Seifedine Kadry - Big Data
Здесь есть возможность читать онлайн «Seifedine Kadry - Big Data» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Big Data
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Big Data: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Big Data»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Big Data Accessibly organized,
includes illuminating case studies throughout the material, showing you how the included concepts have been applied in real-world settings. Some of those concepts include:
The common challenges facing big data technology and technologists, like data heterogeneity and incompleteness, data volume and velocity, storage limitations, and privacy concerns Relational and non-relational databases, like RDBMS, NoSQL, and NewSQL databases Virtualizing Big Data through encapsulation, partitioning, and isolating, as well as big data server virtualization Apache software, including Hadoop, Cassandra, Avro, Pig, Mahout, Oozie, and Hive The Big Data analytics lifecycle, including business case evaluation, data preparation, extraction, transformation, analysis, and visualization Perfect for data scientists, data engineers, and database managers,
also belongs on the bookshelves of business intelligence analysts who are required to make decisions based on large volumes of information. Executives and managers who lead teams responsible for keeping or understanding large datasets will also benefit from this book.
Big Data — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Big Data», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2.2.2.1 Master‐Slave Model
Master‐slave configuration is a model where one centralized device known as the master controls one or more devices known as slaves. In a master‐slave configuration a replica set constitutes a master node and several slave nodes. Once the relationship between master and slave is established, the flow of control is only from master to the slaves. In master‐slave replication, all the incoming data are written on the master node, and the same data is replicated over several slave nodes. All the write requests are handled by the master node, and the data update, insert, or delete occurs in the master node, while the read requests are handled by slave nodes. This architecture supports intensive read requests as the increasing demands can be handled by appending additional slave nodes. If a master node fails, write requests cannot be fulfilled until the master node is resumed or a new master node is created from one of the slave nodes. Figure 2.9shows data replication in a master‐slave configuration.
2.2.2.2 Peer‐to‐Peer Model
In the master‐slave model only the slaves are guaranteed against single point of failure. The cluster still suffers from single point of failure, if the master fails. Also, the writes are limited to the maximum capacity that a master can handle; hence, it provides only read scalability. These drawbacks in the master‐slave model are overcome in the peer‐to‐peer model. In a peer‐to‐peer configuration there is no master‐slave concept, all the nodes have the same responsibility and are at the same level. The nodes in a peer‐to‐peer configuration act both as client and the server. In the master‐slave model, communication is always initiated by the master, whereas in a peer‐to‐peer configuration, either of the devices involved in the process can initiate communication. Figure 2.10shows replication in the peer‐to‐peer model.
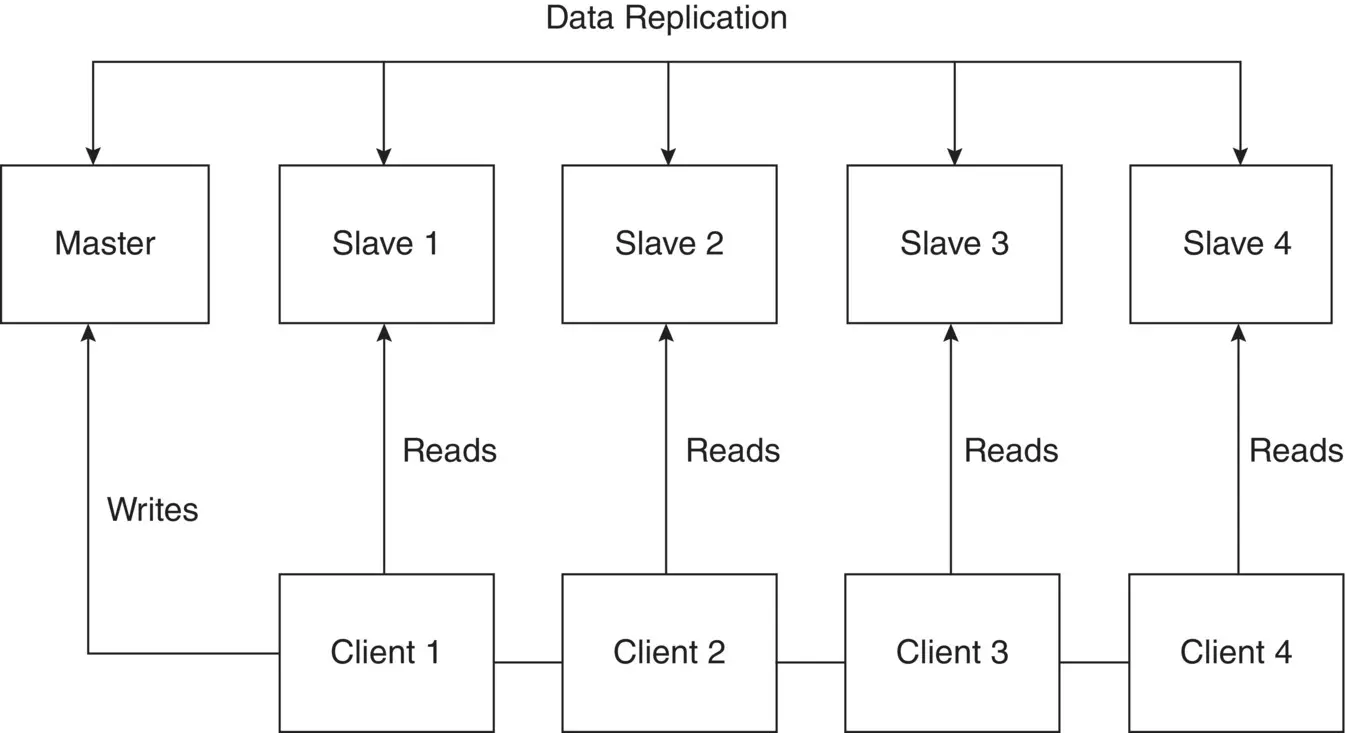
Figure 2.9 Master‐Slave model.
In the peer‐to‐peer model the workload or the task is partitioned among the nodes. The nodes consume as well as donate the resources. Resources such as disk storage space, memory, bandwidth, processing power, and so forth, are shared among the nodes.
Reliability of this type of configuration is improved through replication. Replication is the process of sharing the same data across multiple nodes to avoid single point of failure. Also, the nodes connected in a peer‐to‐peer configuration are geographically distributed across the globe.
2.2.3 Sharding and Replication
In sharding when a node goes down, the data stored in the node will be lost. So it provides only a limited fault tolerance to the system. Sharding and replication can be combined to make the system fault tolerant and highly available. Figure 2.11illustrates the combination of sharding and replication where the data set is split up into shard A and shard B. Shard A is replicated across node A and node B; similarly shard B is replicated across node C and node D.
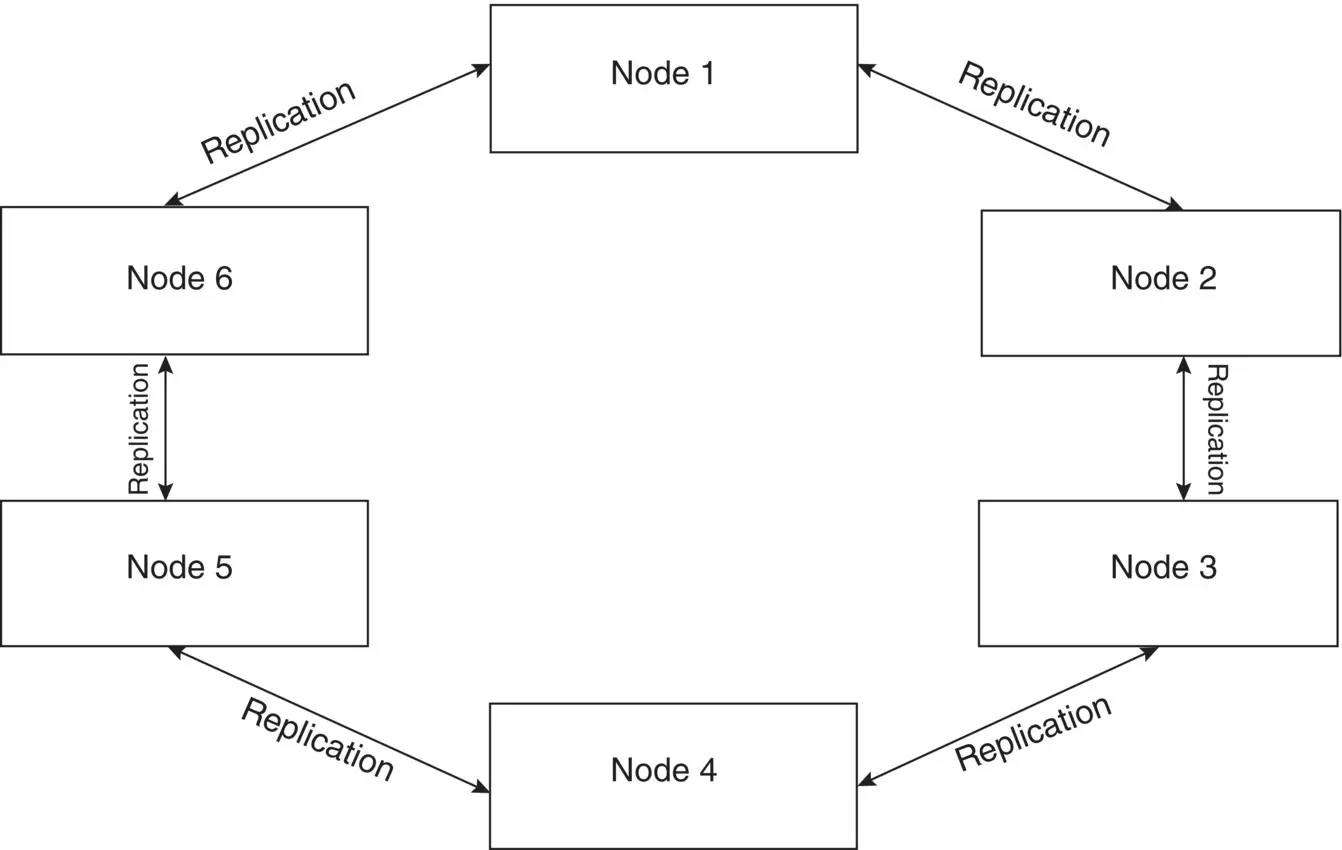
Figure 2.10 Peer‐to‐peer model.
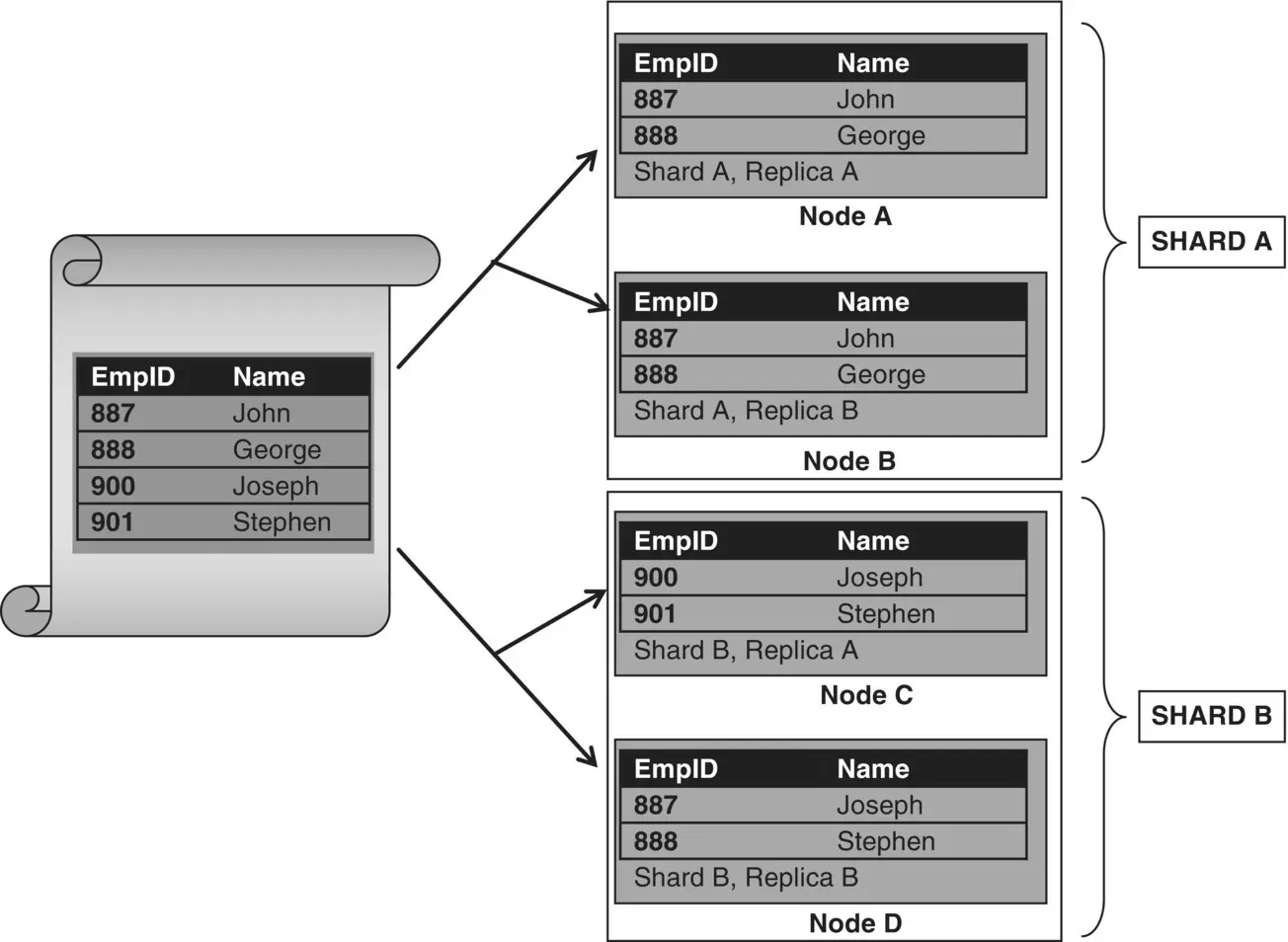
Figure 2.11 Combination of sharding and replication.
2.3 Distributed File System
A file system is a way of storing and organizing the data on storage devices such as hard drives, DVDs, and so forth, and to keep track of the files stored on them. The file is the smallest unit of storage defined by the file system to pile the data. These file systems store and retrieve data for the application to run effectively and efficiently on the operating systems. A distributed file system stores the files across cluster nodes and allows the clients to access the files from the cluster. Though physically the files are distributed across the nodes, logically it appears to the client as if the files are residing on their local machine. Since a distributed file system provides access to more than one client simultaneously, the server has a mechanism to organize updates for the clients to access the current updated version of the file, and no version conflicts arise. Big data widely adopts a distributed file system known as Hadoop Distributed File System (HDFS).
The key concept of a distributed file system is the data replication where the copies of data called replicas are distributed on multiple cluster nodes so that there is no single point of failure, which increases the reliability. The client can communicate with any of the closest available nodes to reduce latency and network traffic. Fault tolerance is achieved through data replication as the data will not be lost in case of node failure due to the redundancy in the data across nodes.
2.4 Relational and Non‐Relational Databases
Relational databases organize data into tables of rows and columns. The rows are called records, and the columns are called attributes or fields. A database with only one table is called a flat database, while a database with two or more tables that are related is called a relational database. Table 2.1shows a simple table that stores the details of the students registering for the courses offered by an institution.
In the above example, the table holds the details of the students and CourseId of the courses for which the students have registered. The above table meets the basic needs to keep track of the courses for which each student has registered. But it has some serious flaws in accordance with efficiency and space utilization. For example, when a student registers for more than one course, then details of the student has to be entered for every course he registers. This can be overcome by dividing the data across multiple related tables. Figure 2.12represents the data in the above table is divided among multiple related tables with unique primary and foreign keys.
Relational tables have attributes that uniquely identify each row. The attributes which uniquely identify the tuples are called primary key. StudentId is the primary key, and hence its value should be unique. Attribute in one table that references to the primary key in another table is called foreign key. CourseId in RegisteredCourse is a foreign key, which references to CourseId in the CoursesOffered table.
Table 2.1 Student course registration database.
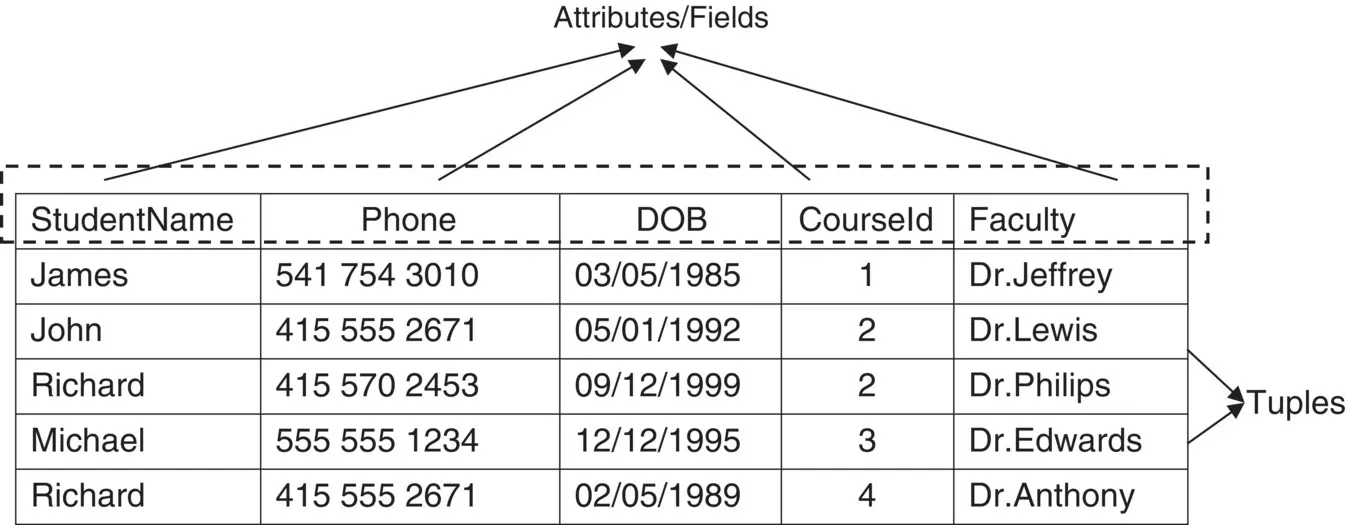
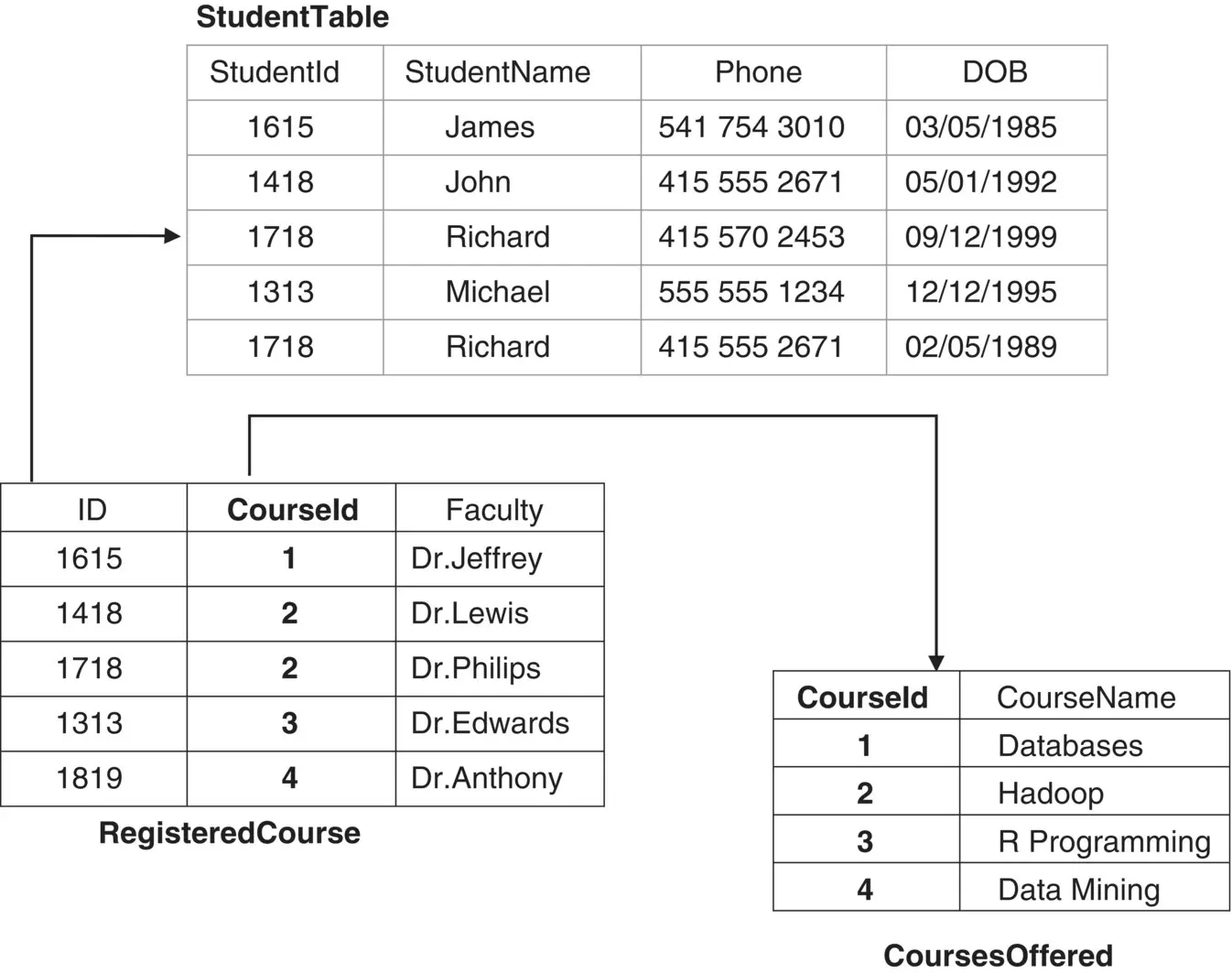
Figure 2.12 Data divided across multiple related tables.
Relational databases become unsuitable when organizations collect vast amount of customer databases, transactions, and other data, which may not be structured to fit into relational databases. This has led to the evolution of non‐relational databases, which are schema‐less. NoSQL is a non‐relational database and a few frequently used NoSQL databases are Neo4J, Redis, Cassandra, and MongoDb. Let us have a quick look at the properties of RDBMS and NoSQL databases.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Big Data»
Представляем Вашему вниманию похожие книги на «Big Data» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.



![Алексей Благирев - Big data простым языком [litres]](/books/416853/aleksej-blagirev-big-data-prostym-yazykom-litres-thumb.webp)








Обсуждение, отзывы о книге «Big Data» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.