Джон Келлехер - Наука о данных. Базовый курс
Здесь есть возможность читать онлайн «Джон Келлехер - Наука о данных. Базовый курс» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина Паблишер, Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Наука о данных. Базовый курс
- Автор:
- Издательство:Альпина Паблишер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Наука о данных. Базовый курс: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Наука о данных. Базовый курс»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Наука о данных. Базовый курс», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Одним из наиболее распространенных типов выхлопных данных являются метаданные , т. е. данные, описывающие другие данные. Когда Эдвард Сноуден опубликовал документы АНБ, касающиеся программы тотальной слежки PRISM, он также сообщил, что агентство собирало большое количество метаданных о телефонных звонках людей. Это значит, что АНБ фактически не записывало их содержание (т. е. не вело прослушивания телефонных разговоров), но собирало данные о звонках, например когда был сделан звонок, кому, как долго длился и т. д. {5} . Этот тип сбора данных может показаться не столь зловещим, но исследовательский проект MetaPhone, проведенный в Стэнфорде, обнаружил, что метаданные телефонного звонка могут раскрыть большой объем личной информации {6} . Тот факт, что многие организации работают в узких сферах, позволяет относительно легко выявлять информацию о человеке на основе его телефонных звонков. Например, некоторые из участников исследования MetaPhone звонили «Анонимным алкоголикам», адвокатам по бракоразводным процессам и в медицинские клиники, специализирующиеся на венерических болезнях. О многом могут говорить и закономерности звонков. Вот два примера закономерностей, выявленных в ходе исследования и раскрывающих очень деликатную информацию:
«Участник А общался с несколькими местными группами поддержки людей, страдающих неврологическими заболеваниями, специализированной аптекой, службой лечения редких состояний и горячей линией лекарственного средства, применяемого исключительно для лечения рассеянного склероза… В течение трех недель участник B связывался с магазином товаров для ремонта, слесарем, продавцом оборудования для гидропоники и торговцем марихуаной {7} ».
Традиционно наука о данных была сосредоточена на получении собранных данных. Однако, как показывает исследование MetaPhone, выхлопные данные также могут быть использованы для выявления скрытого смысла. В последние годы выхлопные данные становятся все более и более полезными, особенно в области взаимодействия с клиентами, где связывание между собой различных наборов выхлопных данных может создать более широкий клиентский профиль, тем самым позволяя бизнесу точнее ориентировать свои услуги и маркетинг. Сегодня одним из факторов, стимулирующих развитие науки о данных, является признание современным бизнесом ценности выхлопных данных и их потенциала.
Данные накапливаются, мудрость — нет!
Цель науки о данных — использовать их, чтобы получить прозрение и понимание. Библия призывает нас к пониманию через мудрость: «Главное — мудрость: приобретай мудрость, и всем имением твоим приобретай разум» (Притч. 4:7). Этот совет разумен, но он ставит вопрос о том, как именно нужно искать мудрости. Следующие строки из стихотворения Т. С. Элиота «Камень» описывают иерархию мудрости, знаний и информации:
Где мудрость, которую мы потеряли в знанье?
Где знанье, которое мы потеряли в сведеньях? {8}
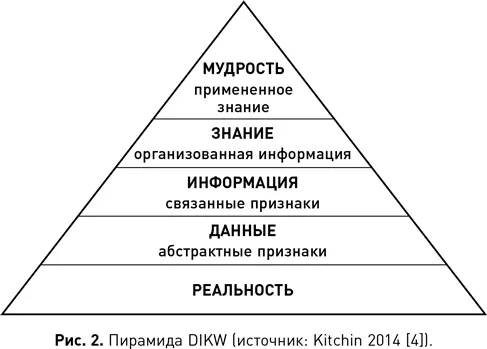
Иерархия Элиота отражает стандартную модель структурных отношений между мудростью, знаниями, информацией и данными, известную как пирамида DIKW (см. рис. 2). В пирамиде DIKW данные предшествуют информации, которая предшествует знаниям, которые, в свою очередь, предшествуют мудрости. Хотя порядок уровней в иерархии, как правило, не вызывает споров, различия между этими уровнями и процессы, необходимые для перехода от одного к другому, часто оспариваются. Но если посмотреть в широком смысле, то можно утверждать следующее:
• данные создаются с помощью абстракции или измерения мира;
• информация — это данные, которые были обработаны, структурированы или встроены в контекст таким образом, что стали значимы для людей;
• знание — это информация, которая была истолкована и понята таким образом, что появилась возможность действовать в соответствии с ней по необходимости;
• мудрость — это умение найти надлежащее применение знанию.
Последовательные операции в процессе обработки данных могут быть представлены аналогичной пирамидальной иерархией, где ширина пирамиды отображает объем данных, обрабатываемых на каждом уровне, и чем выше уровень, тем результаты действий более информативны для принятия решения. Рис. 3 иллюстрирует иерархию операций науки о данных, начиная с их сбора и генерации посредством предварительной обработки и агрегирования и заканчивая пониманием результатов, обнаружением закономерностей и созданием моделей с использованием машинного обучения для принятия решений в бизнес-контексте.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Наука о данных. Базовый курс»
Представляем Вашему вниманию похожие книги на «Наука о данных. Базовый курс» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Наука о данных. Базовый курс» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.