Джон Келлехер - Наука о данных. Базовый курс
Здесь есть возможность читать онлайн «Джон Келлехер - Наука о данных. Базовый курс» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина Паблишер, Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Наука о данных. Базовый курс
- Автор:
- Издательство:Альпина Паблишер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Наука о данных. Базовый курс: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Наука о данных. Базовый курс»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Наука о данных. Базовый курс», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Процесс CRISP-DM
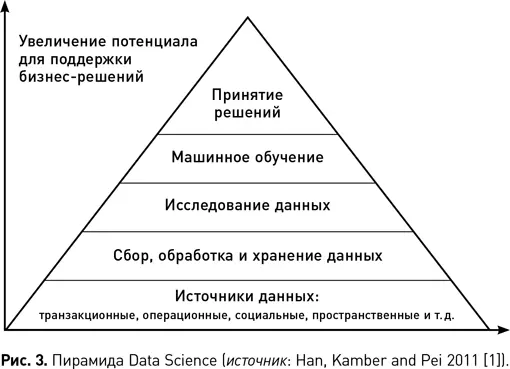
В научной среде регулярно выдвигаются новые идеи о том, каким способом лучше всего взбираться на вершину пирамиды науки о данных. Наиболее часто используется межотраслевой стандартный процесс исследования данных CRISP-DM. Этот процесс в течение целого ряда лет занимает первые места всевозможных отраслевых опросов. Одно из преимуществ CRISP-DM и причина, по которой он так широко используется, заключается в том, что процесс спроектирован как независимый от программного обеспечения, поставщика или метода анализа данных.
CRISP-DM разрабатывался консорциумом организаций, в который входили ведущие поставщики данных, конечные пользователи, консалтинговые компании и исследователи. Первоначальный проект CRISP-DM был частично спонсирован Европейской комиссией в рамках программы ESPRIT и представлен на семинаре в 1999 г. С тех пор было предпринято несколько попыток обновить процесс, но оригинальная версия все еще остается наиболее востребованной. В течение многих лет существовал отдельный сайт CRISP-DM, но сейчас он закрыт, и в большинстве случаев вы будете перенаправлены на сайт SPSS компании IBM, которая участвовала в проекте с самого начала. Консорциум участников опубликовал детальную (76 страниц), но вполне понятную пошаговую инструкцию для процесса, которая находится в свободном доступе в интернете {9} . Далее мы кратко изложим основную структуру и задачи процесса.
Жизненный цикл CRISP-DM состоит из шести этапов — понимание бизнес-целей, начальное изучение данных, подготовка данных, моделирование, оценка и внедрение, — показанных на рис. 4. Данные являются центром всех операций, как это видно из диаграммы CRISP-DM. Стрелки между этапами указывают типичное направление процесса. Сам процесс является частично структурированным, т. е. специалист по данным не всегда проходит все шесть этапов линейно. В зависимости от результата конкретного этапа может потребоваться вернуться к одному из предыдущих, повторить текущий или перейти к следующему.
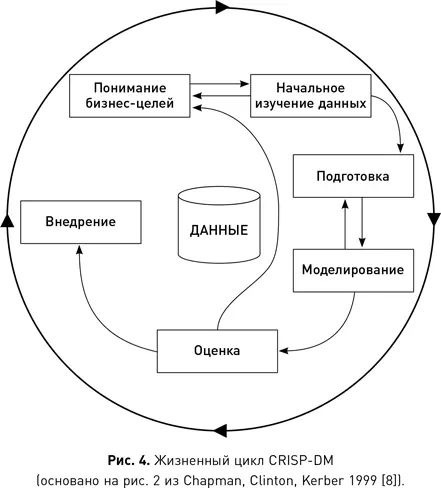
На первых двух этапах — понимания бизнес-целей и начального изучения данных — специалист пытается сформулировать цели проекта с точки зрения бизнеса и знакомится с данными, которые тот имеет в своем распоряжении. На ранних стадиях проекта придется часто переключаться между фокусировкой на бизнесе и изучением доступных данных. Это связано с тем, что специалист по данным должен идентифицировать бизнес-проблему, а затем понять, доступны ли соответствующие данные для поиска ее решения. Если они доступны, то проект может продолжаться, в противном случае специалисту придется искать альтернативную проблему. В течение этого периода специалист по данным плотно работает с коллегами из бизнес-отделов организации (продаж, маркетинга, операций), пытаясь вникнуть в их проблемы, а также с администраторами баз данных, чтобы изучить доступный материал.
Как только бизнес-проблема была четко сформулирована, а специалист убедился в том, что соответствующие данные доступны, происходит переход к очередному этапу CRISP-DM — подготовке данных. Целью этого этапа является создание набора данных, который можно использовать для анализа. Обычно это подразумевает интеграцию источников из нескольких баз данных. Когда в организации существует хранилище данных, эта интеграция значительно упрощается. После создания набора данных необходимо проверить и исправить их качество. Типичные проблемы качества включают выбросы и пропущенные значения. Проверка качества крайне важна, поскольку ошибки в данных могут серьезно повлиять на производительность алгоритмов анализа.
Следующим этапом CRISP-DM является моделирование. На этой стадии используются автоматические алгоритмы для выявления полезных закономерностей в данных и создаются модели, которые кодируют эти закономерности. Алгоритмы для выявления закономерностей также называются алгоритмами машинного обучения. На этапе моделирования специалист по данным обычно использует несколько алгоритмов машинного обучения для подготовки разных моделей в каждом наборе данных. Необходимость в нескольких моделях вызвана тем, что разные типы алгоритмов машинного обучения ищут разные типы закономерностей в данных, и на этапе моделирования специалист, как правило, не знает, какие именно закономерности нужно искать. Таким образом, имеет смысл поэкспериментировать с различными алгоритмами и посмотреть, какой из них работает лучше всего.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Наука о данных. Базовый курс»
Представляем Вашему вниманию похожие книги на «Наука о данных. Базовый курс» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Наука о данных. Базовый курс» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.