Cole Stryker - Smarter Data Science
Здесь есть возможность читать онлайн «Cole Stryker - Smarter Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Smarter Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Smarter Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Smarter Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Data science is emerging as a hands-on tool for not just data scientists, but business professionals as well. Managers, directors, IT leaders, and analysts must expand their use of data science capabilities for the organization to stay competitive.
helps them achieve their enterprise-grade data projects and AI goals. It serves as a guide to building a robust and comprehensive information architecture program that enables sustainable and scalable AI deployments.
When an organization manages its data effectively, its data science program becomes a fully scalable function that’s both prescriptive and repeatable. With an understanding of data science principles, practitioners are also empowered to lead their organizations in establishing and deploying viable AI. They employ the tools of machine learning, deep learning, and AI to extract greater value from data for the benefit of the enterprise.
By following a ladder framework that promotes prescriptive capabilities, organizations can make data science accessible to a range of team members, democratizing data science throughout the organization. Companies that collect, organize, and analyze data can move forward to additional data science achievements:
Improving time-to-value with infused AI models for common use cases Optimizing knowledge work and business processes Utilizing AI-based business intelligence and data visualization Establishing a data topology to support general or highly specialized needs Successfully completing AI projects in a predictable manner Coordinating the use of AI from any compute node. From inner edges to outer edges: cloud, fog, and mist computing When they climb the ladder presented in this book, businesspeople and data scientists alike will be able to improve and foster repeatable capabilities. They will have the knowledge to maximize their AI and data assets for the benefit of their organizations.
Smarter Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Smarter Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
You don't need a crystal ball to know that your organization needs data science, but you do need some means of insight to know your organization's efforts can be effective and are moving toward the goal of AI-centricity. This chapter touches on the major concepts behind each rung of the metaphorical ladder for AI, why data must be addressed as a peer discipline to AI, and why you'll need to be creative as well as a polymath—showcasing your proficiency to incorporate multiple specializations that you'll be able to read about within this book.
Readying Data for AI
The limitations can be technological, but much of the journey to AI is made up of organizational change. The adoption of AI may require the creation of a new workforce category: the new-collar worker. New-collar jobs can include roles in cybersecurity, cloud computing, digital design, and cognitive business. New-collar work for the cognitive business has been invoked to describe the radically different ways AI-empowered employees will approach their duties. This worker must progress methodically from observing the results of a previous action to justifying a new course of action to suggesting and ultimately prescribing a course of action.
When an organization targets a future state for itself, the future state simply becomes the current state once it's attained. The continual need to define another future state is a cycle that propels the organization forward. Ideally, the organization can, over time, reduce the time and expense required to move from one state to the next, and these costs will be viewed not as expenses but as derived value, and money will cease to inhibit the cycle's progression.
Worldwide, most organizations now agree that AI will help them stay competitive, but many organizations can often still struggle with less advanced forms of analytics. For organizations that experience failure or less than optimal outcomes with AI, the natural recourse seems to be to remove rigor and not increase it. From the perspective of the AI Ladder, rungs are hurried or simply skipped altogether. When an organization begins to recognize and acknowledge this paradigm, they must revisit the fundamentals of analytics in order to prepare themselves for their desired future state and the ability to benefit from AI. They don't necessarily need to start from scratch, but they need to evaluate their capabilities to determine from which rung they can begin. Many of the technological pieces they need may already be in place.
Organizations will struggle to realize value from AI without first making data simple, accessible, and available across the enterprise, but this democratization of data must be tempered by methods to ensure security and privacy because, within the organization, not all data can be considered equal.
Technology Focus Areas
Illustrated in Figure 1-1, the level of analytics sophistication accessible to the organization increases with each rung. This sophistication can lead to a thriving data management practice that benefits from machine learning and the momentum of AI.
Organizations that possess large amounts of data will, at some point, need to explore a multicloud deployment. They'll need to consider three technology-based areas as they move up the ladder.
Hybrid data management for the core of their machine learning
Governance and integration to provide security and seamless user access within a secured user profile
Data science and AI to support self-service and full-service user environments for both advanced and traditional analytics
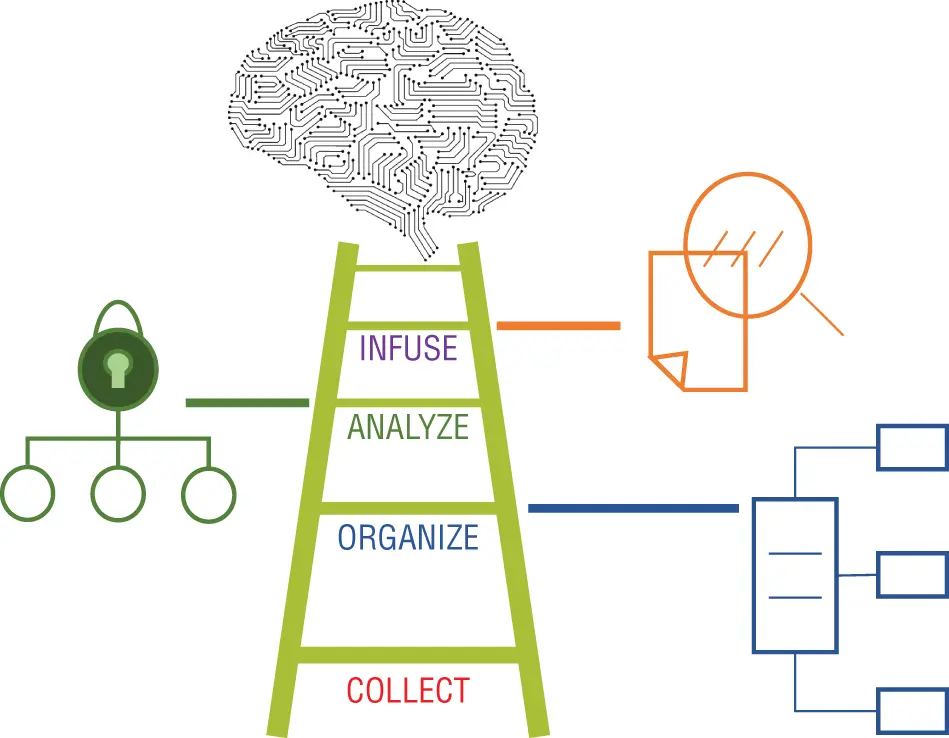
Figure 1-1:The AI Ladder to achieve a full complement of data and analytics
These foundational technologies must embrace modern cloud and microservice infrastructures to create pathways for the organization to move forward and upward with agility and speed. These technologies must be implemented at various rungs, enabling the movement of data and delivering predictive power from machine learning models in various types of deployment, from a single environment to a multicloud environment.
Taking the Ladder Rung by Rung
As shown in Figure 1-1, the rungs of the ladder are labeled Collect, Organize, Analyze, and Infuse. Each rung provides insight into elements that are required for an information architecture.
Collect , the first rung, represents a series of disciplines used to establish foundational data skills. Ideally, access to the data should be simplified and made available regardless of the form of the data and where it resides. Since the data used with advanced analytics and AI can be dynamic and fluid, not all data can be managed in a physical central location. With the ever-expanding number of data sources, virtualizing how data is collected is one of the critical activities that must be considered in an information architecture.
These are key themes included in the Collect rung:
Collecting data with a common SQL engine, the use of APIs for NoSQL access, and support for data virtualization across a broad ecosystem of data that can be referred to as a data estate
Deploying data warehouses, data lakes, and other analytical-based repositories with always-on resiliency and scalability
Scaling with real-time data ingestion and advanced analytics simultaneously
Storing or extracting all types of business data whether structured, semistructured, or unstructured
Optimizing collections with AI that may include graph databases, Python, machine learning SQL, and confidence-based queries
Tapping into open source data stores that may include technologies such as MongoDB, Cloudera, PostgreSQL, Cloudant, or Parquet
The Organize rung infers that there is a need to create a trusted data foundation. The trusted data foundation must, at a minimum, catalog what is knowable to your organization. All forms of analytics are highly dependent upon digital assets. What assets are digitized forms the basis for what an organization can reasonably know: the corpus of the business is the basis for the organizational universe of discourse—the totality of what is knowable through digitized assets.
Having data that is business-ready for analytics is foundational to the data being business-ready for AI, but simply having access to data does not infer that the data is prepared for AI use cases. Bad data can paralyze AI and misguide any process that consumes output from an AI model. To organize, organizations must develop the disciplines to integrate, cleanse, curate, secure, catalog, and govern the full lifecycle of their data.
These are key themes included in the Organize rung:
Cleansing, integrating, and cataloging all types of data, regardless of where the data originates
Automating virtual data pipelines that can support and provide for self-service analytics
Ensuring data governance and data lineage for the data, even across multiple clouds
Deploying self-service data lakes with persona-based experiences that provide for personalization
Gaining a 360-degree view by combing business-ready views from multicloud repositories of data
Streamlining data privacy, data policy, and compliance controls
The Analyze rung incorporates essential business and planning analytics capabilities that are key for achieving sustained success with AI. The Analyze rung further encapsulates the capabilities needed to build, deploy, and manage AI models within an integrated organizational technology portfolio.
These are key themes included in the Analyze rung:
Preparing data for use with AI models; building, running, and managing AI models within a unified experience
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Smarter Data Science»
Представляем Вашему вниманию похожие книги на «Smarter Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.

![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)









Обсуждение, отзывы о книге «Smarter Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.