‹2›. Hall, Mark, Ian Witten, and Eibe Frank. 2011. Data Mining: Practical Machine Learning Tools and Techniques.
‹3›. Korzybski, Alfred. 1996. «On Structure.» In Science and Sanity: An Introduction Ot NonAristotelian Systems and General Semantics, edited by Charlotte Schuchardt-Read, CDROM First Edition. European Society for General Semantics. http://esgs.free.fr/uk/art/sands.htm.
‹4›. Kitchin, Rob. 2014. The Data Revolution: Big Data, Open Data, Data Infrastructures and Their Consequences. Sage.
‹5›. Pomerantz, Jeffrey. 2015. Metadata. The MIT Press Essential Knowledge Series. https://mitpress.mit.edu/books/metadata-0.
‹6›. Mayer, Jonathan, and Patrick Mutchler. 2014. «MetaPhone: The Sensitivity of Telephone Metadata.» Web Policy. http://webpolicy.org/2014/03/12/metaphone-the-sensitivity-oftelephone-metadata/.
‹7›. Mayer, Jonathan, and Patrick Mutchler. 2014. «MetaPhone: The Sensitivity of Telephone Metadata.» Web Policy. http://webpolicy.org/2014/03/12/metaphone-the-sensitivity-oftelephone-metadata/.
‹8›. Элиот Т. С. Полые люди. — СПб.: ООО «Издательский Дом „Кристалл“», 2000. (Б-ка мировой лит., Малая серия).
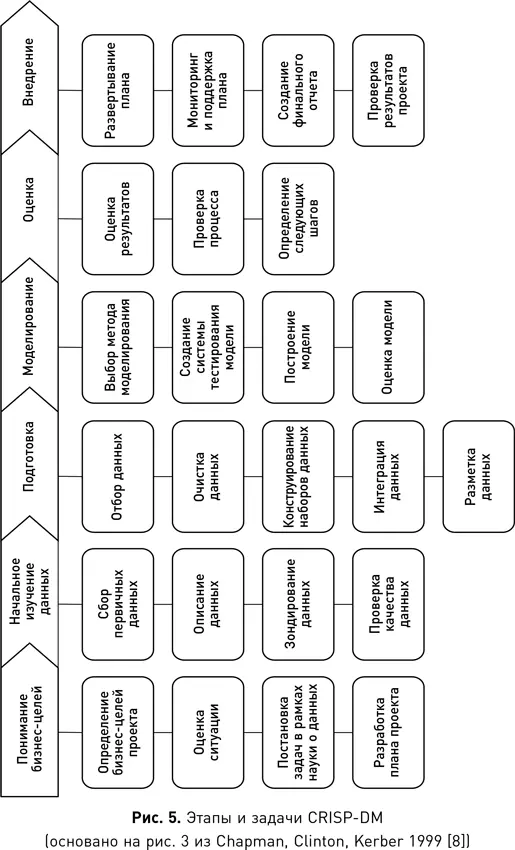
‹9›. Chapman, Pete, Julian Clinton, Randy Kerber, Thomas Khabaza, Thomas Reinartz, Colin Shearer, and Rudiger Wirth. 1999. «CRISP-DM 1.0: Step-by-Step Data Mining Guide.» ftp://ftp.software.ibm.com/software/analytics/spss/support/Modeler/Documentation/14/UserManual/CRISP-DM.pdf.
‹10›. Steinberg, Dan. 2013. «How Much Time Needs to Be Spent Preparing Data for Analysis?» http://info.salford-systems.com/blog/bid/299181/How-Much-Time-Needs-to-be-SpentPreparing-Data-for-Analysis.
‹11›. CrowdFlower. 2016. «Отчет о науке данных за 2016 год». http://visit.crowdflower.com/rs/416-ZBE142/images/CrowdFlower_DataScienceReport_2016.pdf.
Глава 3. Экосистема науки о данных
Набор технологий, используемых для обработки данных, варьируется в зависимости от организации. Чем больше организация и/или объем обрабатываемых данных, тем сложнее технологическая экосистема науки о данных. Обычно эта экосистема содержит инструменты и узлы от нескольких поставщиков программного обеспечения, которые обрабатывают данные в разных форматах. Существует ряд подходов, которые организация может использовать для разработки собственной экосистемы науки о данных. На одном конце этого ряда организация принимает решение инвестировать в готовую систему интегрированных инструментов. На другом — самостоятельно создавать экосистему путем интеграции инструментов и языков с открытым исходным кодом. Между этими двумя крайностями есть несколько поставщиков программного обеспечения, которые предоставляют решения, являющие собой смесь коммерческих продуктов и продуктов с открытым исходным кодом. Однако, хотя конкретный набор инструментов в каждой организации будет свой, наука о данных предусматривает общие компоненты для большинства архитектур.
Рис. 6 дает обзор типичной архитектуры данных. Эта архитектура предназначена не только для больших данных, но и для данных любого размера. Диаграмма состоит из трех основных частей: уровня источников данных, на котором генерируются все данные в организации; уровня хранения данных, на котором данные хранятся и обрабатываются, и уровня приложений, на котором данные передаются потребителям этих данных и информации, а также различным приложениям.
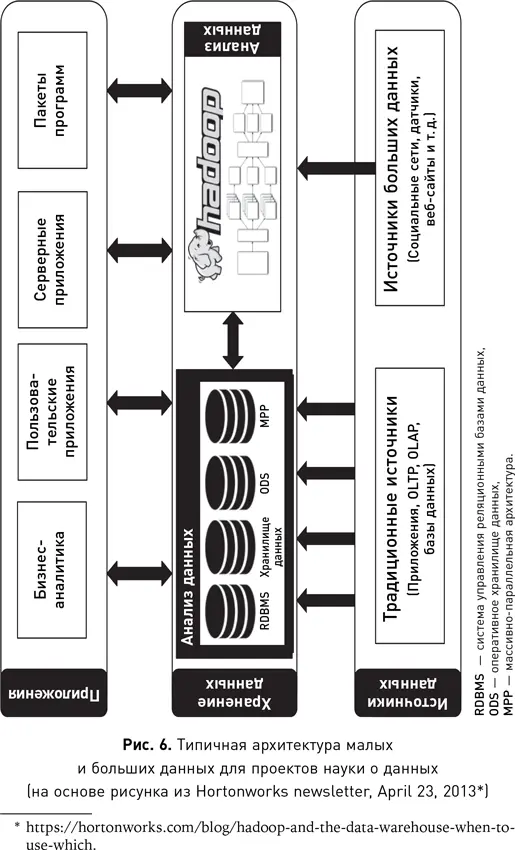
У каждой организации есть приложения, которые генерируют и собирают данные о клиентах, транзакциях и обо всем, что связано с работой организации (операционные данные). Это источники и приложения следующих типов: управление клиентами, заказы, производство, доставка, выставление счетов, банкинг, финансы, управление взаимодействием с клиентами (CRM), кол-центр, ERP и т. д. Приложения такого типа обычно называют системами обработки транзакций в реальном времени, или OLTP. Во многих проектах науки о данных именно эти приложения используются как источник входного набора данных для алгоритмов машинного обучения. Со временем объем данных, собираемых различными приложениями по всей организации, становится все больше и начинает включать данные, которые ранее были проигнорированы, недоступны или не были собраны по иным причинам. Эти новые источники, как правило, относятся уже к большим данным, поскольку их объем значительно выше, чем объем данных основных операционных приложений организации. Распространенные источники — это сетевой трафик, регистрационные данные различных приложений, данные датчиков, веб-журналов, социальных сетей, веб-сайтов и т. д. В традиционных источниках данные обычно хранятся в базе. Новые источники больших данных часто не предназначены для длительного их хранения, как в случае с потоковыми данными, поэтому форматы и структуры хранения будут варьироваться от приложения к приложению.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Наука о данных. Базовый курс»
Представляем Вашему вниманию похожие книги на «Наука о данных. Базовый курс» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Наука о данных. Базовый курс» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.