José Antonio Castillo Romero - Big data. IFCT128PO
Здесь есть возможность читать онлайн «José Antonio Castillo Romero - Big data. IFCT128PO» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Big data. IFCT128PO
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Big data. IFCT128PO: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Big data. IFCT128PO»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Big data. IFCT128PO — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Big data. IFCT128PO», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Un ejemplo claro del nuevo escenario que abrió el World Wide Web lo tenemos en Googleque logró implantar con éxito su novedoso algoritmo Page-Rank,el cual era capaz de analizar datos de multitud de sitios web.
Ya existían en la época algoritmos capaces de procesar grandes volúmenes de datos de forma paralela, usando para ello grandes máquinas de análisis con varios núcleosen conjuntos o clusters (High Performance Computing o HPC). Pero en el caso de Google, con PageRank optó por una estrategia distinta: implantar un conjunto de máquinas de menor tamaño y menor capacidad de procesamiento.
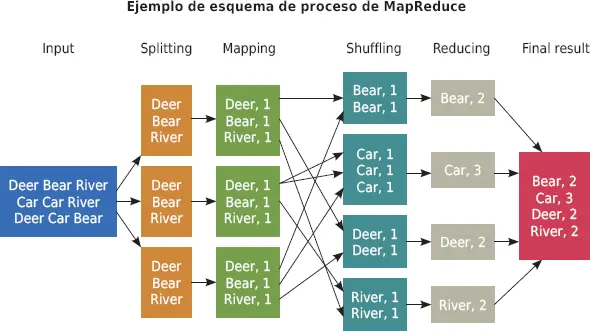
Esta solución se basa en dos elementos.Por un lado, la existencia de un sistema de ficheros distribuidospara la gestión del almacenamiento de los datos de manera segmentada y, además, replicada entre las distintas máquinas. Por otro lado, un software que tiene implementadas las diferentes tareas para cada máquina.Este software permitía una más fácil implementación de nuevos programas que trabajaran con los datos. A este modelo se le llamó MapReduce.
Función Map
Transforma los datos brutos en datos intermedios transformados en claves y valor que se agrupan según la misma clave.
Función Reduce
Agrupa los valores de los datos sumándolos y se produce el resultado final.
4.2. Desarrollo de las tecnologías del big data
Gracias a la creación de MapReduce se han implementado más soluciones basadas en este para crear motores de búsquedaa nivel global como Yahoo,y de esta forma se llegó a implementar un sistema semejante, pero en software librecon código abierto, denominado Apache Hadoop.Tras la creación de este, y gracias a ser de acceso libre, se crearon multitud de herramientas adiciones que potenciaron la funcionalidad del big data.
 DEFINICIÓN
DEFINICIÓN
Apache Hadoop
Es un entorno de trabajo de licencia libre inspirado en el MapReduce de Google, que permite a diferentes aplicaciones trabajar con grandes volúmenes de datos.
En los siguientes años se fueron desarrollando estas tecnologías paralelamente por parte de Google con NoSQL, un sistema de almacenamiento de datos, también de forma libre.
DEFINICIÓN
NoSQL
Es un tipo de sistema de gestión de base de datos, que no solo usa el SQLcomo lenguaje de consultas para bases de datos, sino también otros existentes, de ahí el nombre NoSQLo No solo SQL.
Después surgió la Web 2.0, donde usuarios de todo el mundo interactuaban en redes sociales y creaban contenido en forma de streams o flujos,en los cuales era necesario procesar y distribuir los datos en tiempo real. Así fue como se fue expandiendo cada vez en mayor medida el big data.
Y finalmente llegamos a la actualidad, donde gracias al software libre y al abaratamiento de las tecnologíasde computación, ha sido posible que usuarios normales tangan acceso al cloud computing o computación en la nube,en la cual se alquilan máquinas de forma remota para hacer uso de ellas y llegar a la era del internet de las cosas,donde se crean todo tipo de dispositivos capaces de crear y compartir contenido ni necesidad de enlaces físicos, llevando así a una nueva dimensión: el big data.
 TAREA 1
TAREA 1
Imagina que eres el dueño de una empresa de venta de moda textil creada en 1970. Gracias a tu excelente dirección y a la de tus socios, has mantenido tu empresa a la vanguardia en tecnología, consiguiendo con ello expandirte y optimizar todas las áreas de negocios.
Realiza un documento donde cuentes de forma cronológica la trayectoria que ha seguido tu empresa en la implementación de sistemas de análisis de datos hasta el día de hoy para conocer la razón del éxito de tu negocio.
5. Resumen
Los antecedentesdel big data comenzaron en los albores de nuestro tiempo:
Edad antigua: uso de aparatos mecánicos. Abaco, Anticitera.
Siglo XVII: John Graunt crea la estadística.
Siglo XIX: primeras computadoras. Se habla de business intelligence.
Siglo XX: era de la información, aparece el big data.
Siglo XXI: internet de las cosas, creamos más datos en un día que en 1.000 años.
La información aplicada a los negocios hace obtener una ventaja competitiva en las organizaciones, nace el Business Intelligence y con él un mundo de posibilidades, donde las organizaciones evolucionan rápidamente hacia una era marcada por los datos y su importancia.
1958: Peter Luhn define el BI.
Se crean las bases de datos. Nace el data warehouse.
Evoluciona el análisis de datos: nace el data mining para estudiar el futuro a través de los datos.
Surge el machine learning: las máquinas son las protagonistas.
Desarrollo de profesionales: los científicos de datos y la ciencia de los datos.
El big data y las diferentes formas de entenderlo. Has aprendido la terminología más utilizada relacionada con este concepto y has establecido las bases para el entendimiento del big data.
El big data nace como necesidad para las grandes empresas tecnológicas de los años noventa.
Google y su novedoso MapReduce: divide y vencerás.
Nace el software libre con Apache Hadoop, alternativa gratuita a MapReduce.
Invención de la Web 2.0: todos creamos datos masivamente. Nace el big data.
Ejercicios de autoevaluación
Unidad de Aprendizaje 1
1. ¿Quién definió por primera vez el término business intelligence ?
a. Richard Millar Devens, en 1958.
b. Hans Peter Luhn, en 1958.
c. Richard Millar Devens, en 1865.
d. Hans Peter Luhn, en 1865.
2. La implantación del business intelligence en una empresa dota a esta de conocimiento útil para una mejor toma de decisiones. Pero, ¿qué tipo de análisis hace de los datos?
a. Descriptivo.
b. Predictivo.
c. Predictivo y descriptivo.
d. El análisis debe realizarlo el científico de datos.
3. Determina si las siguientes oraciones son verdaderas o falsas:
a. El data mining aporta a la organización un análisis descriptivo de los datos para saber el pasado y el presente de esta.
1 Verdadero
2 Falso
b. El data mining es una evolución del business intelligence tradicional.
1 Verdadero
2 Falso
c. El data mining aporta a la organización información a través del estudio de patrones y modelos para predecir resultados.
1 Verdadero
2 Falso
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Big data. IFCT128PO»
Представляем Вашему вниманию похожие книги на «Big data. IFCT128PO» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Big data. IFCT128PO» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.